 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAT: Balancing Reasoning Accuracy and Efficiency with Stepwise Adaptive Thinking
Apr 09, 2026Large Reasoning Models (LRMs) have revolutionized complex problem-solving, yet they exhibit a pervasive "overthinking", generating unnecessarily long reasoning chains. While current solutions improve token efficiency, they often sacrifice fine-grained control or risk disrupting the logical integrity of the reasoning process. To address this, we introduce Stepwise Adaptive Thinking (SAT), a framework that performs step-level, difficulty-aware pruning while preserving the core reasoning structure. SAT formulates reasoning as a Finite-State Machine (FSM) with distinct thinking modes (Slow, Normal, Fast, Skip). It navigates these states dynamically using a lightweight Process Reward Model (PRM), compressing easy steps while preserving depth for hard ones. Experiments across 9 LRMs and 7 benchmarks show that SAT achieves up to 40% reduction in reasoning tokens while generally maintaining or improving accuracy.
FlowPrefill: Decoupling Preemption from Prefill Scheduling Granularity to Mitigate Head-of-Line Blocking in LLM Serving
Feb 18, 2026The growing demand for large language models (LLMs) requires serving systems to handle many concurrent requests with diverse service level objectives (SLOs). This exacerbates head-of-line (HoL) blocking during the compute-intensive prefill phase, where long-running requests monopolize resources and delay higher-priority ones, leading to widespread time-to-first-token (TTFT) SLO violations. While chunked prefill enables interruptibility, it introduces an inherent trade-off between responsiveness and throughput: reducing chunk size improves response latency but degrades computational efficiency, whereas increasing chunk size maximizes throughput but exacerbates blocking. This necessitates an adaptive preemption mechanism. However, dynamically balancing execution granularity against scheduling overheads remains a key challenge. In this paper, we propose FlowPrefill, a TTFT-goodput-optimized serving system that resolves this conflict by decoupling preemption granularity from scheduling frequency. To achieve adaptive prefill scheduling, FlowPrefill introduces two key innovations: 1) Operator-Level Preemption, which leverages operator boundaries to enable fine-grained execution interruption without the efficiency loss associated with fixed small chunking; and 2) Event-Driven Scheduling, which triggers scheduling decisions only upon request arrival or completion events, thereby supporting efficient preemption responsiveness while minimizing control-plane overhead. Evaluation on real-world production traces shows that FlowPrefill improves maximum goodput by up to 5.6$\times$ compared to state-of-the-art systems while satisfying heterogeneous SLOs.
AgentRob: From Virtual Forum Agents to Hijacked Physical Robots
Feb 14, 2026Large Language Model (LLM)-powered autonomous agents have demonstrated significant capabilities in virtual environments, yet their integration with the physical world remains narrowly confined to direct control interfaces. We present AgentRob, a framework that bridges online community forums, LLM-powered agents, and physical robots through the Model Context Protocol (MCP). AgentRob enables a novel paradigm where autonomous agents participate in online forums--reading posts, extracting natural language commands, dispatching physical robot actions, and reporting results back to the community. The system comprises three layers: a Forum Layer providing asynchronous, persistent, multi-agent interaction; an Agent Layer with forum agents that poll for @mention-targeted commands; and a Robot Layer with VLM-driven controllers and Unitree Go2/G1 hardware that translate commands into robot primitives via iterative tool calling. The framework supports multiple concurrent agents with distinct identities and physical embodiments coexisting in the same forum, establishing the feasibility of forum-mediated multi-agent robot orchestration.
