 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.
Unleash LLMs Potential for Recommendation by Coordinating Twin-Tower Dynamic Semantic Token Generator
Sep 14, 2024Owing to the unprecedented capability in semantic understanding and logical reasoning, the pre-trained large language models (LLMs) have shown fantastic potential in developing the next-generation recommender systems (RSs). However, the static index paradigm adopted by current methods greatly restricts the utilization of LLMs capacity for recommendation, leading to not only the insufficient alignment between semantic and collaborative knowledge, but also the neglect of high-order user-item interaction patterns. In this paper, we propose Twin-Tower Dynamic Semantic Recommender (TTDS), the first generative RS which adopts dynamic semantic index paradigm, targeting at resolving the above problems simultaneously. To be more specific, we for the first time contrive a dynamic knowledge fusion framework which integrates a twin-tower semantic token generator into the LLM-based recommender, hierarchically allocating meaningful semantic index for items and users, and accordingly predicting the semantic index of target item. Furthermore, a dual-modality variational auto-encoder is proposed to facilitate multi-grained alignment between semantic and collaborative knowledge. Eventually, a series of novel tuning tasks specially customized for capturing high-order user-item interaction patterns are proposed to take advantages of user historical behavior. Extensive experiments across three public datasets demonstrate the superiority of the proposed methodology in developing LLM-based generative RSs. The proposed TTDS recommender achieves an average improvement of 19.41% in Hit-Rate and 20.84% in NDCG metric, compared with the leading baseline methods.
Distill-VQ: Learning Retrieval Oriented Vector Quantization By Distilling Knowledge from Dense Embeddings
Apr 01, 2022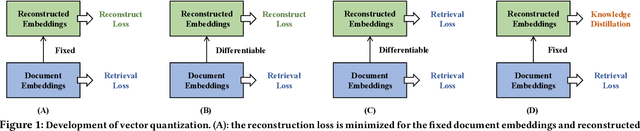
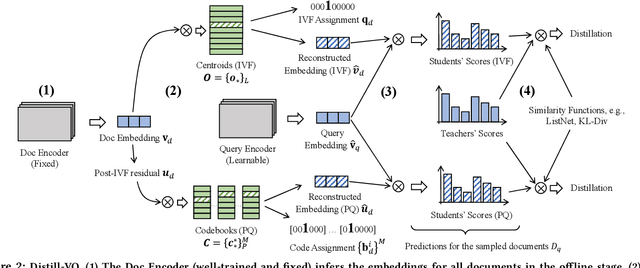
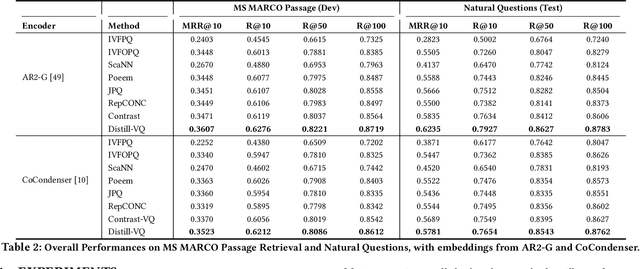
Vector quantization (VQ) based ANN indexes, such as Inverted File System (IVF) and Product Quantization (PQ), have been widely applied to embedding based document retrieval thanks to the competitive time and memory efficiency. Originally, VQ is learned to minimize the reconstruction loss, i.e., the distortions between the original dense embeddings and the reconstructed embeddings after quantization. Unfortunately, such an objective is inconsistent with the goal of selecting ground-truth documents for the input query, which may cause severe loss of retrieval quality. Recent works identify such a defect, and propose to minimize the retrieval loss through contrastive learning. However, these methods intensively rely on queries with ground-truth documents, whose performance is limited by the insufficiency of labeled data. In this paper, we propose Distill-VQ, which unifies the learning of IVF and PQ within a knowledge distillation framework. In Distill-VQ, the dense embeddings are leveraged as "teachers", which predict the query's relevance to the sampled documents. The VQ modules are treated as the "students", which are learned to reproduce the predicted relevance, such that the reconstructed embeddings may fully preserve the retrieval result of the dense embeddings. By doing so, Distill-VQ is able to derive substantial training signals from the massive unlabeled data, which significantly contributes to the retrieval quality. We perform comprehensive explorations for the optimal conduct of knowledge distillation, which may provide useful insights for the learning of VQ based ANN index. We also experimentally show that the labeled data is no longer a necessity for high-quality vector quantization, which indicates Distill-VQ's strong applicability in practice.
