 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Open-Vocabulary Object Detection through Multi-Level Fine-Grained Visual-Language Alignment
Jan 31, 2026Traditional object detection systems are typically constrained to predefined categories, limiting their applicability in dynamic environments. In contrast, open-vocabulary object detection (OVD) enables the identification of objects from novel classes not present in the training set. Recent advances in visual-language modeling have led to significant progress of OVD. However, prior works face challenges in either adapting the single-scale image backbone from CLIP to the detection framework or ensuring robust visual-language alignment. We propose Visual-Language Detection (VLDet), a novel framework that revamps feature pyramid for fine-grained visual-language alignment, leading to improved OVD performance. With the VL-PUB module, VLDet effectively exploits the visual-language knowledge from CLIP and adapts the backbone for object detection through feature pyramid. In addition, we introduce the SigRPN block, which incorporates a sigmoid-based anchor-text contrastive alignment loss to improve detection of novel categories. Through extensive experiments, our approach achieves 58.7 AP for novel classes on COCO2017 and 24.8 AP on LVIS, surpassing all state-of-the-art methods and achieving significant improvements of 27.6% and 6.9%, respectively. Furthermore, VLDet also demonstrates superior zero-shot performance on closed-set object detection.
Nova: An Iterative Planning and Search Approach to Enhance Novelty and Diversity of LLM Generated Ideas
Oct 18, 2024Scientific innovation is pivotal for humanity, and harnessing large language models (LLMs) to generate research ideas could transform discovery. However, existing LLMs often produce simplistic and repetitive suggestions due to their limited ability in acquiring external knowledge for innovation. To address this problem, we introduce an enhanced planning and search methodology designed to boost the creative potential of LLM-based systems. Our approach involves an iterative process to purposely plan the retrieval of external knowledge, progressively enriching the idea generation with broader and deeper insights. Validation through automated and human assessments indicates that our framework substantially elevates the quality of generated ideas, particularly in novelty and diversity. The number of unique novel ideas produced by our framework is 3.4 times higher than without it. Moreover, our method outperforms the current state-of-the-art, generating at least 2.5 times more top-rated ideas based on 170 seed papers in a Swiss Tournament evaluation.
CBARF: Cascaded Bundle-Adjusting Neural Radiance Fields from Imperfect Camera Poses
Oct 15, 2023



Existing volumetric neural rendering techniques, such as Neural Radiance Fields (NeRF), face limitations in synthesizing high-quality novel views when the camera poses of input images are imperfect. To address this issue, we propose a novel 3D reconstruction framework that enables simultaneous optimization of camera poses, dubbed CBARF (Cascaded Bundle-Adjusting NeRF).In a nutshell, our framework optimizes camera poses in a coarse-to-fine manner and then reconstructs scenes based on the rectified poses. It is observed that the initialization of camera poses has a significant impact on the performance of bundle-adjustment (BA). Therefore, we cascade multiple BA modules at different scales to progressively improve the camera poses. Meanwhile, we develop a neighbor-replacement strategy to further optimize the results of BA in each stage. In this step, we introduce a novel criterion to effectively identify poorly estimated camera poses. Then we replace them with the poses of neighboring cameras, thus further eliminating the impact of inaccurate camera poses. Once camera poses have been optimized, we employ a density voxel grid to generate high-quality 3D reconstructed scenes and images in novel views. Experimental results demonstrate that our CBARF model achieves state-of-the-art performance in both pose optimization and novel view synthesis, especially in the existence of large camera pose noise.
