 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Hyperbolic Representation Learning for Heterogeneous Graphs
Jun 14, 2024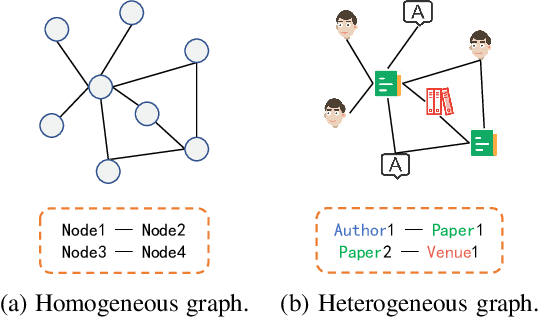
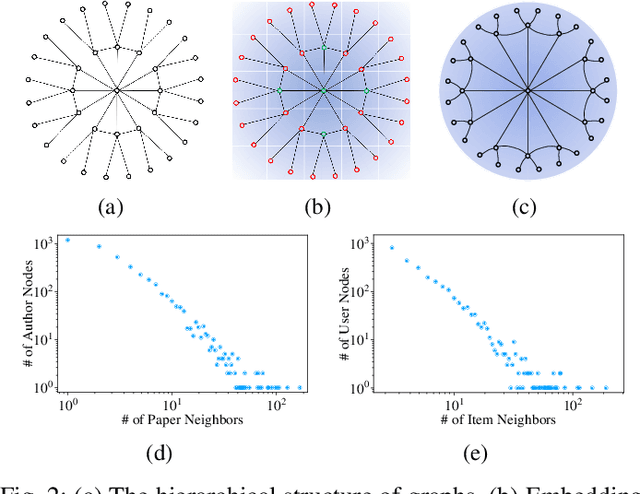
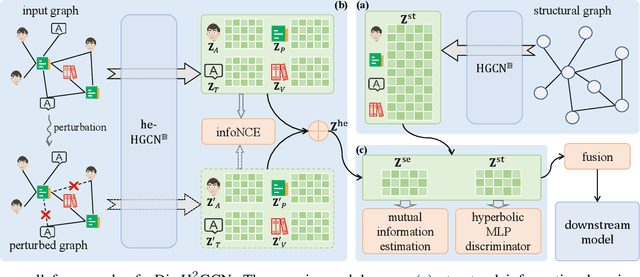
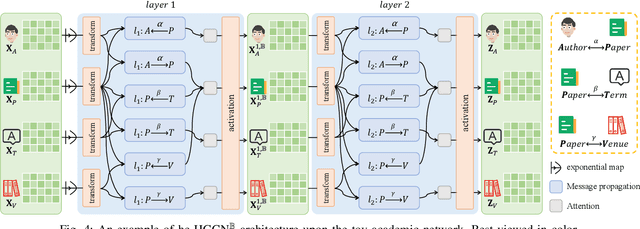
Heterogeneous graphs have attracted a lot of research interests recently due to the success for representing complex real-world systems. However, existing methods have two pain points in embedding them into low-dimensional spaces: the mixing of structural and semantic information, and the distributional mismatch between data and embedding spaces. These two challenges require representation methods to consider the global and partial data distributions while unmixing the information. Therefore, in this paper, we propose $\text{Dis-H}^2\text{GCN}$, a Disentangled Hyperbolic Heterogeneous Graph Convolutional Network. On the one hand, we leverage the mutual information minimization and discrimination maximization constraints to disentangle the semantic features from comprehensively learned representations by independent message propagation for each edge type, away from the pure structural features. On the other hand, the entire model is constructed upon the hyperbolic geometry to narrow the gap between data distributions and representing spaces. We evaluate our proposed $\text{Dis-H}^2\text{GCN}$ on five real-world heterogeneous graph datasets across two downstream tasks: node classification and link prediction. The results demonstrate its superiority over state-of-the-art methods, showcasing the effectiveness of our method in disentangling and representing heterogeneous graph data in hyperbolic spaces.