Uni-Retriever: Towards Learning The Unified Embedding Based Retriever in Bing Sponsored Search
Feb 13, 2022
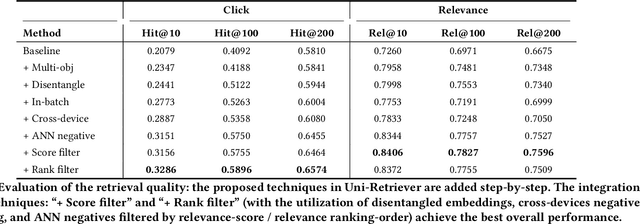

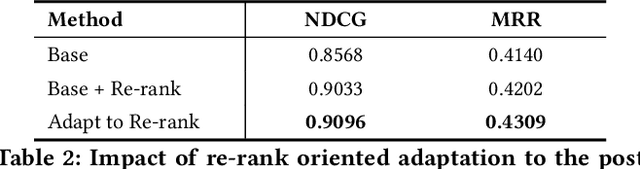
Embedding based retrieval (EBR) is a fundamental building block in many web applications. However, EBR in sponsored search is distinguished from other generic scenarios and technically challenging due to the need of serving multiple retrieval purposes: firstly, it has to retrieve high-relevance ads, which may exactly serve user's search intent; secondly, it needs to retrieve high-CTR ads so as to maximize the overall user clicks. In this paper, we present a novel representation learning framework Uni-Retriever developed for Bing Search, which unifies two different training modes knowledge distillation and contrastive learning to realize both required objectives. On one hand, the capability of making high-relevance retrieval is established by distilling knowledge from the ``relevance teacher model''. On the other hand, the capability of making high-CTR retrieval is optimized by learning to discriminate user's clicked ads from the entire corpus. The two training modes are jointly performed as a multi-objective learning process, such that the ads of high relevance and CTR can be favored by the generated embeddings. Besides the learning strategy, we also elaborate our solution for EBR serving pipeline built upon the substantially optimized DiskANN, where massive-scale EBR can be performed with competitive time and memory efficiency, and accomplished in high-quality. We make comprehensive offline and online experiments to evaluate the proposed techniques, whose findings may provide useful insights for the future development of EBR systems. Uni-Retriever has been mainstreamed as the major retrieval path in Bing's production thanks to the notable improvements on the representation and EBR serving quality.