Acceleration of Subspace Learning Machine via Particle Swarm Optimization and Parallel Processing
Aug 15, 2022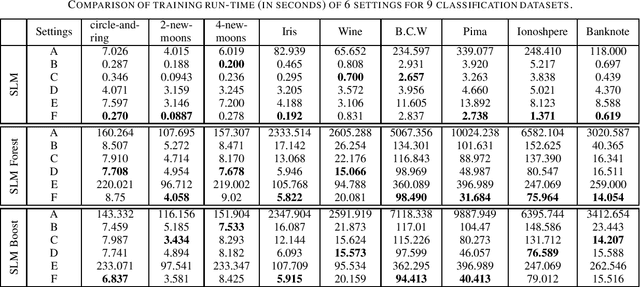
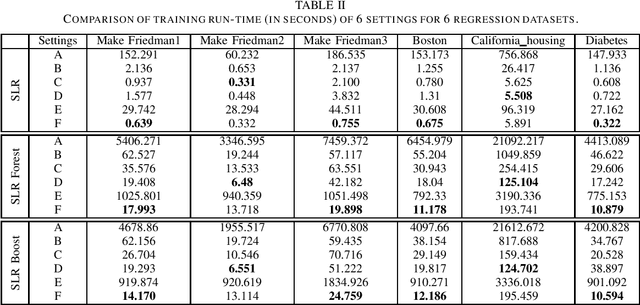


Built upon the decision tree (DT) classification and regression idea, the subspace learning machine (SLM) has been recently proposed to offer higher performance in general classification and regression tasks. Its performance improvement is reached at the expense of higher computational complexity. In this work, we investigate two ways to accelerate SLM. First, we adopt the particle swarm optimization (PSO) algorithm to speed up the search of a discriminant dimension that is expressed as a linear combination of current dimensions. The search of optimal weights in the linear combination is computationally heavy. It is accomplished by probabilistic search in original SLM. The acceleration of SLM by PSO requires 10-20 times fewer iterations. Second, we leverage parallel processing in the SLM implementation. Experimental results show that the accelerated SLM method achieves a speed up factor of 577 in training time while maintaining comparable classification/regression performance of original SLM.
GUSOT: Green and Unsupervised Single Object Tracking for Long Video Sequences
Jul 15, 2022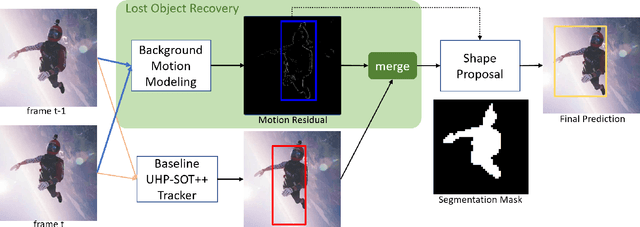
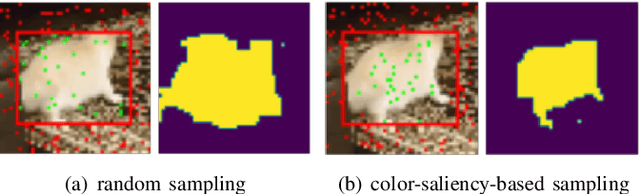
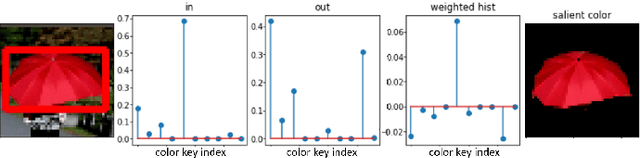
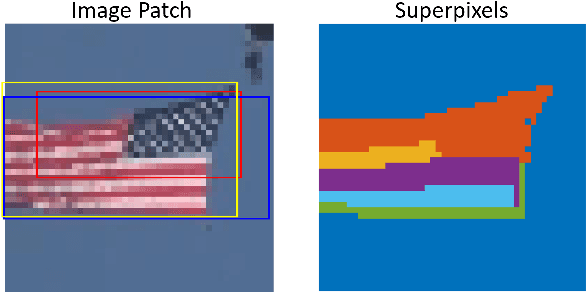
Supervised and unsupervised deep trackers that rely on deep learning technologies are popular in recent years. Yet, they demand high computational complexity and a high memory cost. A green unsupervised single-object tracker, called GUSOT, that aims at object tracking for long videos under a resource-constrained environment is proposed in this work. Built upon a baseline tracker, UHP-SOT++, which works well for short-term tracking, GUSOT contains two additional new modules: 1) lost object recovery, and 2) color-saliency-based shape proposal. They help resolve the tracking loss problem and offer a more flexible object proposal, respectively. Thus, they enable GUSOT to achieve higher tracking accuracy in the long run. We conduct experiments on the large-scale dataset LaSOT with long video sequences, and show that GUSOT offers a lightweight high-performance tracking solution that finds applications in mobile and edge computing platforms.
