 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Recommender Transformers with Behavior Pathways
Jun 13, 2022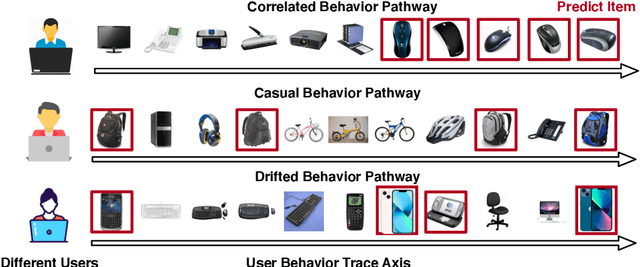
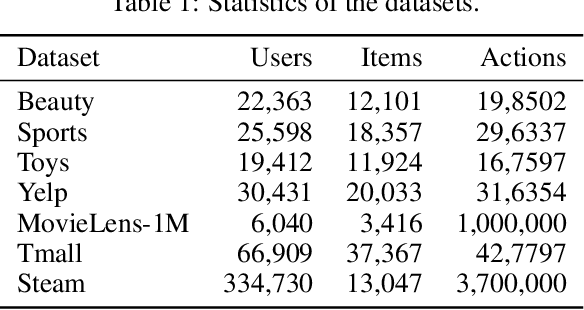
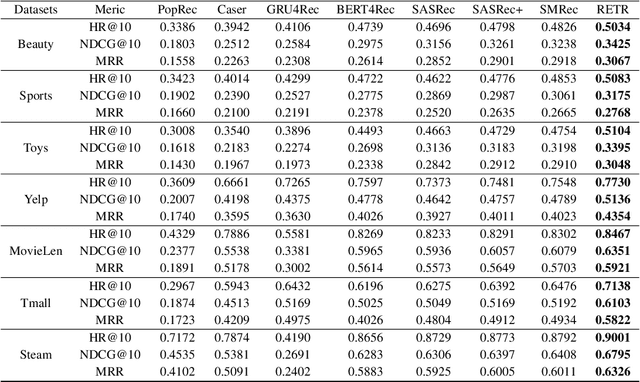
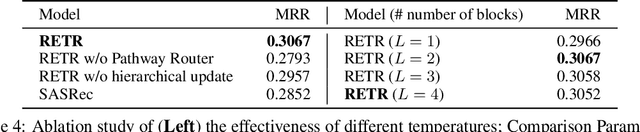
Sequential recommendation requires the recommender to capture the evolving behavior characteristics from logged user behavior data for accurate recommendations. However, user behavior sequences are viewed as a script with multiple ongoing threads intertwined. We find that only a small set of pivotal behaviors can be evolved into the user's future action. As a result, the future behavior of the user is hard to predict. We conclude this characteristic for sequential behaviors of each user as the Behavior Pathway. Different users have their unique behavior pathways. Among existing sequential models, transformers have shown great capacity in capturing global-dependent characteristics. However, these models mainly provide a dense distribution over all previous behaviors using the self-attention mechanism, making the final predictions overwhelmed by the trivial behaviors not adjusted to each user. In this paper, we build the Recommender Transformer (RETR) with a novel Pathway Attention mechanism. RETR can dynamically plan the behavior pathway specified for each user, and sparingly activate the network through this behavior pathway to effectively capture evolving patterns useful for recommendation. The key design is a learned binary route to prevent the behavior pathway from being overwhelmed by trivial behaviors. We empirically verify the effectiveness of RETR on seven real-world datasets and RETR yields state-of-the-art performance.
ModeRNN: Harnessing Spatiotemporal Mode Collapse in Unsupervised Predictive Learning
Oct 13, 2021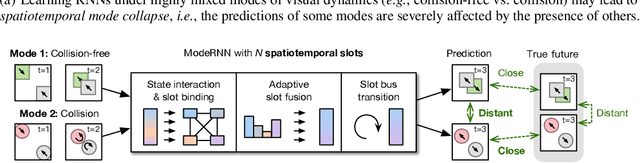



Learning predictive models for unlabeled spatiotemporal data is challenging in part because visual dynamics can be highly entangled in real scenes, making existing approaches prone to overfit partial modes of physical processes while neglecting to reason about others. We name this phenomenon spatiotemporal mode collapse and explore it for the first time in predictive learning. The key is to provide the model with a strong inductive bias to discover the compositional structures of latent modes. To this end, we propose ModeRNN, which introduces a novel method to learn structured hidden representations between recurrent states. The core idea of this framework is to first extract various components of visual dynamics using a set of spatiotemporal slots with independent parameters. Considering that multiple space-time patterns may co-exist in a sequence, we leverage learnable importance weights to adaptively aggregate slot features into a unified hidden representation, which is then used to update the recurrent states. Across the entire dataset, different modes result in different responses on the mixtures of slots, which enhances the ability of ModeRNN to build structured representations and thus prevents the so-called mode collapse. Unlike existing models, ModeRNN is shown to prevent spatiotemporal mode collapse and further benefit from learning mixed visual dynamics.