Progressively Optimized Bi-Granular Document Representation for Scalable Embedding Based Retrieval
Jan 14, 2022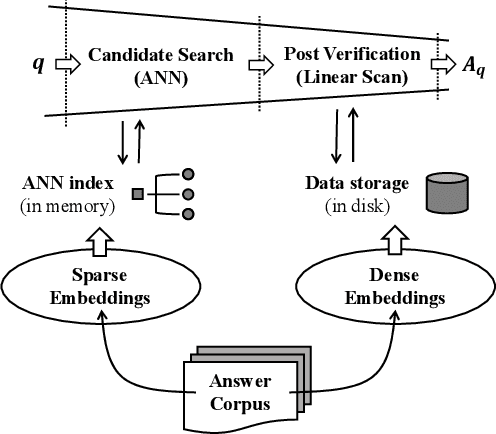
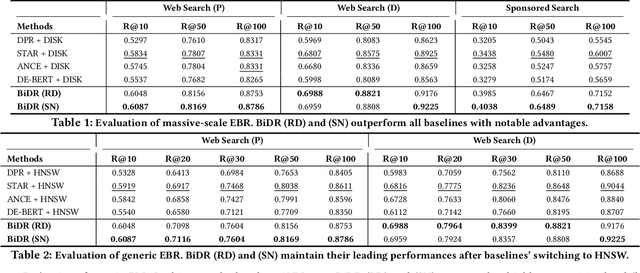
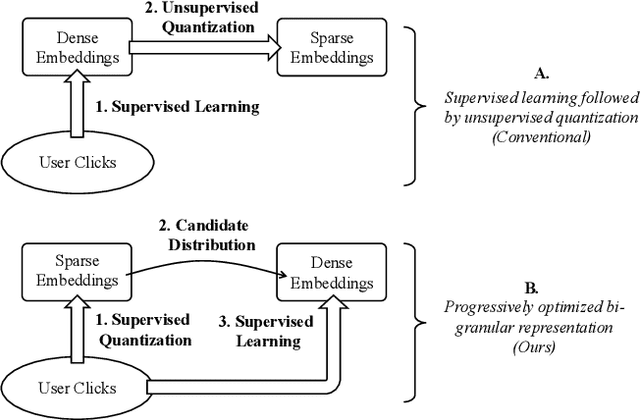
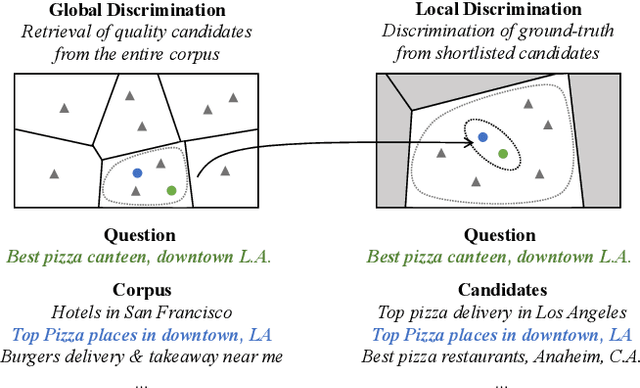
Ad-hoc search calls for the selection of appropriate answers from a massive-scale corpus. Nowadays, the embedding-based retrieval (EBR) becomes a promising solution, where deep learning based document representation and ANN search techniques are allied to handle this task. However, a major challenge is that the ANN index can be too large to fit into memory, given the considerable size of answer corpus. In this work, we tackle this problem with Bi-Granular Document Representation, where the lightweight sparse embeddings are indexed and standby in memory for coarse-grained candidate search, and the heavyweight dense embeddings are hosted in disk for fine-grained post verification. For the best of retrieval accuracy, a Progressive Optimization framework is designed. The sparse embeddings are learned ahead for high-quality search of candidates. Conditioned on the candidate distribution induced by the sparse embeddings, the dense embeddings are continuously learned to optimize the discrimination of ground-truth from the shortlisted candidates. Besides, two techniques: the contrastive quantization and the locality-centric sampling are introduced for the learning of sparse and dense embeddings, which substantially contribute to their performances. Thanks to the above features, our method effectively handles massive-scale EBR with strong advantages in accuracy: with up to +4.3% recall gain on million-scale corpus, and up to +17.5% recall gain on billion-scale corpus. Besides, Our method is applied to a major sponsored search platform with substantial gains on revenue (+1.95%), Recall (+1.01%) and CTR (+0.49%).
PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning
Mar 18, 2021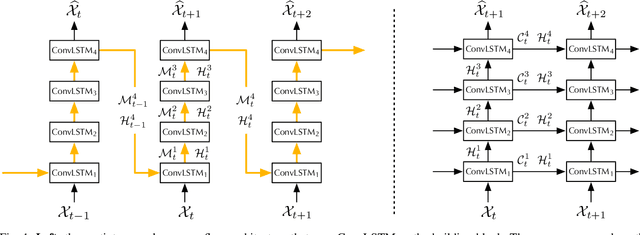
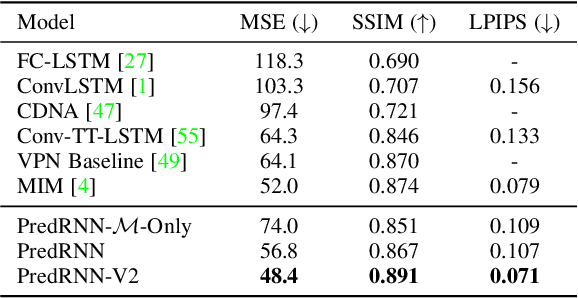
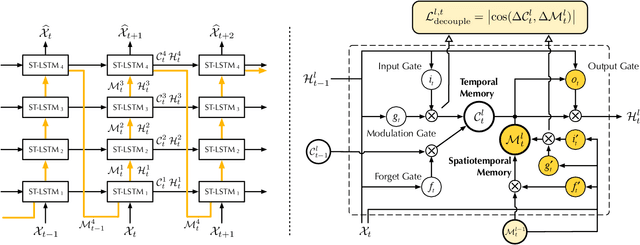
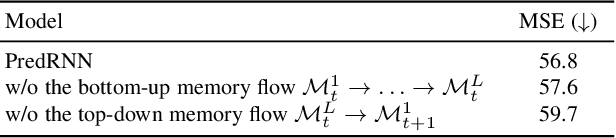
The predictive learning of spatiotemporal sequences aims to generate future images by learning from the historical context, where the visual dynamics are believed to have modular structures that can be learned with compositional subsystems. This paper models these structures by presenting PredRNN, a new recurrent network, in which a pair of memory cells are explicitly decoupled, operate in nearly independent transition manners, and finally form unified representations of the complex environment. Concretely, besides the original memory cell of LSTM, this network is featured by a zigzag memory flow that propagates in both bottom-up and top-down directions across all layers, enabling the learned visual dynamics at different levels of RNNs to communicate. It also leverages a memory decoupling loss to keep the memory cells from learning redundant features. We further improve PredRNN with a new curriculum learning strategy, which can be generalized to most sequence-to-sequence RNNs in predictive learning scenarios. We provide detailed ablation studies, gradient analyses, and visualizations to verify the effectiveness of each component. We show that our approach obtains highly competitive results on three standard datasets: the synthetic Moving MNIST dataset, the KTH human action dataset, and a radar echo dataset for precipitation forecasting.
Towards Good Practices of U-Net for Traffic Forecasting
Dec 04, 2020

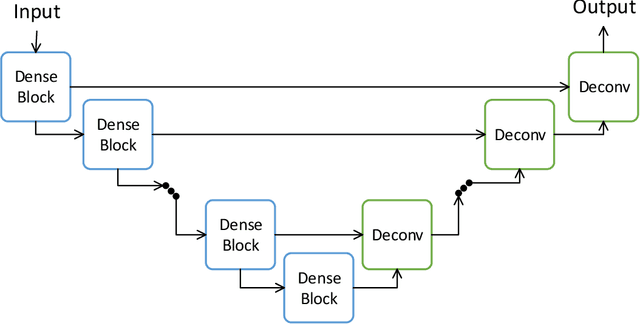
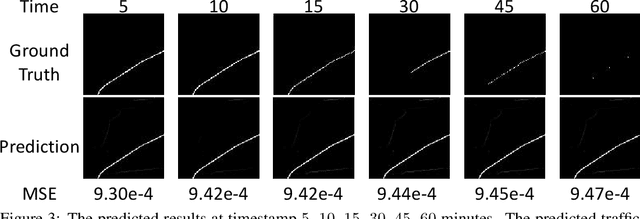
This technical report presents a solution for the 2020 Traffic4Cast Challenge. We consider the traffic forecasting problem as a future frame prediction task with relatively weak temporal dependencies (might be due to stochastic urban traffic dynamics) and strong prior knowledge, \textit{i.e.}, the roadmaps of the cities. For these reasons, we use the U-Net as the backbone model, and we propose a roadmap generation method to make the predicted traffic flows more rational. Meanwhile, we use a fine-tuning strategy based on the validation set to prevent overfitting, which effectively improves the prediction results. At the end of this report, we further discuss several approaches that we have considered or could be explored in future work: (1) harnessing inherent data patterns, such as seasonality; (2) distilling and transferring common knowledge between different cities. We also analyze the validity of the evaluation metric.
Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spatiotemporal Dynamics
Nov 19, 2018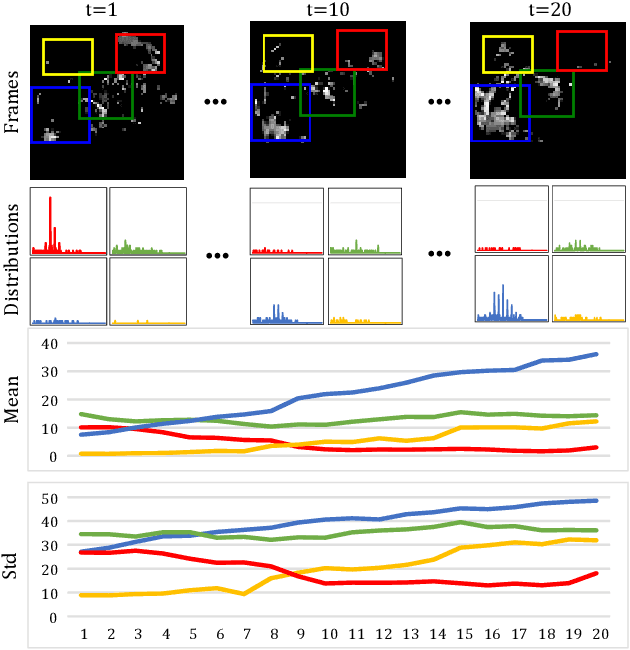
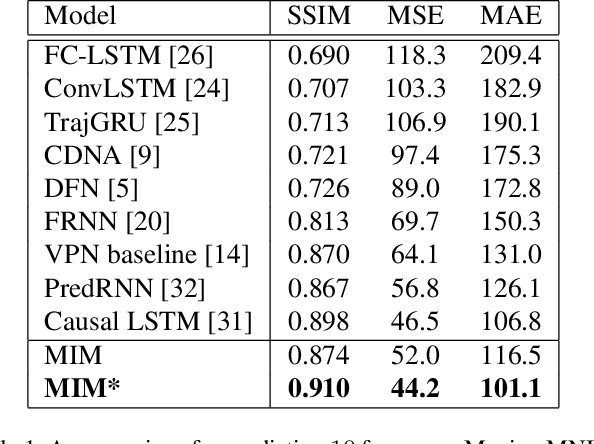
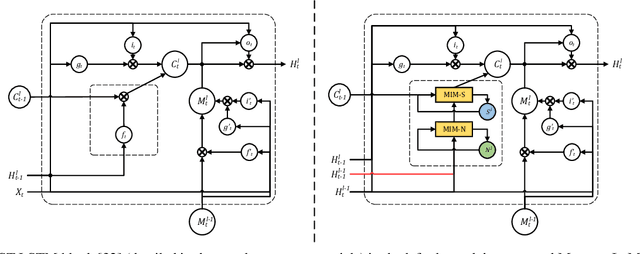

Natural spatiotemporal processes can be highly non-stationary in many ways, e.g. the low-level non-stationarity such as spatial correlations or temporal dependencies of local pixel values; and the high-level variations such as the accumulation, deformation or dissipation of radar echoes in precipitation forecasting. From Cramer's Decomposition, any non-stationary process can be decomposed into deterministic, time-variant polynomials, plus a zero-mean stochastic term. By applying differencing operations appropriately, we may turn time-variant polynomials into a constant, making the deterministic component predictable. However, most previous recurrent neural networks for spatiotemporal prediction do not use the differential signals effectively, and their relatively simple state transition functions prevent them from learning too complicated variations in spacetime. We propose the Memory In Memory (MIM) networks and corresponding recurrent blocks for this purpose. The MIM blocks exploit the differential signals between adjacent recurrent states to model the non-stationary and approximately stationary properties in spatiotemporal dynamics with two cascaded, self-renewed memory modules. By stacking multiple MIM blocks, we could potentially handle higher-order non-stationarity. The MIM networks achieve the state-of-the-art results on three spatiotemporal prediction tasks across both synthetic and real-world datasets. We believe that the general idea of this work can be potentially applied to other time-series forecasting tasks.