Multi-view Graph Structural Representation Learning via Graph Coarsening
Apr 18, 2024Graph Transformers (GTs) have made remarkable achievements in graph-level tasks. However, most existing works regard graph structures as a form of guidance or bias for enhancing node representations, which focuses on node-central perspectives and lacks explicit representations of edges and structures. One natural question is, can we treat graph structures node-like as a whole to learn high-level features? Through experimental analysis, we explore the feasibility of this assumption. Based on our findings, we propose a novel multi-view graph structural representation learning model via graph coarsening (MSLgo) on GT architecture for graph classification. Specifically, we build three unique views, original, coarsening, and conversion, to learn a thorough structural representation. We compress loops and cliques via hierarchical heuristic graph coarsening and restrict them with well-designed constraints, which builds the coarsening view to learn high-level interactions between structures. We also introduce line graphs for edge embeddings and switch to edge-central perspective to construct the conversion view. Experiments on six real-world datasets demonstrate the improvements of MSLgo over 14 baselines from various architectures.
In the Blink of an Eye: Event-based Emotion Recognition
Oct 06, 2023



We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 dB) and a higher temporal resolution. Thus, the captured events can encode rich temporal cues under challenging lighting conditions. However, these events lack texture information, posing problems in decoding temporal information effectively. SEEN tackles this issue from two different perspectives. First, we adopt convolutional spiking layers to take advantage of the spiking neural network's ability to decode pertinent temporal information. Second, SEEN learns to extract essential spatial cues from corresponding intensity frames and leverages a novel weight-copy scheme to convey spatial attention to the convolutional spiking layers during training and inference. We extensively validate and demonstrate the effectiveness of our approach on a specially collected Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first eye-based emotion recognition method that leverages event-based cameras and spiking neural network.
From Alignment to Entailment: A Unified Textual Entailment Framework for Entity Alignment
May 19, 2023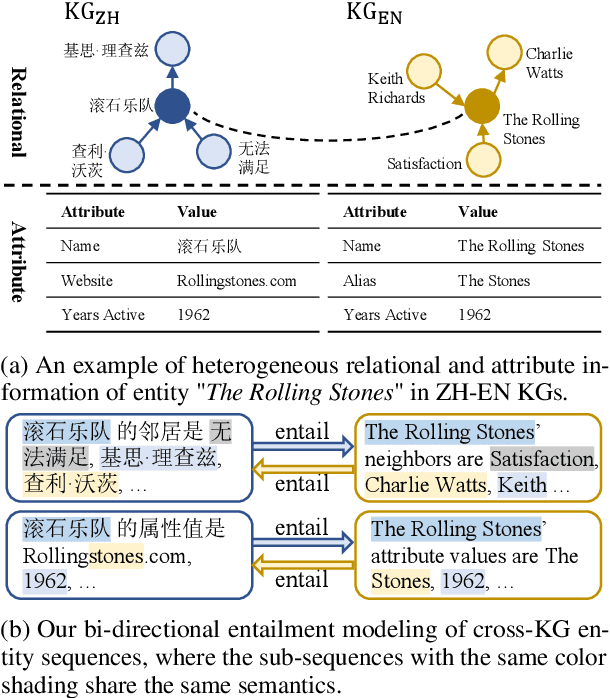
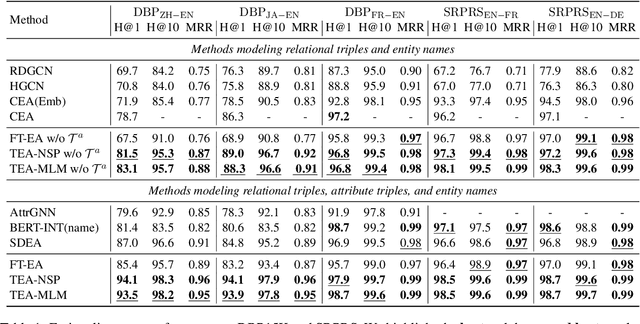
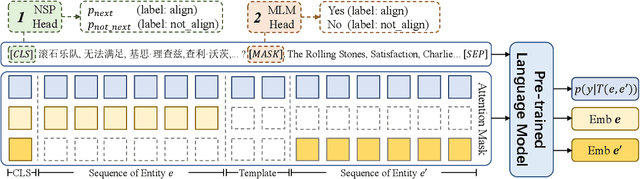
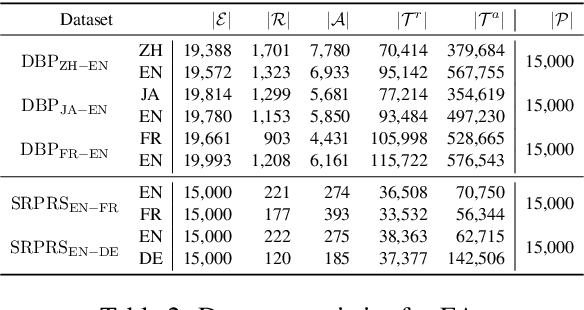
