 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
PCa-RadHop: A Transparent and Lightweight Feed-forward Method for Clinically Significant Prostate Cancer Segmentation
Mar 24, 2024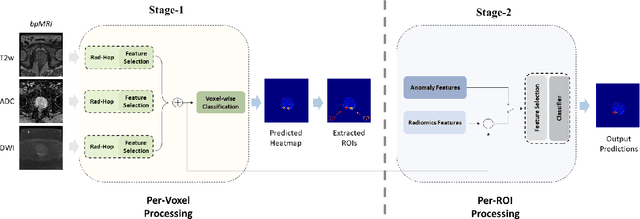



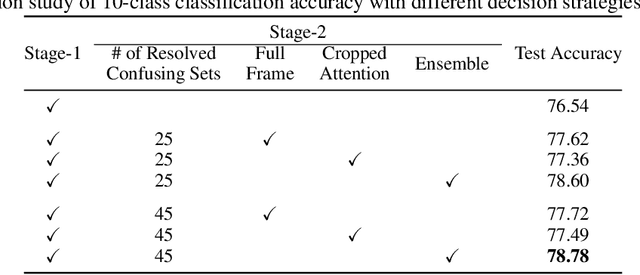
Prostate Cancer is one of the most frequently occurring cancers in men, with a low survival rate if not early diagnosed. PI-RADS reading has a high false positive rate, thus increasing the diagnostic incurred costs and patient discomfort. Deep learning (DL) models achieve a high segmentation performance, although require a large model size and complexity. Also, DL models lack of feature interpretability and are perceived as ``black-boxes" in the medical field. PCa-RadHop pipeline is proposed in this work, aiming to provide a more transparent feature extraction process using a linear model. It adopts the recently introduced Green Learning (GL) paradigm, which offers a small model size and low complexity. PCa-RadHop consists of two stages: Stage-1 extracts data-driven radiomics features from the bi-parametric Magnetic Resonance Imaging (bp-MRI) input and predicts an initial heatmap. To reduce the false positive rate, a subsequent stage-2 is introduced to refine the predictions by including more contextual information and radiomics features from each already detected Region of Interest (ROI). Experiments on the largest publicly available dataset, PI-CAI, show a competitive performance standing of the proposed method among other deep DL models, achieving an area under the curve (AUC) of 0.807 among a cohort of 1,000 patients. Moreover, PCa-RadHop maintains orders of magnitude smaller model size and complexity.
PSHop: A Lightweight Feed-Forward Method for 3D Prostate Gland Segmentation
Mar 24, 2024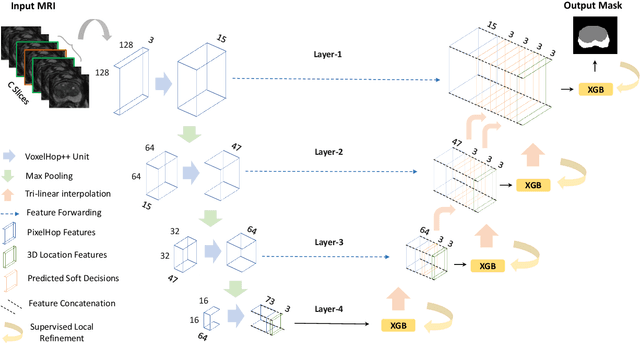

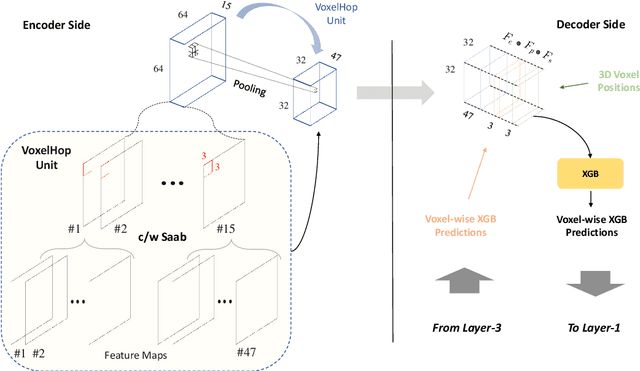
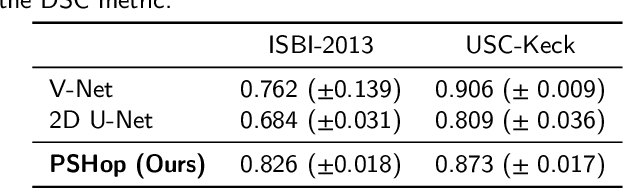