EST: Towards Efficient Scaling Laws in Click-Through Rate Prediction via Unified Modeling
Feb 11, 2026Efficiently scaling industrial Click-Through Rate (CTR) prediction has recently attracted significant research attention. Existing approaches typically employ early aggregation of user behaviors to maintain efficiency. However, such non-unified or partially unified modeling creates an information bottleneck by discarding fine-grained, token-level signals essential for unlocking scaling gains. In this work, we revisit the fundamental distinctions between CTR prediction and Large Language Models (LLMs), identifying two critical properties: the asymmetry in information density between behavioral and non-behavioral features, and the modality-specific priors of content-rich signals. Accordingly, we propose the Efficiently Scalable Transformer (EST), which achieves fully unified modeling by processing all raw inputs in a single sequence without lossy aggregation. EST integrates two modules: Lightweight Cross-Attention (LCA), which prunes redundant self-interactions to focus on high-impact cross-feature dependencies, and Content Sparse Attention (CSA), which utilizes content similarity to dynamically select high-signal behaviors. Extensive experiments show that EST exhibits a stable and efficient power-law scaling relationship, enabling predictable performance gains with model scale. Deployed on Taobao's display advertising platform, EST significantly outperforms production baselines, delivering a 3.27\% RPM (Revenue Per Mile) increase and a 1.22\% CTR lift, establishing a practical pathway for scalable industrial CTR prediction models.
XLinear: A Lightweight and Accurate MLP-Based Model for Long-Term Time Series Forecasting with Exogenous Inputs
Jan 14, 2026Despite the prevalent assumption of uniform variable importance in long-term time series forecasting models, real world applications often exhibit asymmetric causal relationships and varying data acquisition costs. Specifically, cost-effective exogenous data (e.g., local weather) can unilaterally influence dynamics of endogenous variables, such as lake surface temperature. Exploiting these links enables more effective forecasts when exogenous inputs are readily available. Transformer-based models capture long-range dependencies but incur high computation and suffer from permutation invariance. Patch-based variants improve efficiency yet can miss local temporal patterns. To efficiently exploit informative signals across both the temporal dimension and relevant exogenous variables, this study proposes XLinear, a lightweight time series forecasting model built upon MultiLayer Perceptrons (MLPs). XLinear uses a global token derived from an endogenous variable as a pivotal hub for interacting with exogenous variables, and employs MLPs with sigmoid activation to extract both temporal patterns and variate-wise dependencies. Its prediction head then integrates these signals to forecast the endogenous series. We evaluate XLinear on seven standard benchmarks and five real-world datasets with exogenous inputs. Compared with state-of-the-art models, XLinear delivers superior accuracy and efficiency for both multivariate forecasts and univariate forecasts influenced by exogenous inputs.
Frequent subgraph-based persistent homology for graph classification
Dec 31, 2025Persistent homology (PH) has recently emerged as a powerful tool for extracting topological features. Integrating PH into machine learning and deep learning models enhances topology awareness and interpretability. However, most PH methods on graphs rely on a limited set of filtrations, such as degree-based or weight-based filtrations, which overlook richer features like recurring information across the dataset and thus restrict expressive power. In this work, we propose a novel graph filtration called Frequent Subgraph Filtration (FSF), which is derived from frequent subgraphs and produces stable and information-rich frequency-based persistent homology (FPH) features. We study the theoretical properties of FSF and provide both proofs and experimental validation. Beyond persistent homology itself, we introduce two approaches for graph classification: an FPH-based machine learning model (FPH-ML) and a hybrid framework that integrates FPH with graph neural networks (FPH-GNNs) to enhance topology-aware graph representation learning. Our frameworks bridge frequent subgraph mining and topological data analysis, offering a new perspective on topology-aware feature extraction. Experimental results show that FPH-ML achieves competitive or superior accuracy compared with kernel-based and degree-based filtration methods. When integrated into graph neural networks, FPH yields relative performance gains ranging from 0.4 to 21 percent, with improvements of up to 8.2 percentage points over GCN and GIN backbones across benchmarks.