Entity Alignment (EA) aims to find the equivalent entities between two Knowledge Graphs (KGs). Existing methods usually encode the triples of entities as embeddings and learn to align the embeddings, which prevents the direct interaction between the original information of the cross-KG entities. Moreover, they encode the relational triples and attribute triples of an entity in heterogeneous embedding spaces, which prevents them from helping each other. In this paper, we transform both triples into unified textual sequences, and model the EA task as a bi-directional textual entailment task between the sequences of cross-KG entities. Specifically, we feed the sequences of two entities simultaneously into a pre-trained language model (PLM) and propose two kinds of PLM-based entity aligners that model the entailment probability between sequences as the similarity between entities. Our approach captures the unified correlation pattern of two kinds of information between entities, and explicitly models the fine-grained interaction between original entity information. The experiments on five cross-lingual EA datasets show that our approach outperforms the state-of-the-art EA methods and enables the mutual enhancement of the heterogeneous information. Codes are available at https://github.com/OreOZhao/TEA.
HGWaveNet: A Hyperbolic Graph Neural Network for Temporal Link Prediction
May 03, 2023Temporal link prediction, aiming to predict future edges between paired nodes in a dynamic graph, is of vital importance in diverse applications. However, existing methods are mainly built upon uniform Euclidean space, which has been found to be conflict with the power-law distributions of real-world graphs and unable to represent the hierarchical connections between nodes effectively. With respect to the special data characteristic, hyperbolic geometry offers an ideal alternative due to its exponential expansion property. In this paper, we propose HGWaveNet, a novel hyperbolic graph neural network that fully exploits the fitness between hyperbolic spaces and data distributions for temporal link prediction. Specifically, we design two key modules to learn the spatial topological structures and temporal evolutionary information separately. On the one hand, a hyperbolic diffusion graph convolution (HDGC) module effectively aggregates information from a wider range of neighbors. On the other hand, the internal order of causal correlation between historical states is captured by hyperbolic dilated causal convolution (HDCC) modules. The whole model is built upon the hyperbolic spaces to preserve the hierarchical structural information in the entire data flow. To prove the superiority of HGWaveNet, extensive experiments are conducted on six real-world graph datasets and the results show a relative improvement by up to 6.67% on AUC for temporal link prediction over SOTA methods.