MotionRNN: A Flexible Model for Video Prediction with Spacetime-Varying Motions
Mar 04, 2021


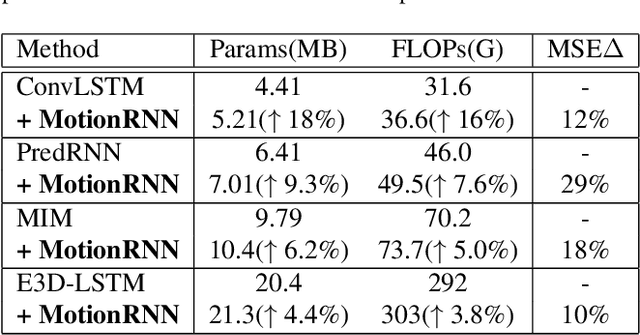
This paper tackles video prediction from a new dimension of predicting spacetime-varying motions that are incessantly changing across both space and time. Prior methods mainly capture the temporal state transitions but overlook the complex spatiotemporal variations of the motion itself, making them difficult to adapt to ever-changing motions. We observe that physical world motions can be decomposed into transient variation and motion trend, while the latter can be regarded as the accumulation of previous motions. Thus, simultaneously capturing the transient variation and the motion trend is the key to make spacetime-varying motions more predictable. Based on these observations, we propose the MotionRNN framework, which can capture the complex variations within motions and adapt to spacetime-varying scenarios. MotionRNN has two main contributions. The first is that we design the MotionGRU unit, which can model the transient variation and motion trend in a unified way. The second is that we apply the MotionGRU to RNN-based predictive models and indicate a new flexible video prediction architecture with a Motion Highway that can significantly improve the ability to predict changeable motions and avoid motion vanishing for stacked multiple-layer predictive models. With high flexibility, this framework can adapt to a series of models for deterministic spatiotemporal prediction. Our MotionRNN can yield significant improvements on three challenging benchmarks for video prediction with spacetime-varying motions.
Towards Good Practices of U-Net for Traffic Forecasting
Dec 04, 2020

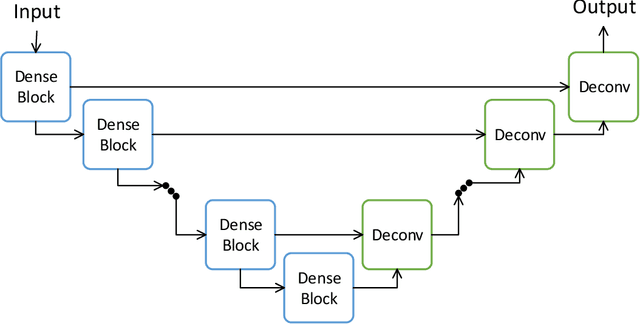
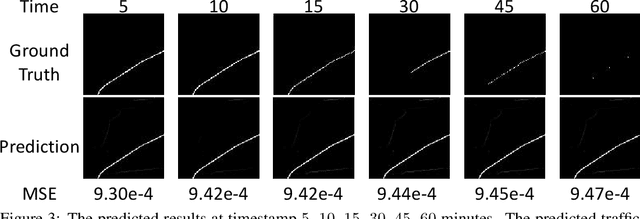
This technical report presents a solution for the 2020 Traffic4Cast Challenge. We consider the traffic forecasting problem as a future frame prediction task with relatively weak temporal dependencies (might be due to stochastic urban traffic dynamics) and strong prior knowledge, \textit{i.e.}, the roadmaps of the cities. For these reasons, we use the U-Net as the backbone model, and we propose a roadmap generation method to make the predicted traffic flows more rational. Meanwhile, we use a fine-tuning strategy based on the validation set to prevent overfitting, which effectively improves the prediction results. At the end of this report, we further discuss several approaches that we have considered or could be explored in future work: (1) harnessing inherent data patterns, such as seasonality; (2) distilling and transferring common knowledge between different cities. We also analyze the validity of the evaluation metric.
