 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom "What" to "How": Constrained Reasoning for Autoregressive Image Generation
Mar 03, 2026Autoregressive image generation has seen recent improvements with the introduction of chain-of-thought and reinforcement learning. However, current methods merely specify "What" details to depict by rewriting the input prompt, yet fundamentally fail to reason about "How" to structure the overall image. This inherent limitation gives rise to persistent issues, such as spatial ambiguity directly causing unrealistic object overlaps. To bridge this gap, we propose CoR-Painter, a novel framework that pioneers a "How-to-What" paradigm by introducing Constrained Reasoning to guide the autoregressive generation. Specifically, it first deduces "How to draw" by deriving a set of visual constraints from the input prompt, which explicitly govern spatial relationships, key attributes, and compositional rules. These constraints steer the subsequent generation of a detailed description "What to draw", providing a structurally sound and coherent basis for accurate visual synthesis. Additionally, we introduce a Dual-Objective GRPO strategy that specifically optimizes the textual constrained reasoning and visual projection processes to ensure the coherence and quality of the entire generation pipeline. Extensive experiments on T2I-CompBench, GenEval, and WISE demonstrate that our method achieves state-of-the-art performance, with significant improvements in spatial metrics (e.g., +5.41% on T2I-CompBench).
EIDOS: Latent-Space Predictive Learning for Time Series Foundation Models
Feb 15, 2026Most time series foundation models are pretrained by directly predicting future observations, which often yields weakly structured latent representations that capture surface noise rather than coherent and predictable temporal dynamics. In this work, we introduce EIDOS, a foundation model family that shifts pretraining from future value prediction to latent-space predictive learning. We train a causal Transformer to predict the evolution of latent representations, encouraging the emergence of structured and temporally coherent latent states. To ensure stable targets for latent-space learning, we design a lightweight aggregation branch to construct target representations. EIDOS is optimized via a joint