 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Resolution Network
Jun 05, 2021
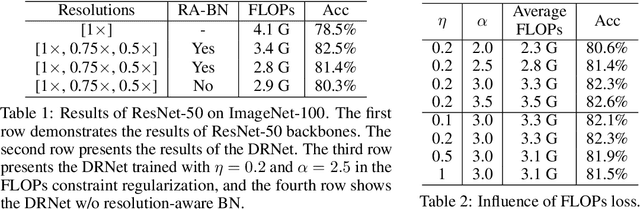
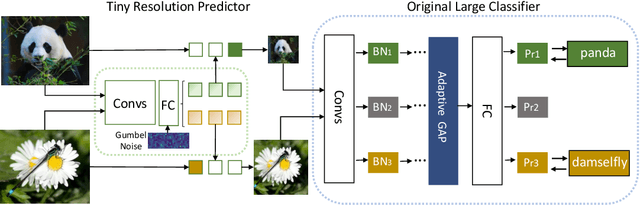
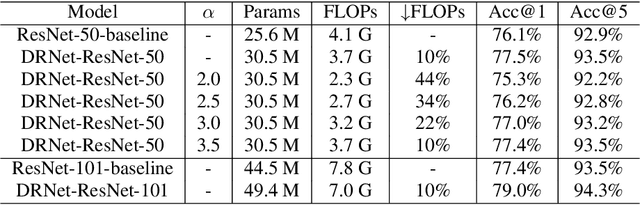
Deep convolutional neural networks (CNNs) are often of sophisticated design with numerous convolutional layers and learnable parameters for the accuracy reason. To alleviate the expensive costs of deploying them on mobile devices, recent works have made huge efforts for excavating redundancy in pre-defined architectures. Nevertheless, the redundancy on the input resolution of modern CNNs has not been fully investigated, i.e., the resolution of input image is fixed. In this paper, we observe that the smallest resolution for accurately predicting the given image is different using the same neural network. To this end, we propose a novel dynamic-resolution network (DRNet) in which the resolution is determined dynamically based on each input sample. Thus, a resolution predictor with negligible computational costs is explored and optimized jointly with the desired network. In practice, the predictor learns the smallest resolution that can retain and even exceed the original recognition accuracy for each image. During the inference, each input image will be resized to its predicted resolution for minimizing the overall computation burden. We then conduct extensive experiments on several benchmark networks and datasets. The results show that our DRNet can be embedded in any off-the-shelf network architecture to obtain a considerable reduction in computational complexity. For instance, DRNet achieves similar performance with an about 34% computation reduction, while gains 1.4% accuracy increase with 10% computation reduction compared to the original ResNet-50 on ImageNet.
Model Rubik's Cube: Twisting Resolution, Depth and Width for TinyNets
Oct 28, 2020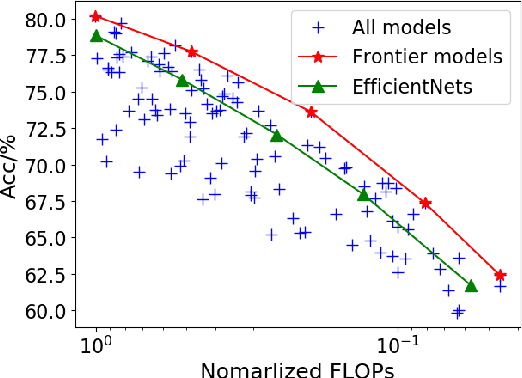

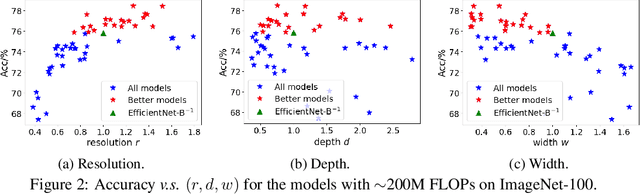
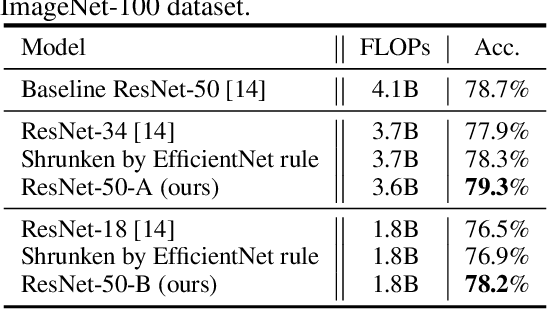
To obtain excellent deep neural architectures, a series of techniques are carefully designed in EfficientNets. The giant formula for simultaneously enlarging the resolution, depth and width provides us a Rubik's cube for neural networks. So that we can find networks with high efficiency and excellent performance by twisting the three dimensions. This paper aims to explore the twisting rules for obtaining deep neural networks with minimum model sizes and computational costs. Different from the network enlarging, we observe that resolution