Automatic prostate segmentation is an important step in computer-aided diagnosis of prostate cancer and treatment planning. Existing methods of prostate segmentation are based on deep learning models which have a large size and lack of transparency which is essential for physicians. In this paper, a new data-driven 3D prostate segmentation method on MRI is proposed, named PSHop. Different from deep learning based methods, the core methodology of PSHop is a feed-forward encoder-decoder system based on successive subspace learning (SSL). It consists of two modules: 1) encoder: fine to coarse unsupervised representation learning with cascaded VoxelHop units, 2) decoder: coarse to fine segmentation prediction with voxel-wise classification and local refinement. Experiments are conducted on the publicly available ISBI-2013 dataset, as well as on a larger private one. Experimental analysis shows that our proposed PSHop is effective, robust and lightweight in the tasks of prostate gland and zonal segmentation, achieving a Dice Similarity Coefficient (DSC) of 0.873 for the gland segmentation task. PSHop achieves a competitive performance comparatively to other deep learning methods, while keeping the model size and inference complexity an order of magnitude smaller.
DECO: Query-Based End-to-End Object Detection with ConvNets
Dec 21, 2023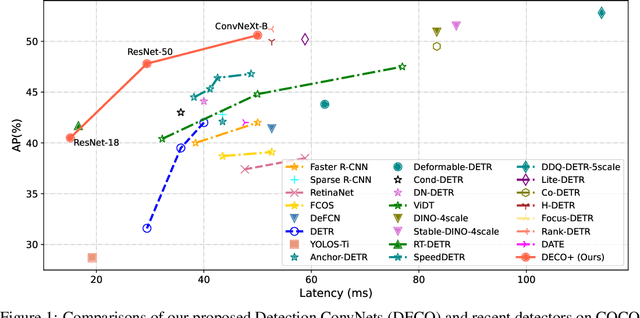
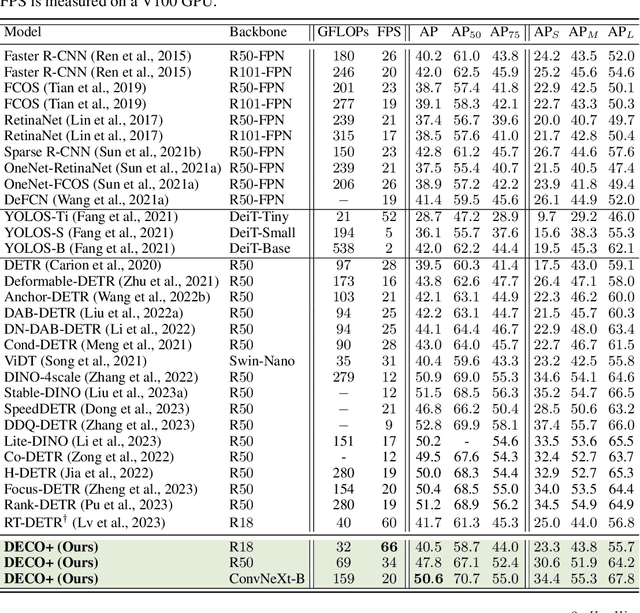
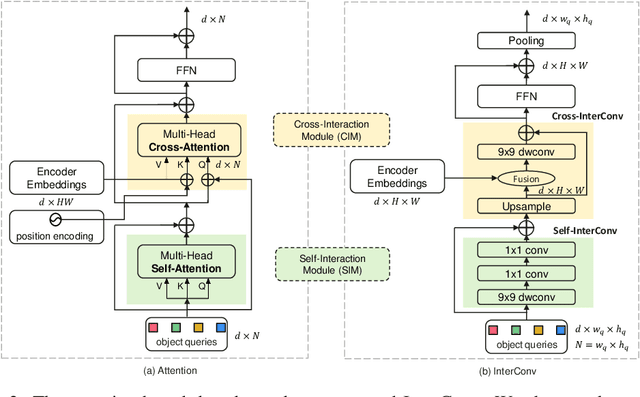
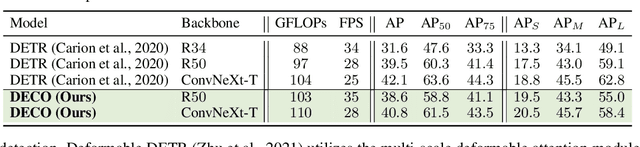
Detection Transformer (DETR) and its variants have shown great potential for accurate object detection in recent years. The mechanism of object query enables DETR family to directly obtain a fixed number of object predictions and streamlines the detection pipeline. Meanwhile, recent studies also reveal that with proper architecture design, convolution networks (ConvNets) also achieve competitive performance with transformers, \eg, ConvNeXt. To this end, in this paper we explore whether we could build a query-based end-to-end object detection framework with ConvNets instead of sophisticated transformer architecture. The proposed