LoFT-LLM: Low-Frequency Time-Series Forecasting with Large Language Models
Dec 23, 2025Time-series forecasting in real-world applications such as finance and energy often faces challenges due to limited training data and complex, noisy temporal dynamics. Existing deep forecasting models typically supervise predictions using full-length temporal windows, which include substantial high-frequency noise and obscure long-term trends. Moreover, auxiliary variables containing rich domain-specific information are often underutilized, especially in few-shot settings. To address these challenges, we propose LoFT-LLM, a frequency-aware forecasting pipeline that integrates low-frequency learning with semantic calibration via a large language model (LLM). Firstly, a Patch Low-Frequency forecasting Module (PLFM) extracts stable low-frequency trends from localized spectral patches. Secondly, a residual learner then models high-frequency variations. Finally, a fine-tuned LLM refines the predictions by incorporating auxiliary context and domain knowledge through structured natural language prompts. Extensive experiments on financial and energy datasets demonstrate that LoFT-LLM significantly outperforms strong baselines under both full-data and few-shot regimes, delivering superior accuracy, robustness, and interpretability.
SwiftTS: A Swift Selection Framework for Time Series Pre-trained Models via Multi-task Meta-Learning
Oct 27, 2025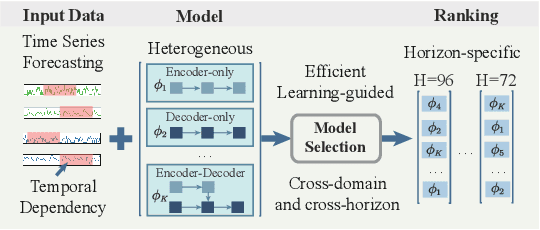
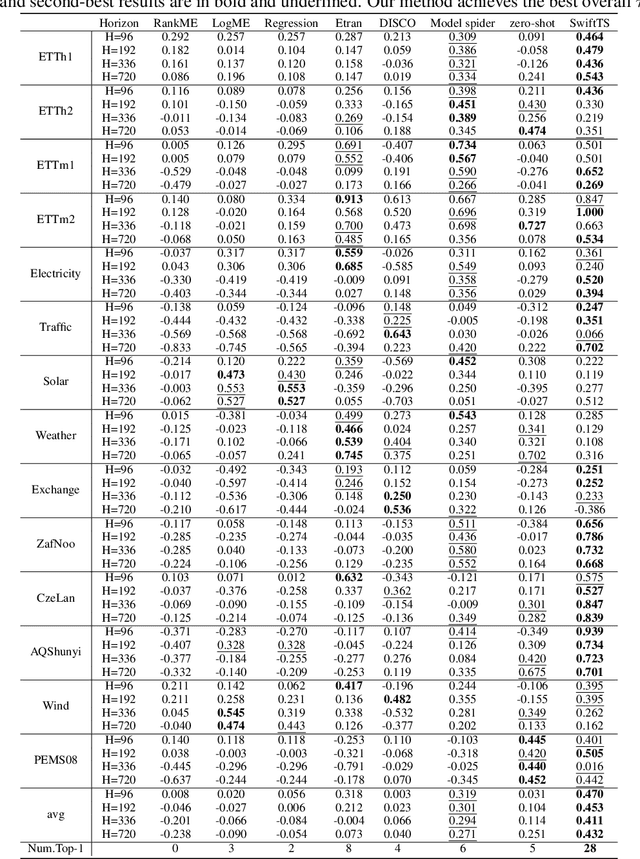
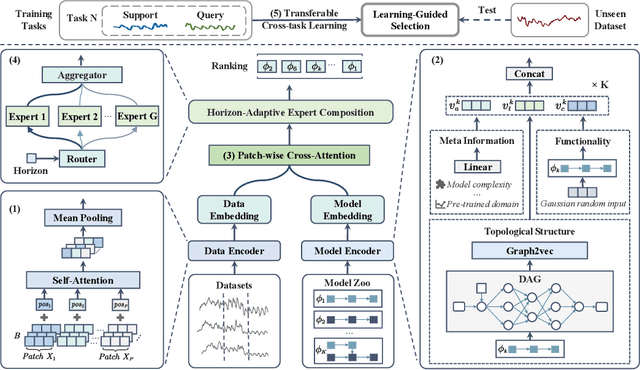
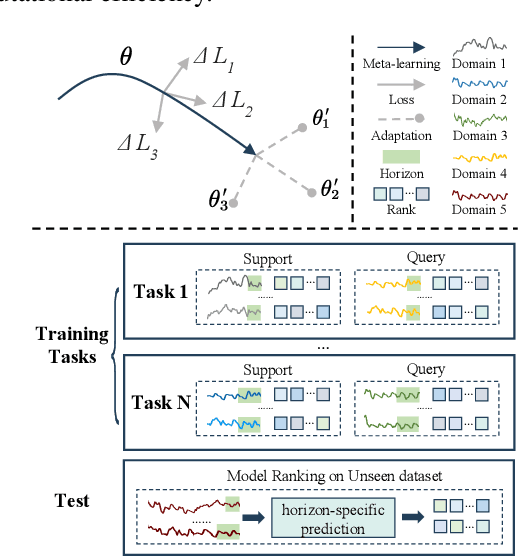
Pre-trained models exhibit strong generalization to various downstream tasks. However, given the numerous models available in the model hub, identifying the most suitable one by individually fine-tuning is time-consuming. In this paper, we propose \textbf{SwiftTS}, a swift selection framework for time series pre-trained models. To avoid expensive forward propagation through all candidates, SwiftTS adopts a learning-guided approach that leverages historical dataset-model performance pairs across diverse horizons to predict model performance on unseen datasets. It employs a lightweight dual-encoder architecture that embeds time series and candidate models with rich characteristics, computing patchwise compatibility scores between data and model embeddings for efficient selection. To further enhance the generalization across datasets and horizons, we introduce a horizon-adaptive expert composition module that dynamically adjusts expert weights, and the transferable cross-task learning with cross-dataset and cross-horizon task sampling to enhance out-of-distribution (OOD) robustness. Extensive experiments on 14 downstream datasets and 8 pre-trained models demonstrate that SwiftTS achieves state-of-the-art performance in time series pre-trained model selection.