Design of Supervision-Scalable Learning Systems: Methodology and Performance Benchmarking
Jun 18, 2022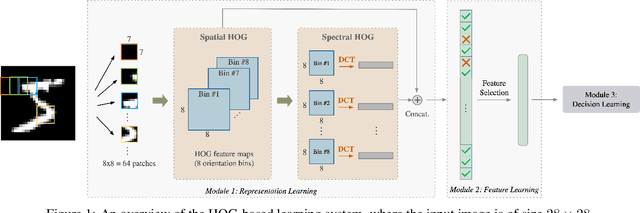
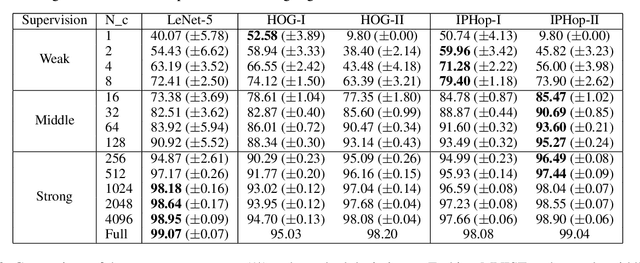
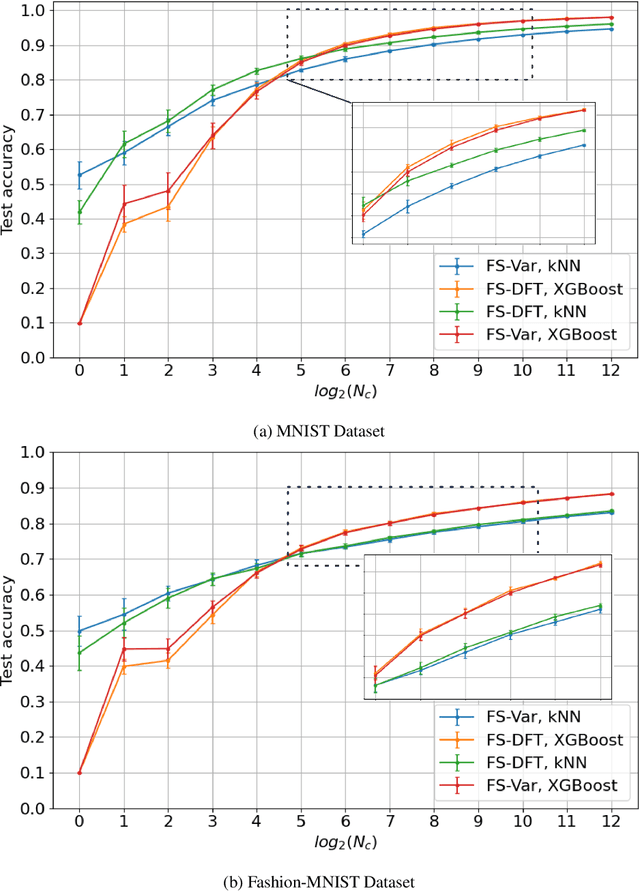
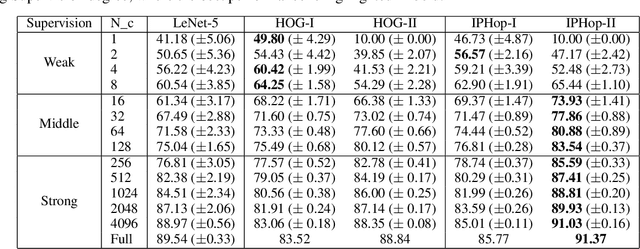
The design of robust learning systems that offer stable performance under a wide range of supervision degrees is investigated in this work. We choose the image classification problem as an illustrative example and focus on the design of modularized systems that consist of three learning modules: representation learning, feature learning and decision learning. We discuss ways to adjust each module so that the design is robust with respect to different training sample numbers. Based on these ideas, we propose two families of learning systems. One adopts the classical histogram of oriented gradients (HOG) features while the other uses successive-subspace-learning (SSL) features. We test their performance against LeNet-5, which is an end-to-end optimized neural network, for MNIST and Fashion-MNIST datasets. The number of training samples per image class goes from the extremely weak supervision condition (i.e., 1 labeled sample per class) to the strong supervision condition (i.e., 4096 labeled sample per class) with gradual transition in between (i.e., $2^n$, $n=0, 1, \cdots, 12$). Experimental results show that the two families of modularized learning systems have more robust performance than LeNet-5. They both outperform LeNet-5 by a large margin for small $n$ and have performance comparable with that of LeNet-5 for large $n$.