framework, \ie, Detection ConvNet (DECO), is composed of a backbone and convolutional encoder-decoder architecture. We carefully design the DECO encoder and propose a novel mechanism for our DECO decoder to perform interaction between object queries and image features via convolutional layers. We compare the proposed DECO against prior detectors on the challenging COCO benchmark. Despite its simplicity, our DECO achieves competitive performance in terms of detection accuracy and running speed. Specifically, with the ResNet-50 and ConvNeXt-Tiny backbone, DECO obtains $38.6\%$ and $40.8\%$ AP on COCO \textit{val} set with $35$ and $28$ FPS respectively and outperforms the DETR model. Incorporated with advanced multi-scale feature module, our DECO+ achieves $47.8\%$ AP with $34$ FPS. We hope the proposed DECO brings another perspective for designing object detection framework.
Acceleration of Subspace Learning Machine via Particle Swarm Optimization and Parallel Processing
Aug 15, 2022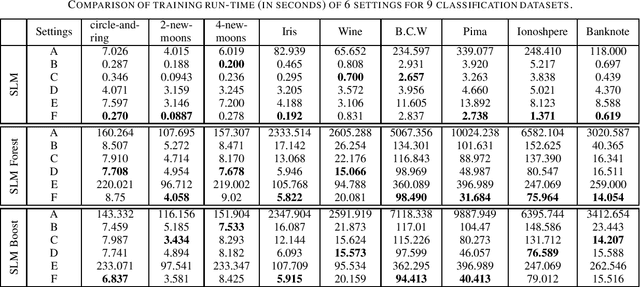


Built upon the decision tree (DT) classification and regression idea, the subspace learning machine (SLM) has been recently proposed to offer higher performance in general classification and regression tasks. Its performance improvement is reached at the expense of higher computational complexity. In this work, we investigate two ways to accelerate SLM. First, we adopt the particle swarm optimization (PSO) algorithm to speed up the search of a discriminant dimension that is expressed as a linear combination of current dimensions. The search of optimal weights in the linear combination is computationally heavy. It is accomplished by probabilistic search in original SLM. The acceleration of SLM by PSO requires 10-20 times fewer iterations. Second, we leverage parallel processing in the SLM implementation. Experimental results show that the accelerated SLM method achieves a speed up factor of 577 in training time while maintaining comparable classification/regression performance of original SLM.