objective that integrates latent-space alignment, observational grounding to anchor representations to the input signal, and direct forecasting supervision. On the GIFT-Eval benchmark, EIDOS mitigates structural fragmentation in the representation space and achieves state-of-the-art performance. These results demonstrate that constraining models to learn predictable latent dynamics is a principled step toward more robust and reliable time series foundation models.
Plan of Knowledge: Retrieval-Augmented Large Language Models for Temporal Knowledge Graph Question Answering
Nov 06, 2025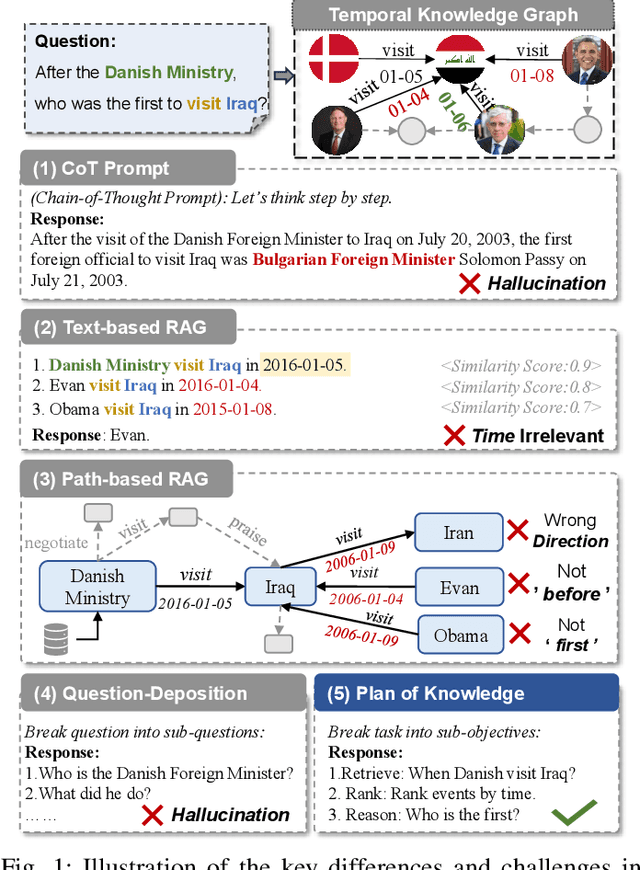
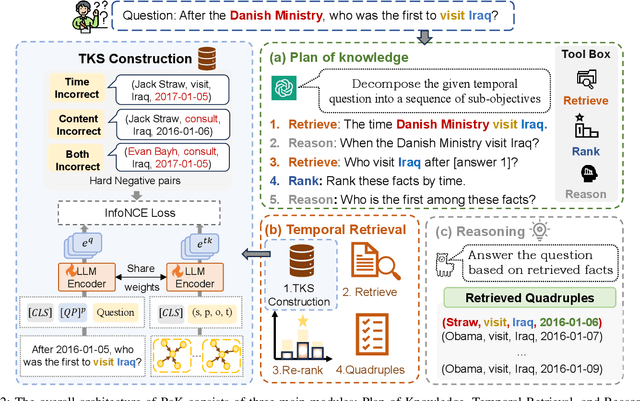
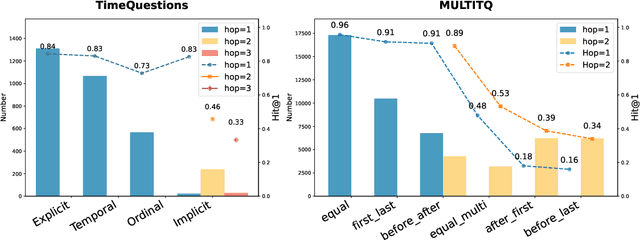
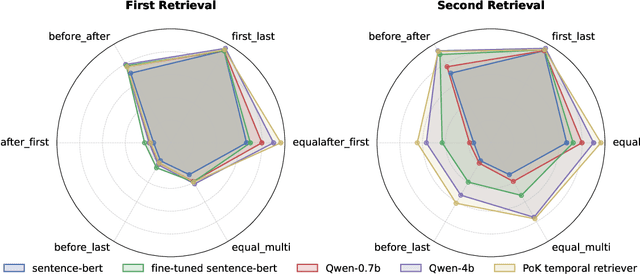
Temporal Knowledge Graph Question Answering (TKGQA) aims to answer time-sensitive questions by leveraging factual information from Temporal Knowledge Graphs (TKGs). While previous studies have employed pre-trained TKG embeddings or graph neural networks to inject temporal knowledge, they fail to fully understand the complex semantic information of time constraints. Recently, Large Language Models (LLMs) have shown remarkable progress, benefiting from their strong semantic understanding and reasoning generalization capabilities. However, their temporal reasoning ability remains limited. LLMs frequently suffer from hallucination and a lack of knowledge. To address these limitations, we propose the Plan of Knowledge framework with a contrastive temporal retriever, which is named PoK. Specifically, the proposed Plan of Knowledge module decomposes a complex temporal question into a sequence of sub-objectives from the pre-defined tools, serving as intermediate guidance for reasoning exploration. In parallel, we construct a Temporal Knowledge Store (TKS) with a contrastive retrieval framework, enabling the model to selectively retrieve semantically and temporally aligned facts from TKGs. By combining structured planning with temporal knowledge retrieval, PoK effectively enhances the interpretability and factual consistency of temporal reasoning. Extensive experiments on four benchmark TKGQA datasets demonstrate that PoK significantly improves the retrieval precision and reasoning accuracy of LLMs, surpassing the performance of the state-of-the-art TKGQA methods by 56.0% at most.