Handling Imbalanced Pseudolabels for Vision-Language Models with Concept Alignment and Confusion-Aware Calibrated Margin
May 04, 2025Adapting vision-language models (VLMs) to downstream tasks with pseudolabels has gained increasing attention. A major obstacle is that the pseudolabels generated by VLMs tend to be imbalanced, leading to inferior performance. While existing methods have explored various strategies to address this, the underlying causes of imbalance remain insufficiently investigated. To fill this gap, we delve into imbalanced pseudolabels and identify two primary contributing factors: concept mismatch and concept confusion. To mitigate these two issues, we propose a novel framework incorporating concept alignment and confusion-aware calibrated margin mechanisms. The core of our approach lies in enhancing underperforming classes and promoting balanced predictions across categories, thus mitigating imbalance. Extensive experiments on six benchmark datasets with three learning paradigms demonstrate that the proposed method effectively enhances the accuracy and balance of pseudolabels, achieving a relative improvement of 6.29% over the SoTA method. Our code is avaliable at https://anonymous.4open.science/r/CAP-C642/
MoK-RAG: Mixture of Knowledge Paths Enhanced Retrieval-Augmented Generation for Embodied AI Environments
Mar 18, 2025While human cognition inherently retrieves information from diverse and specialized knowledge sources during decision-making processes, current Retrieval-Augmented Generation (RAG) systems typically operate through single-source knowledge retrieval, leading to a cognitive-algorithmic discrepancy. To bridge this gap, we introduce MoK-RAG, a novel multi-source RAG framework that implements a mixture of knowledge paths enhanced retrieval mechanism through functional partitioning of a large language model (LLM) corpus into distinct sections, enabling retrieval from multiple specialized knowledge paths. Applied to the generation of 3D simulated environments, our proposed MoK-RAG3D enhances this paradigm by partitioning 3D assets into distinct sections and organizing them based on a hierarchical knowledge tree structure. Different from previous methods that only use manual evaluation, we pioneered the introduction of automated evaluation methods for 3D scenes. Both automatic and human evaluations in our experiments demonstrate that MoK-RAG3D can assist Embodied AI agents in generating diverse scenes.