Statistical Attention Localization (SAL): Methodology and Application to Object Classification
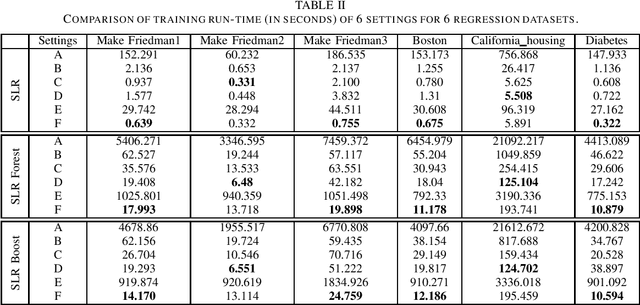
Aug 03, 2022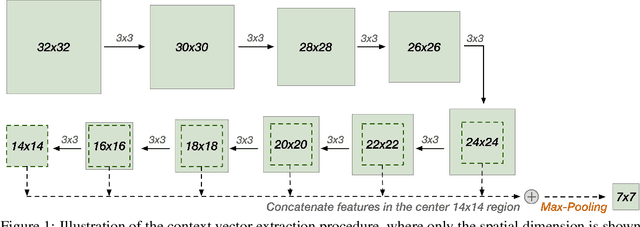
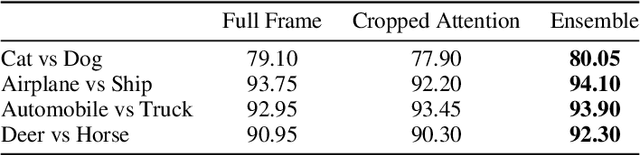
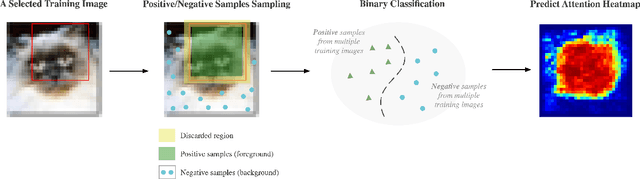
A statistical attention localization (SAL) method is proposed to facilitate the object classification task in this work. SAL consists of three steps: 1) preliminary attention window selection via decision statistics, 2) attention map refinement, and 3) rectangular attention region finalization. SAL computes soft-decision scores of local squared windows and uses them to identify salient regions in Step 1. To accommodate object of various sizes and shapes, SAL refines the preliminary result and obtain an attention map of more flexible shape in Step 2. Finally, SAL yields a rectangular attention region using the refined attention map and bounding box regularization in Step 3. As an application, we adopt E-PixelHop, which is an object classification solution based on successive subspace learning (SSL), as the baseline. We apply SAL so as to obtain a cropped-out and resized attention region as an alternative input. Classification results of the whole image as well as the attention region are ensembled to achieve the highest classification accuracy. Experiments on the CIFAR-10 dataset are given to demonstrate the advantage of the SAL-assisted object classification method.
Design of Supervision-Scalable Learning Systems: Methodology and Performance Benchmarking