SafeInt: Shielding Large Language Models from Jailbreak Attacks via Safety-Aware Representation Intervention
Feb 21, 2025With the widespread real-world deployment of large language models (LLMs), ensuring their behavior complies with safety standards has become crucial. Jailbreak attacks exploit vulnerabilities in LLMs to induce undesirable behavior, posing a significant threat to LLM safety. Previous defenses often fail to achieve both effectiveness and efficiency simultaneously. Defenses from a representation perspective offer new insights, but existing interventions cannot dynamically adjust representations based on the harmfulness of the queries. To address this limitation while ensuring both effectiveness and efficiency, we propose SafeIntervention (SafeInt), a novel defense method that shields LLMs from jailbreak attacks through safety-aware representation intervention. SafeInt is built on our analysis of the representations of jailbreak samples. It adjusts representation distributions of jailbreak samples through intervention to align them with the representations of unsafe samples while minimizing unnecessary perturbations to jailbreak-irrelevant representations. We conduct comprehensive experiments covering six jailbreak attacks, two jailbreak datasets, and two utility benchmarks. Experimental results demonstrate that SafeInt outperforms all baselines in defending LLMs against jailbreak attacks while largely maintaining utility. Additionally, we evaluate SafeInt against adaptive attacks and verify its effectiveness in mitigating real-time attacks.
Graph Structure Learning for Spatial-Temporal Imputation: Adapting to Node and Feature Scales
Dec 24, 2024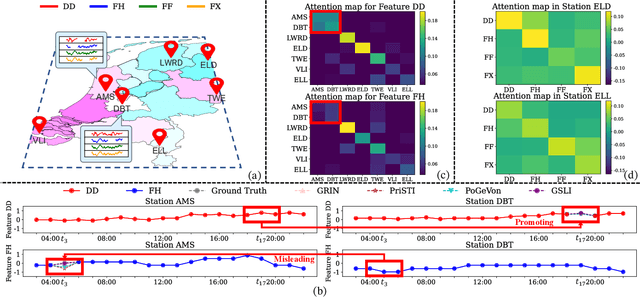
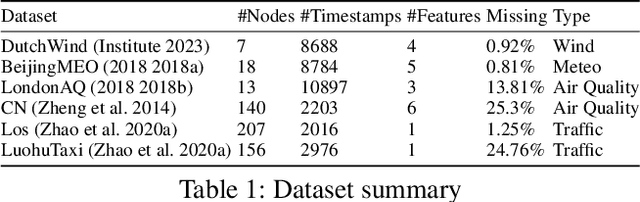
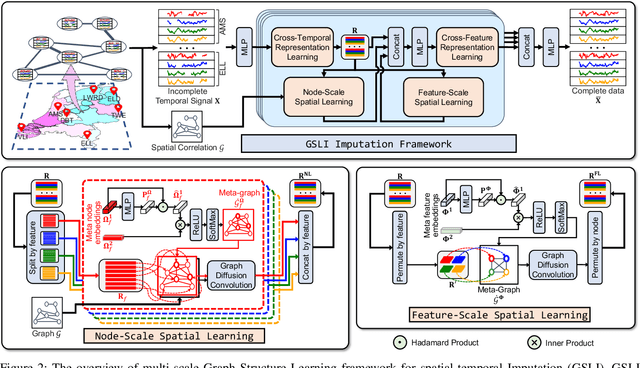
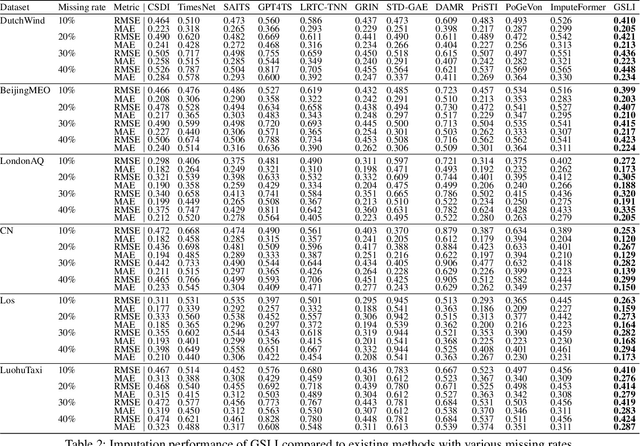
Spatial-temporal data collected across different geographic locations often suffer from missing values, posing challenges to data analysis. Existing methods primarily leverage fixed spatial graphs to impute missing values, which implicitly assume that the spatial relationship is roughly the same for all features across different locations. However, they may overlook the different spatial relationships of diverse features recorded by sensors in different locations. To address this, we introduce the multi-scale Graph Structure Learning framework for spatial-temporal Imputation (GSLI) that dynamically adapts to the heterogeneous spatial correlations. Our framework encompasses node-scale graph structure learning to cater to the distinct global spatial correlations of different features, and feature-scale graph structure learning to unveil common spatial correlation across features within all stations. Integrated with prominence modeling, our framework emphasizes nodes and features with greater significance in the imputation process. Furthermore, GSLI incorporates cross-feature and cross-temporal representation learning to capture spatial-temporal dependencies. Evaluated on six real incomplete spatial-temporal datasets, GSLI showcases the improvement in data imputation.
