 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Eval: Agentic and Automated Evaluation for Embodied Brain
Feb 02, 2026Current embodied VLM evaluation relies on static, expert-defined, manually annotated benchmarks that exhibit severe redundancy and coverage imbalance. This labor intensive paradigm drains computational and annotation resources, inflates costs, and distorts model rankings, ultimately stifling iterative development. To address this, we propose Agentic Automatic Evaluation (A2Eval), the first agentic framework that automates benchmark curation and evaluation through two collaborative agents. The Data Agent autonomously induces capability dimensions and assembles a balanced, compact evaluation suite, while the Eval Agent synthesizes and validates executable evaluation pipelines, enabling fully autonomous, high-fidelity assessment. Evaluated across 10 benchmarks and 13 models, A2Eval compresses evaluation suites by 85%, reduces overall computational costs by 77%, and delivers a 4.6x speedup while preserving evaluation quality. Crucially, A2Eval corrects systematic ranking biases, improves human alignment to Spearman's rho=0.85, and maintains high ranking fidelity (Kendall's tau=0.81), establishing a new standard for high-fidelity, low-cost embodied assessment. Our code and data will be public soon.
Parallelism and Generation Order in Masked Diffusion Language Models: Limits Today, Potential Tomorrow
Jan 22, 2026Masked Diffusion Language Models (MDLMs) promise parallel token generation and arbitrary-order decoding, yet it remains unclear to what extent current models truly realize these capabilities. We characterize MDLM behavior along two dimensions -- parallelism strength and generation order -- using Average Finalization Parallelism (AFP) and Kendall's tau. We evaluate eight mainstream MDLMs (up to 100B parameters) on 58 benchmarks spanning knowledge, reasoning, and programming. The results show that MDLMs still lag behind comparably sized autoregressive models, mainly because parallel probabilistic modeling weakens inter-token dependencies. Meanwhile, MDLMs exhibit adaptive decoding behavior: their parallelism and generation order vary significantly with the task domain, the stage of reasoning, and whether the output is correct. On tasks that require "backward information" (e.g., Sudoku), MDLMs adopt a solution order that tends to fill easier Sudoku blanks first, highlighting their advantages. Finally, we provide theoretical motivation and design insights supporting a Generate-then-Edit paradigm, which mitigates dependency loss while retaining the efficiency of parallel decoding.
RECAP: Resistance Capture in Text-based Mental Health Counseling with Large Language Models
Jan 21, 2026Recognizing and navigating client resistance is critical for effective mental health counseling, yet detecting such behaviors is particularly challenging in text-based interactions. Existing NLP approaches oversimplify resistance categories, ignore the sequential dynamics of therapeutic interventions, and offer limited interpretability. To address these limitations, we propose PsyFIRE, a theoretically grounded framework capturing 13 fine-grained resistance behaviors alongside collaborative interactions. Based on PsyFIRE, we construct the ClientResistance corpus with 23,930 annotated utterances from real-world Chinese text-based counseling, each supported by context-specific rationales. Leveraging this dataset, we develop RECAP, a two-stage framework that detects resistance and fine-grained resistance types with explanations. RECAP achieves 91.25% F1 for distinguishing collaboration and resistance and 66.58% macro-F1 for fine-grained resistance categories classification, outperforming leading prompt-based LLM baselines by over 20 points. Applied to a separate counseling dataset and a pilot study with 62 counselors, RECAP reveals the prevalence of resistance, its negative impact on therapeutic relationships and demonstrates its potential to improve counselors' understanding and intervention strategies.
PsyCLIENT: Client Simulation via Conversational Trajectory Modeling for Trainee Practice and Model Evaluation in Mental Health Counseling
Jan 12, 2026LLM-based client simulation has emerged as a promising tool for training novice counselors and evaluating automated counseling systems. However, existing client simulation approaches face three key challenges: (1) limited diversity and realism in client profiles, (2) the lack of a principled framework for modeling realistic client behaviors, and (3) a scarcity in Chinese-language settings. To address these limitations, we propose PsyCLIENT, a novel simulation framework grounded in conversational trajectory modeling. By conditioning LLM generation on predefined real-world trajectories that incorporate explicit behavior labels and content constraints, our approach ensures diverse and realistic interactions. We further introduce PsyCLIENT-CP, the first open-source Chinese client profile dataset, covering 60 distinct counseling topics. Comprehensive evaluations involving licensed professional counselors demonstrate that PsyCLIENT significantly outperforms baselines in terms of authenticity and training effectiveness. Notably, the simulated clients are nearly indistinguishable from human clients, achieving an about 95\% expert confusion rate in discrimination tasks. These findings indicate that conversational trajectory modeling effectively bridges the gap between theoretical client profiles and dynamic, realistic simulations, offering a robust solution for mental health education and research. Code and data will be released to facilitate future research in mental health counseling.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Knocking-Heads Attention
