 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Aware Hierarchical Contrastive Learning for Semi-Supervised Generalization Fault Diagnosis
Apr 22, 2026Fault diagnosis under unseen operating conditions remains highly challenging when labeled data are scarce. Semi-supervised domain generalization fault diagnosis (SSDGFD) provides a practical solution by jointly exploiting labeled and unlabeled source domains. However, existing methods still suffer from two coupled limitations. First, pseudo-labels for unlabeled domains are typically generated primarily from knowledge learned on the labeled source domain, which neglects domain-specific geometric discrepancies and thus induces systematic cross-domain pseudo-label bias. Second, unlabeled samples are commonly handled with a hard accept-or-discard strategy, where rigid thresholding causes imbalanced sample utilization across domains, while hard-label assignment for uncertain samples can easily introduce additional noise. To address these issues, we propose a unified framework termed domain-aware hierarchical contrastive learning (DAHCL) for SSDGFD. Specifically, DAHCL introduces a domain-aware learning (DAL) module to explicitly capture source-domain geometric characteristics and calibrate pseudo-label predictions across heterogeneous source domains, thereby mitigating cross-domain bias in pseudo-label generation. In addition, DAHCL develops a hierarchical contrastive learning (HCL) module that combines dynamic confidence stratification with fuzzy contrastive supervision, enabling uncertain samples to contribute to representation learning without relying on unreliable hard labels. In this way, DAHCL jointly improves the quality of supervision and the utilization of unlabeled samples. Furthermore, to better reflect practical industrial scenarios, we incorporate engineering noise into the SSDGFD evaluation protocol. Extensive experiments on three benchmark datasets demonstrate that...
Mutual Wasserstein Discrepancy Minimization for Sequential Recommendation
Jan 28, 2023Self-supervised sequential recommendation significantly improves recommendation performance by maximizing mutual information with well-designed data augmentations. However, the mutual information estimation is based on the calculation of Kullback Leibler divergence with several limitations, including asymmetrical estimation, the exponential need of the sample size, and training instability. Also, existing data augmentations are mostly stochastic and can potentially break sequential correlations with random modifications. These two issues motivate us to investigate an alternative robust mutual information measurement capable of modeling uncertainty and alleviating KL divergence limitations. To this end, we propose a novel self-supervised learning framework based on Mutual WasserStein discrepancy minimization MStein for the sequential recommendation. We propose the Wasserstein Discrepancy Measurement to measure the mutual information between augmented sequences. Wasserstein Discrepancy Measurement builds upon the 2-Wasserstein distance, which is more robust, more efficient in small batch sizes, and able to model the uncertainty of stochastic augmentation processes. We also propose a novel contrastive learning loss based on Wasserstein Discrepancy Measurement. Extensive experiments on four benchmark datasets demonstrate the effectiveness of MStein over baselines. More quantitative analyses show the robustness against perturbations and training efficiency in batch size. Finally, improvements analysis indicates better representations of popular users or items with significant uncertainty. The source code is at https://github.com/zfan20/MStein.