EffiCANet: Efficient Time Series Forecasting with Convolutional Attention
Nov 07, 2024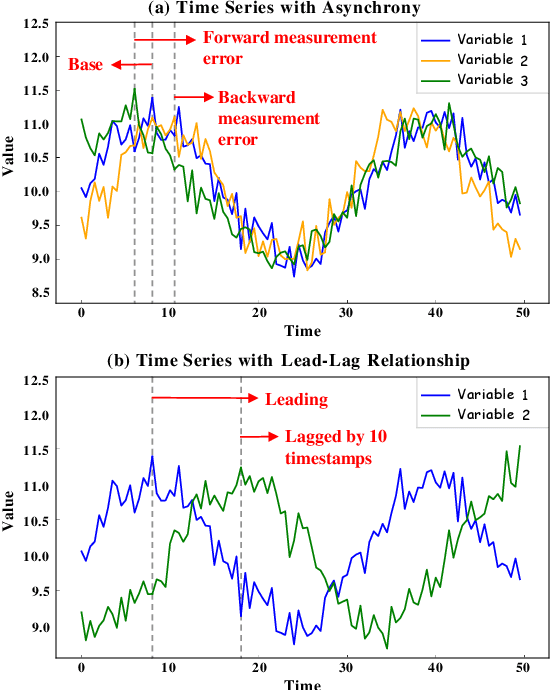
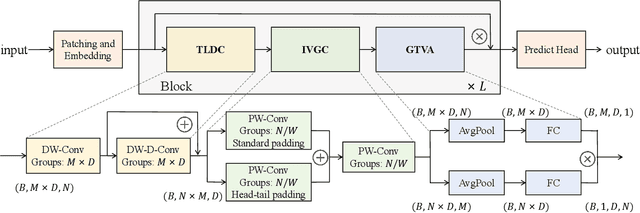

The exponential growth of multivariate time series data from sensor networks in domains like industrial monitoring and smart cities requires efficient and accurate forecasting models. Current deep learning methods often fail to adequately capture long-range dependencies and complex inter-variable relationships, especially under real-time processing constraints. These limitations arise as many models are optimized for either short-term forecasting with limited receptive fields or long-term accuracy at the cost of efficiency. Additionally, dynamic and intricate interactions between variables in real-world data further complicate modeling efforts. To address these limitations, we propose EffiCANet, an Efficient Convolutional Attention Network designed to enhance forecasting accuracy while maintaining computational efficiency. EffiCANet integrates three key components: (1) a Temporal Large-kernel Decomposed Convolution (TLDC) module that captures long-term temporal dependencies while reducing computational overhead; (2) an Inter-Variable Group Convolution (IVGC) module that captures complex and evolving relationships among variables; and (3) a Global Temporal-Variable Attention (GTVA) mechanism that prioritizes critical temporal and inter-variable features. Extensive evaluations across nine benchmark datasets show that EffiCANet achieves the maximum reduction of 10.02% in MAE over state-of-the-art models, while cutting computational costs by 26.2% relative to conventional large-kernel convolution methods, thanks to its efficient decomposition strategy.
