 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Graph meets Multimodal: Benchmarking on Multimodal Attributed Graphs Learning
Oct 11, 2024



Multimodal attributed graphs (MAGs) are prevalent in various real-world scenarios and generally contain two kinds of knowledge: (a) Attribute knowledge is mainly supported by the attributes of different modalities contained in nodes (entities) themselves, such as texts and images. (b) Topology knowledge, on the other hand, is provided by the complex interactions posed between nodes. The cornerstone of MAG representation learning lies in the seamless integration of multimodal attributes and topology. Recent advancements in Pre-trained Language/Vision models (PLMs/PVMs) and Graph neural networks (GNNs) have facilitated effective learning on MAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for MAG representation learning has impeded progress in this field. In this paper, we propose Multimodal Attribute Graph Benchmark (MAGB)}, a comprehensive and diverse collection of challenging benchmark datasets for MAGs. The MAGB datasets are notably large in scale and encompass a wide range of domains, spanning from e-commerce networks to social networks. In addition to the brand-new datasets, we conduct extensive benchmark experiments over MAGB with various learning paradigms, ranging from GNN-based and PLM-based methods, to explore the necessity and feasibility of integrating multimodal attributes and graph topology. In a nutshell, we provide an overview of the MAG datasets, standardized evaluation procedures, and present baseline experiments. The entire MAGB project is publicly accessible at https://github.com/sktsherlock/ATG.
Unleash LLMs Potential for Recommendation by Coordinating Twin-Tower Dynamic Semantic Token Generator
Sep 14, 2024Owing to the unprecedented capability in semantic understanding and logical reasoning, the pre-trained large language models (LLMs) have shown fantastic potential in developing the next-generation recommender systems (RSs). However, the static index paradigm adopted by current methods greatly restricts the utilization of LLMs capacity for recommendation, leading to not only the insufficient alignment between semantic and collaborative knowledge, but also the neglect of high-order user-item interaction patterns. In this paper, we propose Twin-Tower Dynamic Semantic Recommender (TTDS), the first generative RS which adopts dynamic semantic index paradigm, targeting at resolving the above problems simultaneously. To be more specific, we for the first time contrive a dynamic knowledge fusion framework which integrates a twin-tower semantic token generator into the LLM-based recommender, hierarchically allocating meaningful semantic index for items and users, and accordingly predicting the semantic index of target item. Furthermore, a dual-modality variational auto-encoder is proposed to facilitate multi-grained alignment between semantic and collaborative knowledge. Eventually, a series of novel tuning tasks specially customized for capturing high-order user-item interaction patterns are proposed to take advantages of user historical behavior. Extensive experiments across three public datasets demonstrate the superiority of the proposed methodology in developing LLM-based generative RSs. The proposed TTDS recommender achieves an average improvement of 19.41% in Hit-Rate and 20.84% in NDCG metric, compared with the leading baseline methods.
Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution
Jun 22, 2020
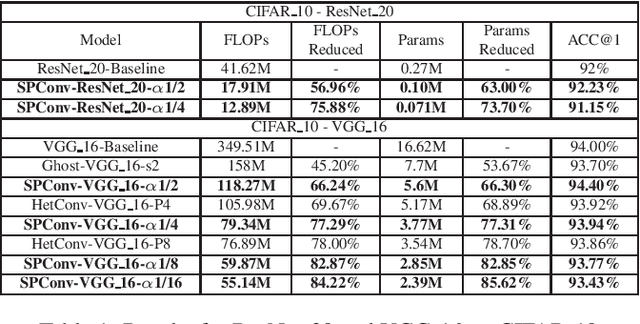
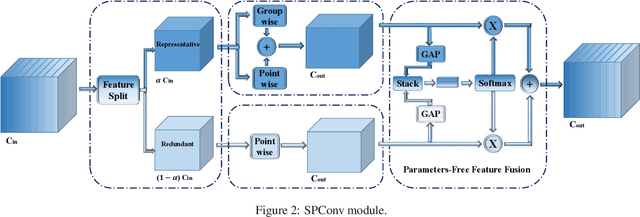
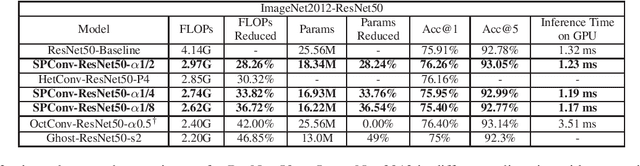
Many effective solutions have been proposed to reduce the redundancy of models for inference acceleration. Nevertheless, common approaches mostly focus on eliminating less important filters or constructing efficient operations, while ignoring the pattern redundancy in feature maps. We reveal that many feature maps within a layer share similar but not identical patterns. However, it is difficult to identify if features with similar patterns are redundant or contain essential details. Therefore, instead of directly removing uncertain redundant features, we propose a \textbf{sp}lit based \textbf{conv}olutional operation, namely SPConv, to tolerate features with similar patterns but require less computation. Specifically, we split input feature maps into the representative part and the uncertain redundant part, where intrinsic information is extracted from the representative part through relatively heavy computation while tiny hidden details in the uncertain redundant part are processed with some light-weight operation. To recalibrate and fuse these two groups of processed features, we propose a parameters-free feature fusion module. Moreover, our SPConv is formulated to replace the vanilla convolution in a plug-and-play way. Without any bells and whistles, experimental results on benchmarks demonstrate SPConv-equipped networks consistently outperform state-of-the-art baselines in both accuracy and inference time on GPU, with FLOPs and parameters dropped sharply.