Time Lag Aware Sequential Recommendation
Aug 09, 2022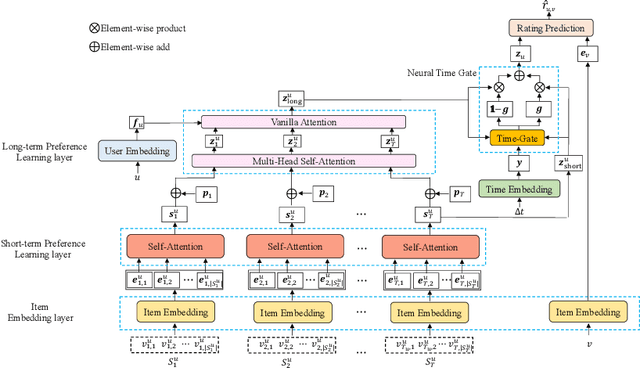

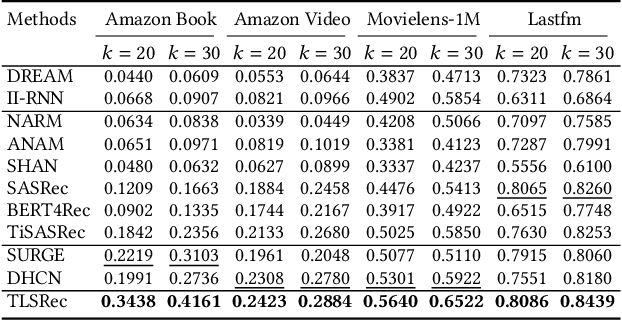
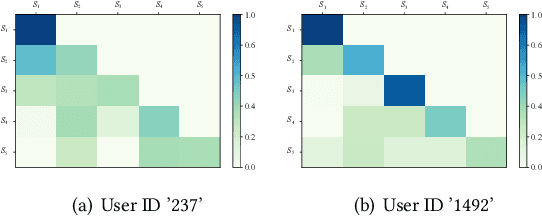
Although a variety of methods have been proposed for sequential recommendation, it is still far from being well solved partly due to two challenges. First, the existing methods often lack the simultaneous consideration of the global stability and local fluctuation of user preference, which might degrade the learning of a user's current preference. Second, the existing methods often use a scalar based weighting schema to fuse the long-term and short-term preferences, which is too coarse to learn an expressive embedding of current preference. To address the two challenges, we propose a novel model called Time Lag aware Sequential Recommendation (TLSRec), which integrates a hierarchical modeling of user preference and a time lag sensitive fine-grained fusion of the long-term and short-term preferences. TLSRec employs a hierarchical self-attention network to learn users' preference at both global and local time scales, and a neural time gate to adaptively regulate the contributions of the long-term and short-term preferences for the learning of a user's current preference at the aspect level and based on the lag between the current time and the time of the last behavior of a user. The extensive experiments conducted on real datasets verify the effectiveness of TLSRec.
Reversing Two-Stream Networks with Decoding Discrepancy Penalty for Robust Action Recognition
Nov 20, 2018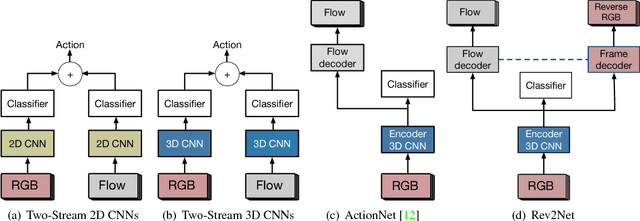

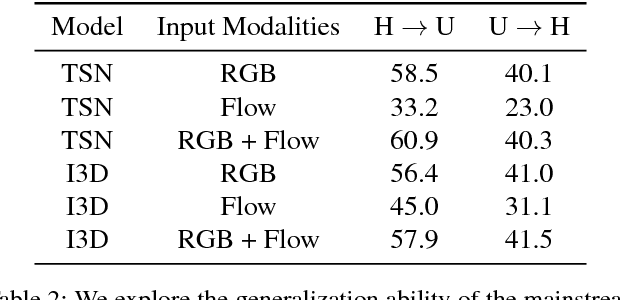
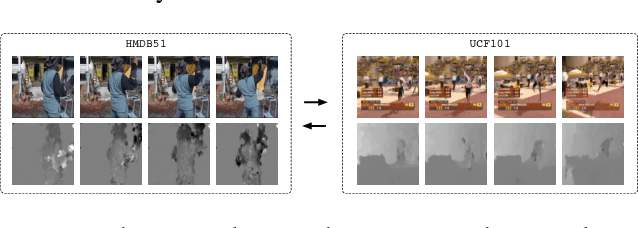
We discuss the robustness and generalization ability in the realm of action recognition, showing that the mainstream neural networks are not robust to disordered frames and diverse video environments. There are two possible reasons: First, existing models lack an appropriate method to overcome the inevitable decision discrepancy between multiple streams with different input modalities. Second, by doing cross-dataset experiments, we find that the optical flow features are hard to be transferred, which affects the generalization ability of the two-stream neural networks. For robust action recognition, we present the Reversed Two-Stream Networks (Rev2Net) which has three properties: (1) It could learn more transferable, robust video features by reversing the multi-modality inputs as training supervisions. It outperforms all other compared models in challenging frames shuffle experiments and cross-dataset experiments. (2) It is highlighted by an adaptive, collaborative multi-task learning approach that is applied between decoders to penalize their disagreement in the deep feature space. We name it the decoding discrepancy penalty (DDP). (3) As the decoder streams will be removed at test time, Rev2Net makes recognition decisions purely based on raw video frames. Rev2Net achieves the best results in the cross-dataset settings and competitive results on classic action recognition tasks: 94.6% for UCF-101, 71.1% for HMDB-51 and 73.3% for Kinetics. It performs even better than most methods who take extra inputs beyond raw RGB frames.
Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spatiotemporal Dynamics
Nov 19, 2018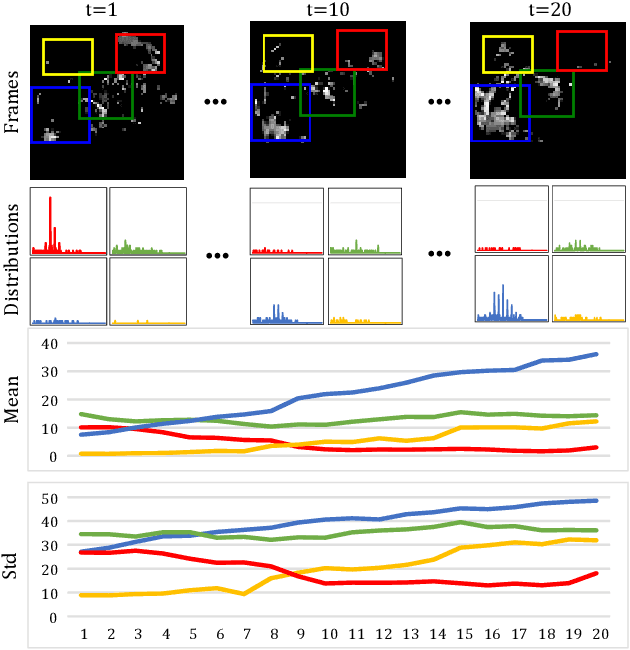
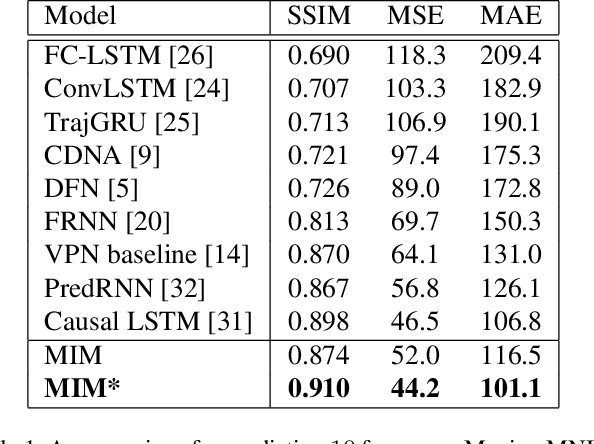
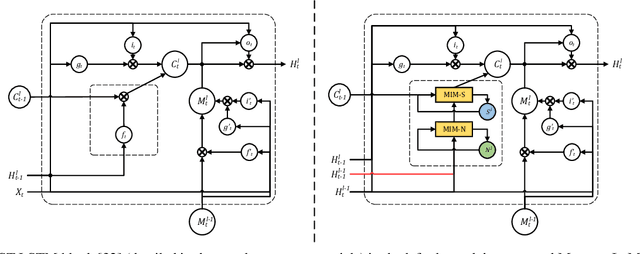

Natural spatiotemporal processes can be highly non-stationary in many ways, e.g. the low-level non-stationarity such as spatial correlations or temporal dependencies of local pixel values; and the high-level variations such as the accumulation, deformation or dissipation of radar echoes in precipitation forecasting. From Cramer's Decomposition, any non-stationary process can be decomposed into deterministic, time-variant polynomials, plus a zero-mean stochastic term. By applying differencing operations appropriately, we may turn time-variant polynomials into a constant, making the deterministic component predictable. However, most previous recurrent neural networks for spatiotemporal prediction do not use the differential signals effectively, and their relatively simple state transition functions prevent them from learning too complicated variations in spacetime. We propose the Memory In Memory (MIM) networks and corresponding recurrent blocks for this purpose. The MIM blocks exploit the differential signals between adjacent recurrent states to model the non-stationary and approximately stationary properties in spatiotemporal dynamics with two cascaded, self-renewed memory modules. By stacking multiple MIM blocks, we could potentially handle higher-order non-stationarity. The MIM networks achieve the state-of-the-art results on three spatiotemporal prediction tasks across both synthetic and real-world datasets. We believe that the general idea of this work can be potentially applied to other time-series forecasting tasks.