Towards Universal Large-Scale Foundational Model for Natural Gas Demand Forecasting
Sep 24, 2024



In the context of global energy strategy, accurate natural gas demand forecasting is crucial for ensuring efficient resource allocation and operational planning. Traditional forecasting methods struggle to cope with the growing complexity and variability of gas consumption patterns across diverse industries and commercial sectors. To address these challenges, we propose the first foundation model specifically tailored for natural gas demand forecasting. Foundation models, known for their ability to generalize across tasks and datasets, offer a robust solution to the limitations of traditional methods, such as the need for separate models for different customer segments and their limited generalization capabilities. Our approach leverages contrastive learning to improve prediction accuracy in real-world scenarios, particularly by tackling issues such as noise in historical consumption data and the potential misclassification of similar data samples, which can lead to degradation in the quaility of the representation and thus the accuracy of downstream forecasting tasks. By integrating advanced noise filtering techniques within the contrastive learning framework, our model enhances the quality of learned representations, leading to more accurate predictions. Furthermore, the model undergoes industry-specific fine-tuning during pretraining, enabling it to better capture the unique characteristics of gas consumption across various sectors. We conducted extensive experiments using a large-scale dataset from ENN Group, which includes data from over 10,000 industrial, commercial, and welfare-related customers across multiple regions. Our model outperformed existing state-of-the-art methods, demonstrating a relative improvement in MSE by 3.68\% and in MASE by 6.15\% compared to the best available model.
Graffin: Stand for Tails in Imbalanced Node Classification
Sep 09, 2024



Graph representation learning (GRL) models have succeeded in many scenarios. Real-world graphs have imbalanced distribution, such as node labels and degrees, which leaves a critical challenge to GRL. Imbalanced inputs can lead to imbalanced outputs. However, most existing works ignore it and assume that the distribution of input graphs is balanced, which cannot align with real situations, resulting in worse model performance on tail data. The domination of head data makes tail data underrepresented when training graph neural networks (GNNs). Thus, we propose Graffin, a pluggable tail data augmentation module, to address the above issues. Inspired by recurrent neural networks (RNNs), Graffin flows head features into tail data through graph serialization techniques to alleviate the imbalance of tail representation. The local and global structures are fused to form the node representation under the combined effect of neighborhood and sequence information, which enriches the semantics of tail data. We validate the performance of Graffin on four real-world datasets in node classification tasks. Results show that Graffin can improve the adaptation to tail data without significantly degrading the overall model performance.