Jun 18, 2022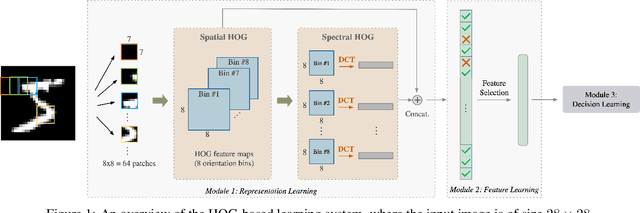
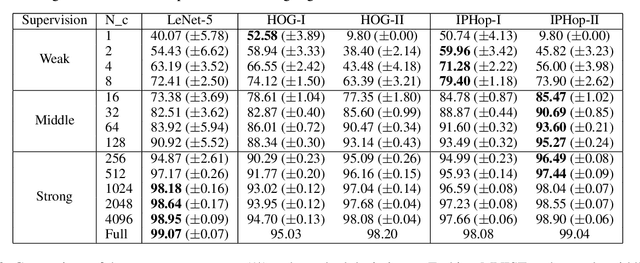
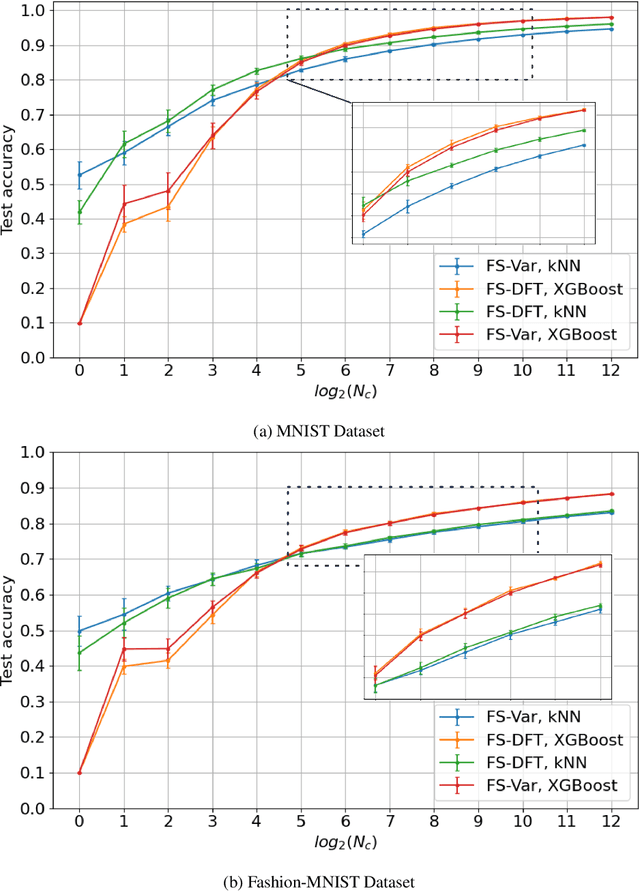
The design of robust learning systems that offer stable performance under a wide range of supervision degrees is investigated in this work. We choose the image classification problem as an illustrative example and focus on the design of modularized systems that consist of three learning modules: representation learning, feature learning and decision learning. We discuss ways to adjust each module so that the design is robust with respect to different training sample numbers. Based on these ideas, we propose two families of learning systems. One adopts the classical histogram of oriented gradients (HOG) features while the other uses successive-subspace-learning (SSL) features. We test their performance against LeNet-5, which is an end-to-end optimized neural network, for MNIST and Fashion-MNIST datasets. The number of training samples per image class goes from the extremely weak supervision condition (i.e., 1 labeled sample per class) to the strong supervision condition (i.e., 4096 labeled sample per class) with gradual transition in between (i.e., $2^n$, $n=0, 1, \cdots, 12$). Experimental results show that the two families of modularized learning systems have more robust performance than LeNet-5. They both outperform LeNet-5 by a large margin for small $n$ and have performance comparable with that of LeNet-5 for large $n$.
Subspace Learning Machine (SLM): Methodology and Performance