On the Feature Discovery for App Usage Prediction in Smartphones
Sep 26, 2013
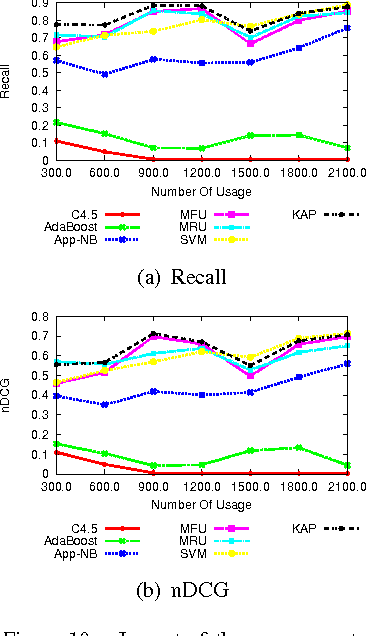
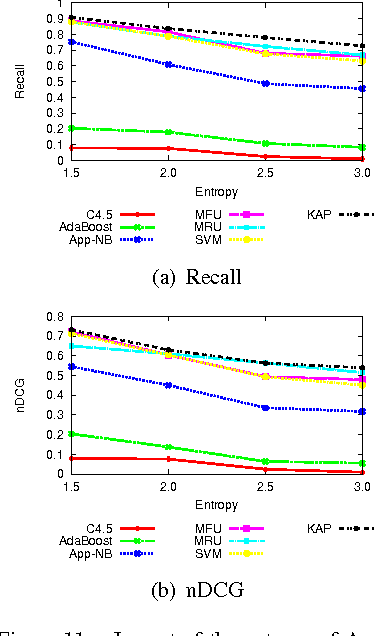
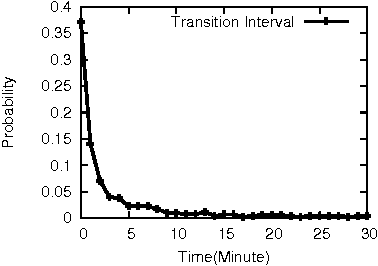
With the increasing number of mobile Apps developed, they are now closely integrated into daily life. In this paper, we develop a framework to predict mobile Apps that are most likely to be used regarding the current device status of a smartphone. Such an Apps usage prediction framework is a crucial prerequisite for fast App launching, intelligent user experience, and power management of smartphones. By analyzing real App usage log data, we discover two kinds of features: The Explicit Feature (EF) from sensing readings of built-in sensors, and the Implicit Feature (IF) from App usage relations. The IF feature is derived by constructing the proposed App Usage Graph (abbreviated as AUG) that models App usage transitions. In light of AUG, we are able to discover usage relations among Apps. Since users may have different usage behaviors on their smartphones, we further propose one personalized feature selection algorithm. We explore minimum description length (MDL) from the training data and select those features which need less length to describe the training data. The personalized feature selection can successfully reduce the log size and the prediction time. Finally, we adopt the kNN classification model to predict Apps usage. Note that through the features selected by the proposed personalized feature selection algorithm, we only need to keep these features, which in turn reduces the prediction time and avoids the curse of dimensionality when using the kNN classifier. We conduct a comprehensive experimental study based on a real mobile App usage dataset. The results demonstrate the effectiveness of the proposed framework and show the predictive capability for App usage prediction.