and depth are more important than width for tiny networks. Therefore, the original method, i.e., the compound scaling in EfficientNet is no longer suitable. To this end, we summarize a tiny formula for downsizing neural architectures through a series of smaller models derived from the EfficientNet-B0 with the FLOPs constraint. Experimental results on the ImageNet benchmark illustrate that our TinyNet performs much better than the smaller version of EfficientNets using the inversed giant formula. For instance, our TinyNet-E achieves a 59.9% Top-1 accuracy with only 24M FLOPs, which is about 1.9% higher than that of the previous best MobileNetV3 with similar computational cost. Code will be available at https://github.com/huawei-noah/CV-Backbones/tree/main/tinynet, and https://gitee.com/mindspore/mindspore/tree/master/model_zoo/research/cv/tinynet.
Split to Be Slim: An Overlooked Redundancy in Vanilla Convolution
Jun 22, 2020
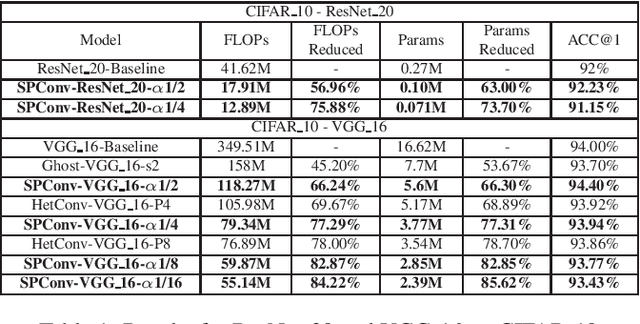
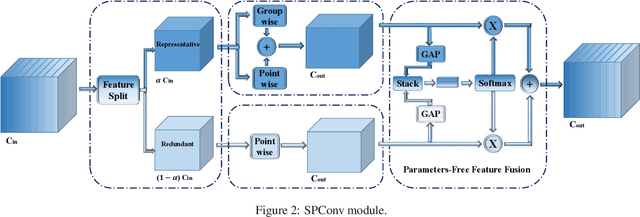
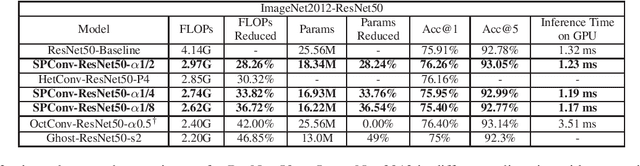
Many effective solutions have been proposed to reduce the redundancy of models for inference acceleration. Nevertheless, common approaches mostly focus on eliminating less important filters or constructing efficient operations, while ignoring the pattern redundancy in feature maps. We reveal that many feature maps within a layer share similar but not identical patterns. However, it is difficult to identify if features with similar patterns are redundant or contain essential details. Therefore, instead of directly removing uncertain redundant features, we propose a \textbf{sp}lit based \textbf{conv}olutional operation, namely SPConv, to tolerate features with similar patterns but require less computation. Specifically, we split input feature maps into the representative part and the uncertain redundant part, where intrinsic information is extracted from the representative part through relatively heavy computation while tiny hidden details in the uncertain redundant part are processed with some light-weight operation. To recalibrate and fuse these two groups of processed features, we propose a parameters-free feature fusion module. Moreover, our SPConv is formulated to replace the vanilla convolution in a plug-and-play way. Without any bells and whistles, experimental results on benchmarks demonstrate SPConv-equipped networks consistently outperform state-of-the-art baselines in both accuracy and inference time on GPU, with FLOPs and parameters dropped sharply.