Subspace Learning Machine (SLM): Methodology and Performance
May 11, 2022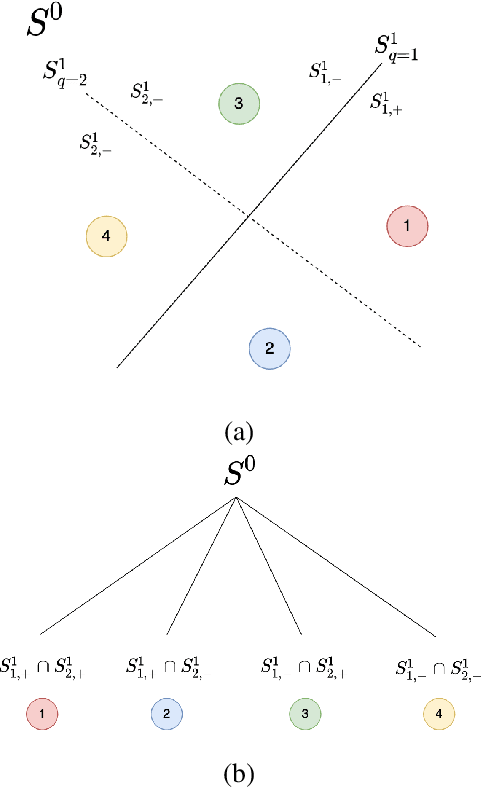
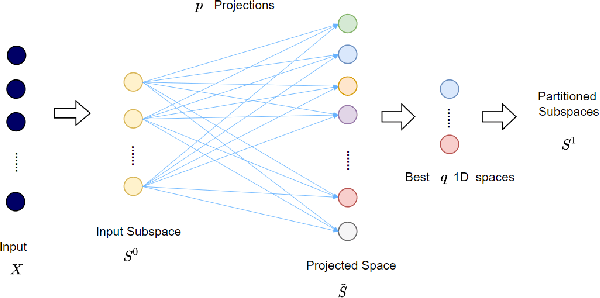
Inspired by the feedforward multilayer perceptron (FF-MLP), decision tree (DT) and extreme learning machine (ELM), a new classification model, called the subspace learning machine (SLM), is proposed in this work. SLM first identifies a discriminant subspace, $S^0$, by examining the discriminant power of each input feature. Then, it uses probabilistic projections of features in $S^0$ to yield 1D subspaces and finds the optimal partition for each of them. This is equivalent to partitioning $S^0$ with hyperplanes. A criterion is developed to choose the best $q$ partitions that yield $2q$ partitioned subspaces among them. We assign $S^0$ to the root node of a decision tree and the intersections of $2q$ subspaces to its child nodes of depth one. The partitioning process is recursively applied at each child node to build an SLM tree. When the samples at a child node are sufficiently pure, the partitioning process stops and each leaf node makes a prediction. The idea can be generalized to regression, leading to the subspace learning regressor (SLR). Furthermore, ensembles of SLM/SLR trees can yield a stronger predictor. Extensive experiments are conducted for performance benchmarking among SLM/SLR trees, ensembles and classical classifiers/regressors.
On Supervised Feature Selection from High Dimensional Feature Spaces
Mar 22, 2022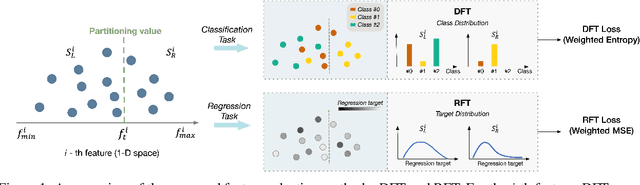
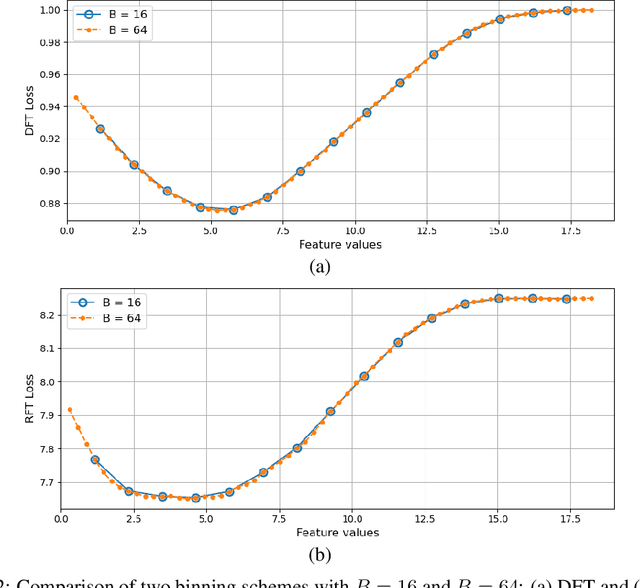
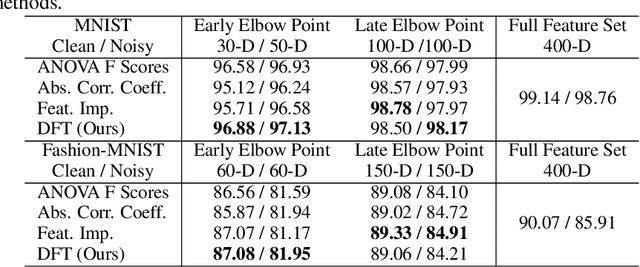
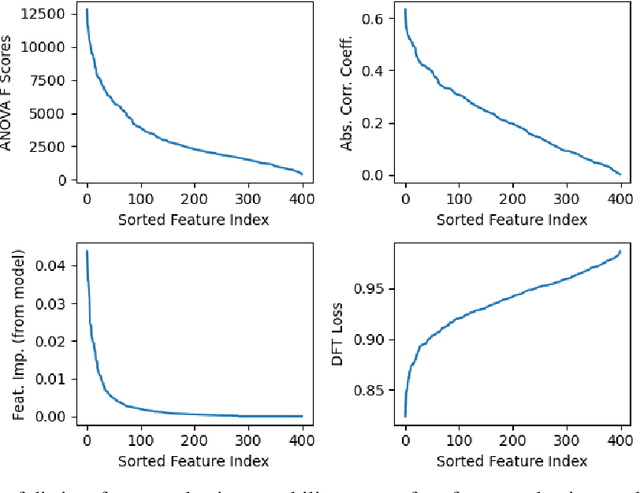
The application of machine learning to image and video data often yields a high dimensional feature space. Effective feature selection techniques identify a discriminant feature subspace that lowers computational and modeling costs with little performance degradation. A novel supervised feature selection methodology is proposed for machine learning decisions in this work. The resulting tests are called the discriminant feature test (DFT) and the relevant feature test (RFT) for the classification and regression problems, respectively. The DFT and RFT procedures are described in detail. Furthermore, we compare the effectiveness of DFT and RFT with several classic feature selection methods. To this end, we use deep features obtained by LeNet-5 for MNIST and Fashion-MNIST datasets as illustrative examples. It is shown by experimental results that DFT and RFT can select a lower dimensional feature subspace distinctly and robustly while maintaining high decision performance.
Unsupervised Lightweight Single Object Tracking with UHP-SOT++