Oct 27, 2025Multi-head attention (MHA) has become the cornerstone of modern large language models, enhancing representational capacity through parallel attention heads. However, increasing the number of heads inherently weakens individual head capacity, and existing attention mechanisms - whether standard MHA or its variants like grouped-query attention (GQA) and grouped-tied attention (GTA) - simply concatenate outputs from isolated heads without strong interaction. To address this limitation, we propose knocking-heads attention (KHA), which enables attention heads to "knock" on each other - facilitating cross-head feature-level interactions before the scaled dot-product attention. This is achieved by applying a shared, diagonally-initialized projection matrix across all heads. The diagonal initialization preserves head-specific specialization at the start of training while allowing the model to progressively learn integrated cross-head representations. KHA adds only minimal parameters and FLOPs and can be seamlessly integrated into MHA, GQA, GTA, and other attention variants. We validate KHA by training a 6.1B parameter MoE model (1.01B activated) on 1T high-quality tokens. Compared to baseline attention mechanisms, KHA brings superior and more stable training dynamics, achieving better performance across downstream tasks.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
MultiEdit: Advancing Instruction-based Image Editing on Diverse and Challenging Tasks
Sep 18, 2025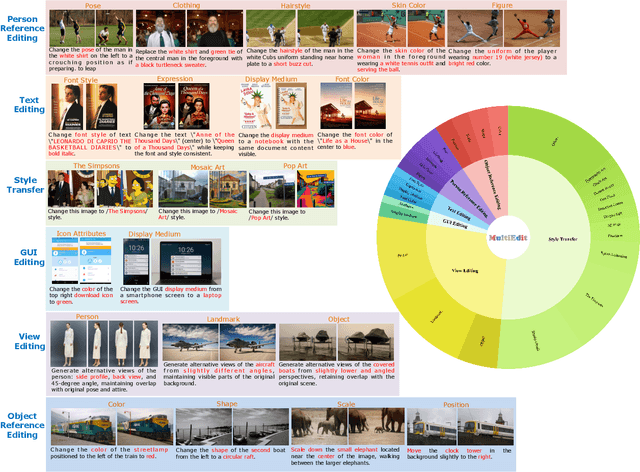
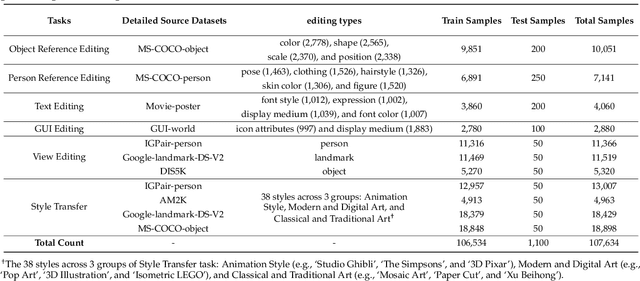
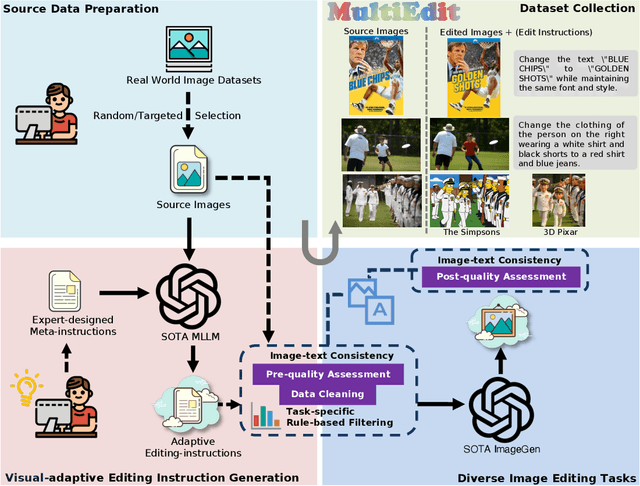
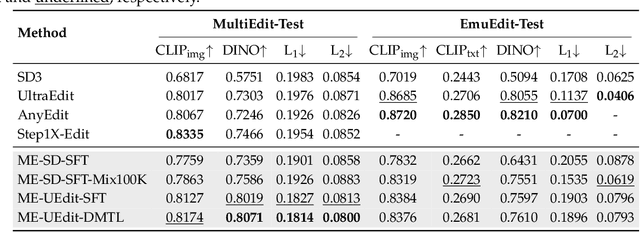
Current instruction-based image editing (IBIE) methods struggle with challenging editing tasks, as both editing types and sample counts of existing datasets are limited. Moreover, traditional dataset construction often contains noisy image-caption pairs, which may introduce biases and limit model capabilities in complex editing scenarios. To address these limitations, we introduce MultiEdit, a comprehensive dataset featuring over 107K high-quality image editing samples. It encompasses 6 challenging editing tasks through a diverse collection of 18 non-style-transfer editing types and 38 style transfer operations, covering a spectrum from sophisticated style transfer to complex semantic operations like person reference editing and in-image text editing. We employ a novel dataset construction pipeline that utilizes two multi-modal large language models (MLLMs) to generate visual-adaptive editing instructions and produce high-fidelity edited images, respectively. Extensive experiments demonstrate that fine-tuning foundational open-source models with our MultiEdit-Train set substantially improves models' performance on sophisticated editing tasks in our proposed MultiEdit-Test benchmark, while effectively preserving their capabilities on the standard editing benchmark. We believe MultiEdit provides a valuable resource for advancing research into more diverse and challenging IBIE capabilities. Our dataset is available at https://huggingface.co/datasets/inclusionAI/MultiEdit.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
Aug 11, 2025The Mixture of Experts (MoE) architecture is a cornerstone of modern state-of-the-art (SOTA) large language models (LLMs). MoE models facilitate scalability by enabling sparse parameter activation. However, traditional MoE architecture uses homogeneous experts of a uniform size, activating a fixed number of parameters irrespective of input complexity and thus limiting computational efficiency. To overcome this limitation, we introduce Grove MoE, a novel architecture incorporating experts of varying sizes, inspired by the heterogeneous big.LITTLE CPU architecture. This architecture features novel adjugate experts with a dynamic activation mechanism, enabling model capacity expansion while maintaining manageable computational overhead. Building on this architecture, we present GroveMoE-Base and GroveMoE-Inst, 33B-parameter LLMs developed by applying an upcycling strategy to the Qwen3-30B-A3B-Base model during mid-training and post-training. GroveMoE models dynamically activate 3.14-3.28B parameters based on token complexity and achieve performance comparable to SOTA open-source models of similar or even larger size.