* Accepted by Web Conference (WWW) 2023
H2TNE: Temporal Heterogeneous Information Network Embedding in Hyperbolic Spaces
Apr 18, 2023Temporal heterogeneous information network (temporal HIN) embedding, aiming to represent various types of nodes of different timestamps into low dimensional spaces while preserving structural and semantic information, is of vital importance in diverse real-life tasks. Researchers have made great efforts on temporal HIN embedding in Euclidean spaces and got some considerable achievements. However, there is always a fundamental conflict that many real-world networks show hierarchical property and power-law distribution, and are not isometric of Euclidean spaces. Recently, representation learning in hyperbolic spaces has been proved to be valid for data with hierarchical and power-law structure. Inspired by this character, we propose a hyperbolic heterogeneous temporal network embedding (H2TNE) model for temporal HINs. Specifically, we leverage a temporally and heterogeneously double-constrained random walk strategy to capture the structural and semantic information, and then calculate the embedding by exploiting hyperbolic distance in proximity measurement. Experimental results show that our method has superior performance on temporal link prediction and node classification compared with SOTA models.
MoSE: Modality Split and Ensemble for Multimodal Knowledge Graph Completion
Oct 17, 2022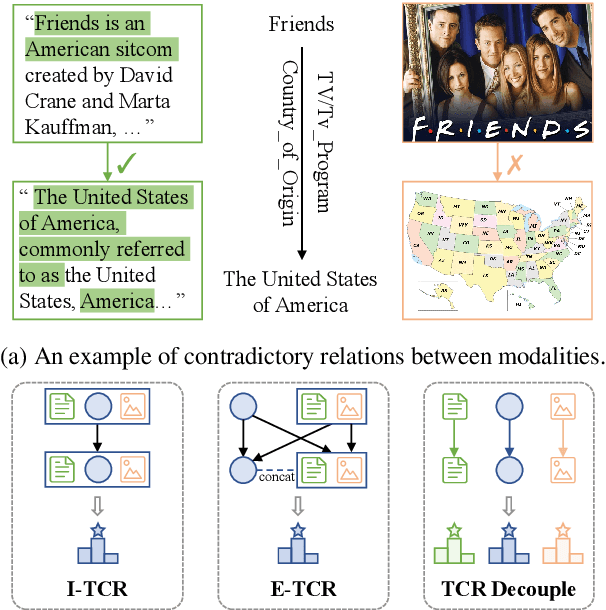
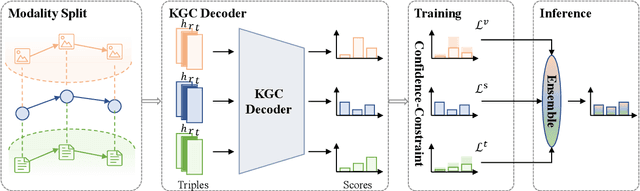
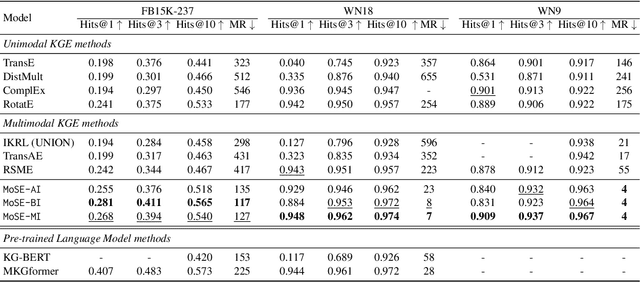
Multimodal knowledge graph completion (MKGC) aims to predict missing entities in MKGs. Previous works usually share relation representation across modalities. This results in mutual interference between modalities during training, since for a pair of entities, the relation from one modality probably contradicts that from another modality. Furthermore, making a unified prediction based on the shared relation representation treats the input in different modalities equally, while their importance to the MKGC task should be different. In this paper, we propose MoSE, a Modality Split representation learning and Ensemble inference framework for MKGC. Specifically, in the training phase, we learn modality-split relation embeddings for each modality instead of a single modality-shared one, which alleviates the modality interference. Based on these embeddings, in the inference phase, we first make modality-split predictions and then exploit various ensemble methods to combine the predictions with different weights, which models the modality importance dynamically. Experimental results on three KG datasets show that MoSE outperforms state-of-the-art MKGC methods. Codes are available at https://github.com/OreOZhao/MoSE4MKGC.