Nov 15, 2021



An unsupervised, lightweight and high-performance single object tracker, called UHP-SOT, was proposed by Zhou et al. recently. As an extension, we present an enhanced version and name it UHP-SOT++ in this work. Built upon the foundation of the discriminative-correlation-filters-based (DCF-based) tracker, two new ingredients are introduced in UHP-SOT and UHP-SOT++: 1) background motion modeling and 2) object box trajectory modeling. The main difference between UHP-SOT and UHP-SOT++ is the fusion strategy of proposals from three models (i.e., DCF, background motion and object box trajectory models). An improved fusion strategy is adopted by UHP-SOT++ for more robust tracking performance against large-scale tracking datasets. Our second contribution lies in an extensive evaluation of the performance of state-of-the-art supervised and unsupervised methods by testing them on four SOT benchmark datasets - OTB2015, TC128, UAV123 and LaSOT. Experiments show that UHP-SOT++ outperforms all previous unsupervised methods and several deep-learning (DL) methods in tracking accuracy. Since UHP-SOT++ has extremely small model size, high tracking performance, and low computational complexity (operating at a rate of 20 FPS on an i5 CPU even without code optimization), it is an ideal solution in real-time object tracking on resource-limited platforms. Based on the experimental results, we compare pros and cons of supervised and unsupervised trackers and provide a new perspective to understand the performance gap between supervised and unsupervised methods, which is the third contribution of this work.
UHP-SOT: An Unsupervised High-Performance Single Object Tracker
Oct 05, 2021



An unsupervised online object tracking method that exploits both foreground and background correlations is proposed and named UHP-SOT (Unsupervised High-Performance Single Object Tracker) in this work. UHP-SOT consists of three modules: 1) appearance model update, 2) background motion modeling, and 3) trajectory-based box prediction. A state-of-the-art discriminative correlation filters (DCF) based tracker is adopted by UHP-SOT as the first module. We point out shortcomings of using the first module alone such as failure in recovering from tracking loss and inflexibility in object box adaptation and then propose the second and third modules to overcome them. Both are novel in single object tracking (SOT). We test UHP-SOT on two popular object tracking benchmarks, TB-50 and TB-100, and show that it outperforms all previous unsupervised SOT methods, achieves a performance comparable with the best supervised deep-learning-based SOT methods, and operates at a fast speed (i.e. 22.7-32.0 FPS on a CPU).