Unsupervised Transfer Learning for Spatiotemporal Predictive Networks
Sep 24, 2020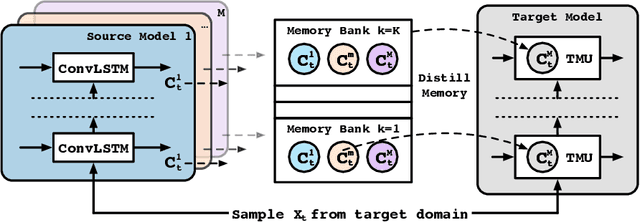
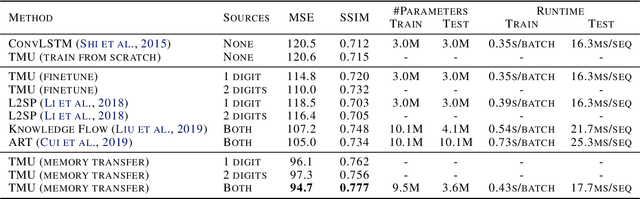


This paper explores a new research problem of unsupervised transfer learning across multiple spatiotemporal prediction tasks. Unlike most existing transfer learning methods that focus on fixing the discrepancy between supervised tasks, we study how to transfer knowledge from a zoo of unsupervisedly learned models towards another predictive network. Our motivation is that models from different sources are expected to understand the complex spatiotemporal dynamics from different perspectives, thereby effectively supplementing the new task, even if the task has sufficient training samples. Technically, we propose a differentiable framework named transferable memory. It adaptively distills knowledge from a bank of memory states of multiple pretrained RNNs, and applies it to the target network via a novel recurrent structure called the Transferable Memory Unit (TMU). Compared with finetuning, our approach yields significant improvements on three benchmarks for spatiotemporal prediction, and benefits the target task even from less relevant pretext ones.
Adversarial Pyramid Network for Video Domain Generalization
Dec 08, 2019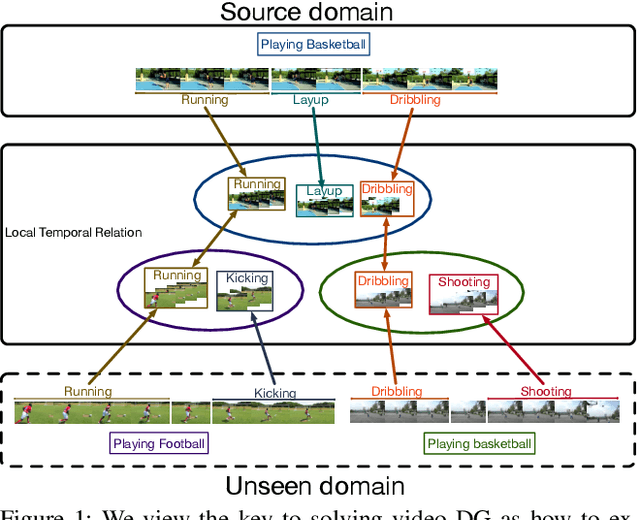
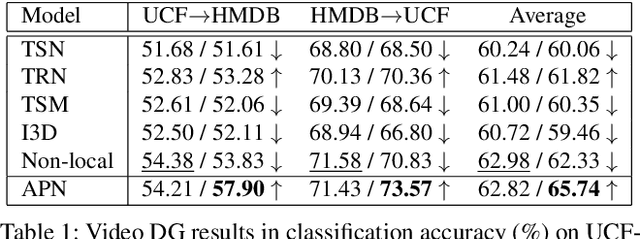
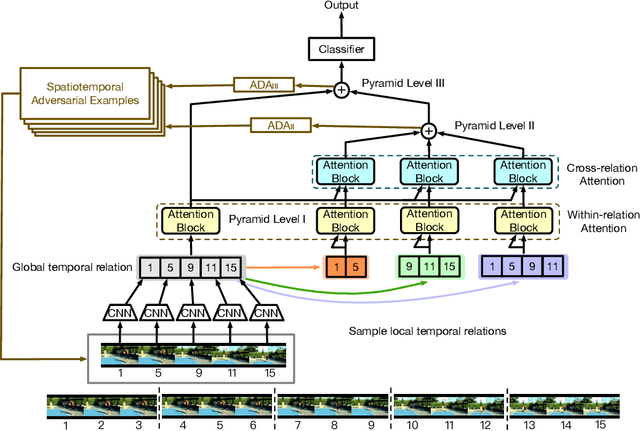

This paper introduces a new research problem of video domain generalization (video DG) where most state-of-the-art action recognition networks degenerate due to the lack of exposure to the target domains of divergent distributions. While recent advances in video understanding focus on capturing the temporal relations of the long-term video context, we observe that the global temporal features are less generalizable in the video DG settings. The reason is that videos from other unseen domains may have unexpected absence, misalignment, or scale transformation of the temporal relations, which is known as the temporal domain shift. Therefore, the video DG is even more challenging than the image DG, which is also under-explored, because of the entanglement of the spatial and temporal domain shifts. This finding has led us to view the key to video DG as how to effectively learn the local-relation features of different time scales that are more generalizable, and how to exploit them along with the global-relation features to maintain the discriminability. This paper presents the Adversarial Pyramid