Disentangled Hyperbolic Representation Learning for Heterogeneous Graphs
Jun 14, 2024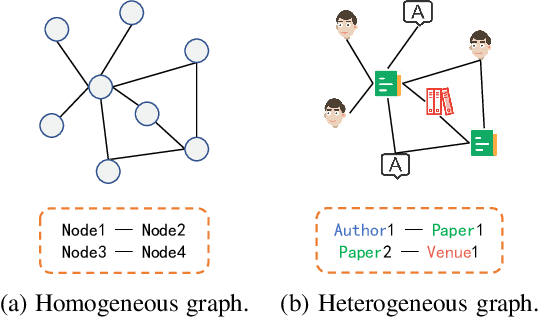
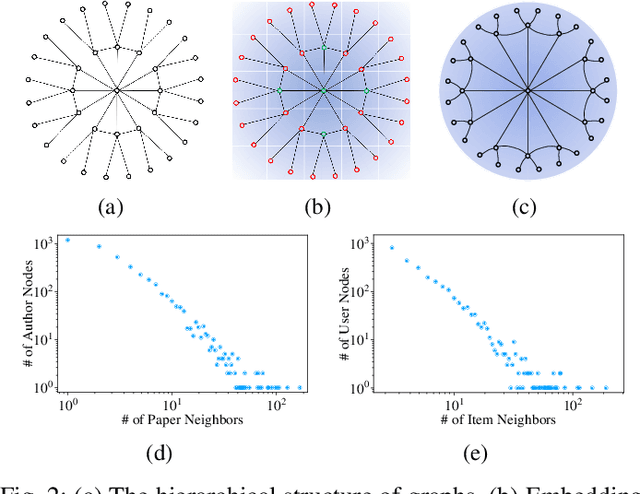
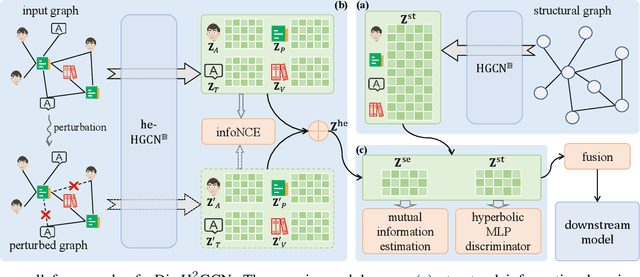
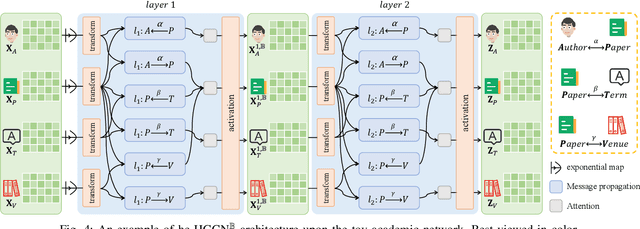
Heterogeneous graphs have attracted a lot of research interests recently due to the success for representing complex real-world systems. However, existing methods have two pain points in embedding them into low-dimensional spaces: the mixing of structural and semantic information, and the distributional mismatch between data and embedding spaces. These two challenges require representation methods to consider the global and partial data distributions while unmixing the information. Therefore, in this paper, we propose $\text{Dis-H}^2\text{GCN}$, a Disentangled Hyperbolic Heterogeneous Graph Convolutional Network. On the one hand, we leverage the mutual information minimization and discrimination maximization constraints to disentangle the semantic features from comprehensively learned representations by independent message propagation for each edge type, away from the pure structural features. On the other hand, the entire model is constructed upon the hyperbolic geometry to narrow the gap between data distributions and representing spaces. We evaluate our proposed $\text{Dis-H}^2\text{GCN}$ on five real-world heterogeneous graph datasets across two downstream tasks: node classification and link prediction. The results demonstrate its superiority over state-of-the-art methods, showcasing the effectiveness of our method in disentangling and representing heterogeneous graph data in hyperbolic spaces.
Multi-view Graph Structural Representation Learning via Graph Coarsening
Apr 18, 2024



Graph Transformers (GTs) have made remarkable achievements in graph-level tasks. However, most existing works regard graph structures as a form of guidance or bias for enhancing node representations, which focuses on node-central perspectives and lacks explicit representations of edges and structures. One natural question is, can we treat graph structures node-like as a whole to learn high-level features? Through experimental analysis, we explore the feasibility of this assumption. Based on our findings, we propose a novel multi-view graph structural representation learning model via graph coarsening (MSLgo) on GT architecture for graph classification. Specifically, we build three unique views, original, coarsening, and conversion, to learn a thorough structural representation. We compress loops and cliques via hierarchical heuristic graph coarsening and restrict them with well-designed constraints, which builds the coarsening view to learn high-level interactions between structures. We also introduce line graphs for edge embeddings and switch to edge-central perspective to construct the conversion view. Experiments on six real-world datasets demonstrate the improvements of MSLgo over 14 baselines from various architectures.