 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Pyramid Network for Video Domain Generalization
Paper and Code
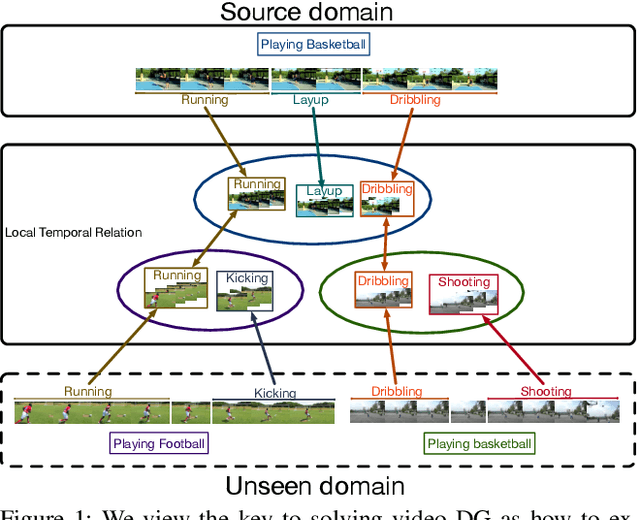
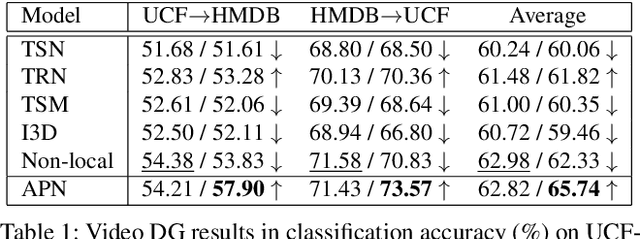
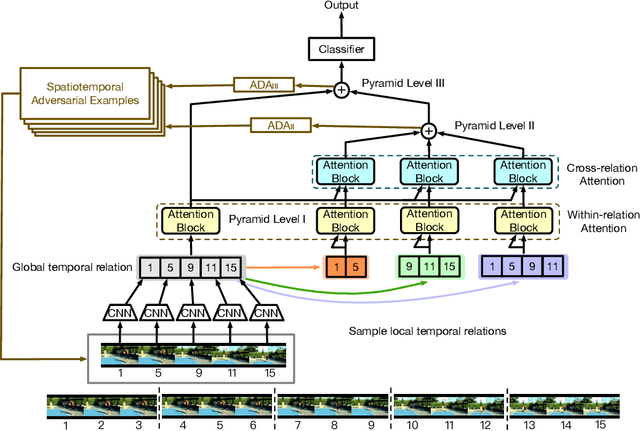

This paper introduces a new research problem of video domain generalization (video DG) where most state-of-the-art action recognition networks degenerate due to the lack of exposure to the target domains of divergent distributions. While recent advances in video understanding focus on capturing the temporal relations of the long-term video context, we observe that the global temporal features are less generalizable in the video DG settings. The reason is that videos from other unseen domains may have unexpected absence, misalignment, or scale transformation of the temporal relations, which is known as the temporal domain shift. Therefore, the video DG is even more challenging than the image DG, which is also under-explored, because of the entanglement of the spatial and temporal domain shifts. This finding has led us to view the key to video DG as how to effectively learn the local-relation features of different time scales that are more generalizable, and how to exploit them along with the global-relation features to maintain the discriminability. This paper presents the Adversarial Pyramid Network (APN), which captures the local-relation, global-relation, and multilayer cross-relation features progressively. This pyramid network not only improves the feature transferability from the view of representation learning, but also enhances the diversity and quality of the new data points that can bridge different domains when it is integrated with an improved version of the image DG adversarial data augmentation method. We construct four video DG benchmarks: UCF-HMDB, Something-Something, PKU-MMD, and NTU, in which the source and target domains are divided according to different datasets, different consequences of actions, or different camera views. The APN consistently outperforms previous action recognition models over all benchmarks.