Network (APN), which captures the local-relation, global-relation, and multilayer cross-relation features progressively. This pyramid network not only improves the feature transferability from the view of representation learning, but also enhances the diversity and quality of the new data points that can bridge different domains when it is integrated with an improved version of the image DG adversarial data augmentation method. We construct four video DG benchmarks: UCF-HMDB, Something-Something, PKU-MMD, and NTU, in which the source and target domains are divided according to different datasets, different consequences of actions, or different camera views. The APN consistently outperforms previous action recognition models over all benchmarks.
Reversing Two-Stream Networks with Decoding Discrepancy Penalty for Robust Action Recognition
Nov 20, 2018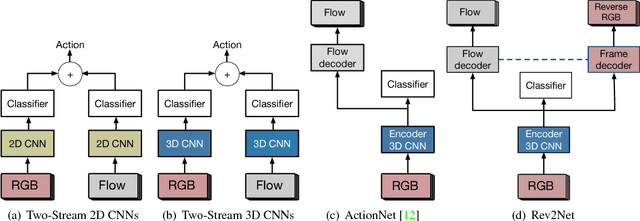

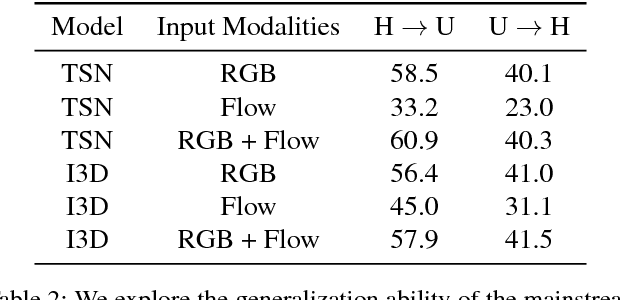
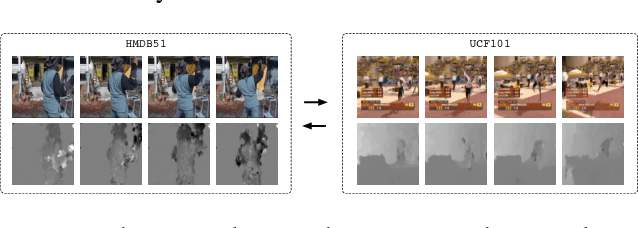
We discuss the robustness and generalization ability in the realm of action recognition, showing that the mainstream neural networks are not robust to disordered frames and diverse video environments. There are two possible reasons: First, existing models lack an appropriate method to overcome the inevitable decision discrepancy between multiple streams with different input modalities. Second, by doing cross-dataset experiments, we find that the optical flow features are hard to be transferred, which affects the generalization ability of the two-stream neural networks. For robust action recognition, we present the Reversed Two-Stream Networks (Rev2Net) which has three properties: (1) It could learn more transferable, robust video features by reversing the multi-modality inputs as training supervisions. It outperforms all other compared models in challenging frames shuffle experiments and cross-dataset experiments. (2) It is highlighted by an adaptive, collaborative multi-task learning approach that is applied between decoders to penalize their disagreement in the deep feature space. We name it the decoding discrepancy penalty (DDP). (3) As the decoder streams will be removed at test time, Rev2Net makes recognition decisions purely based on raw video frames. Rev2Net achieves the best results in the cross-dataset settings and competitive results on classic action recognition tasks: 94.6% for UCF-101, 71.1% for HMDB-51 and 73.3% for Kinetics. It performs even better than most methods who take extra inputs beyond raw RGB frames.