May 11, 2022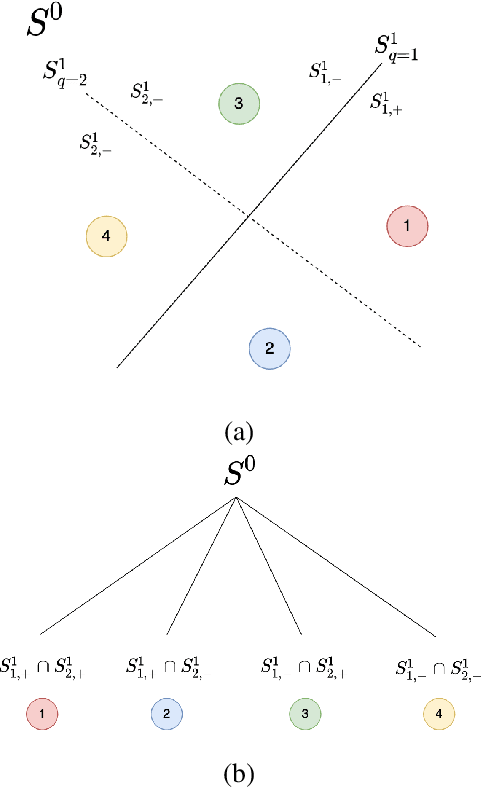
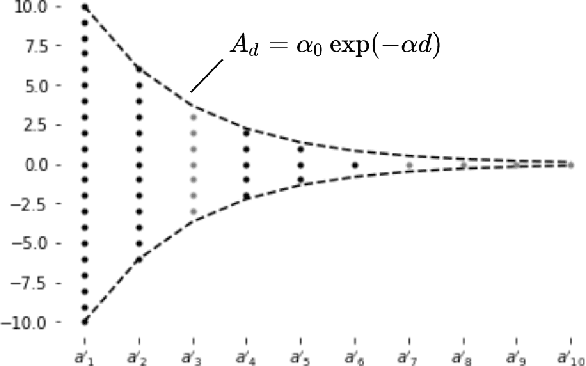
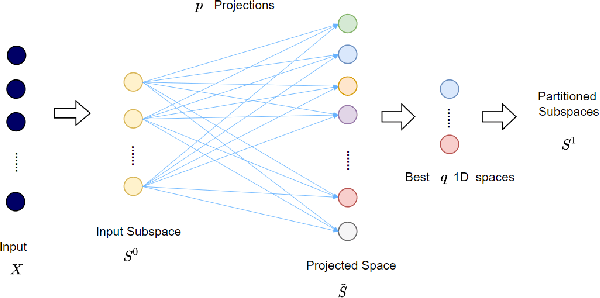
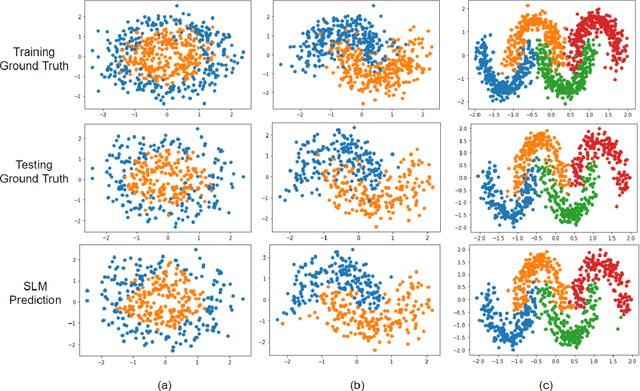
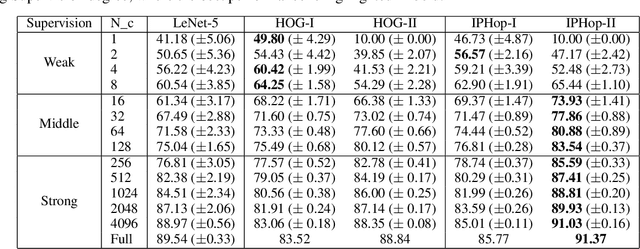
Inspired by the feedforward multilayer perceptron (FF-MLP), decision tree (DT) and extreme learning machine (ELM), a new classification model, called the subspace learning machine (SLM), is proposed in this work. SLM first identifies a discriminant subspace, $S^0$, by examining the discriminant power of each input feature. Then, it uses probabilistic projections of features in $S^0$ to yield 1D subspaces and finds the optimal partition for each of them. This is equivalent to partitioning $S^0$ with hyperplanes. A criterion is developed to choose the best $q$ partitions that yield $2q$ partitioned subspaces among them. We assign $S^0$ to the root node of a decision tree and the intersections of $2q$ subspaces to its child nodes of depth one. The partitioning process is recursively applied at each child node to build an SLM tree. When the samples at a child node are sufficiently pure, the partitioning process stops and each leaf node makes a prediction. The idea can be generalized to regression, leading to the subspace learning regressor (SLR). Furthermore, ensembles of SLM/SLR trees can yield a stronger predictor. Extensive experiments are conducted for performance benchmarking among SLM/SLR trees, ensembles and classical classifiers/regressors.
HUNIS: High-Performance Unsupervised Nuclei Instance Segmentation
Mar 28, 2022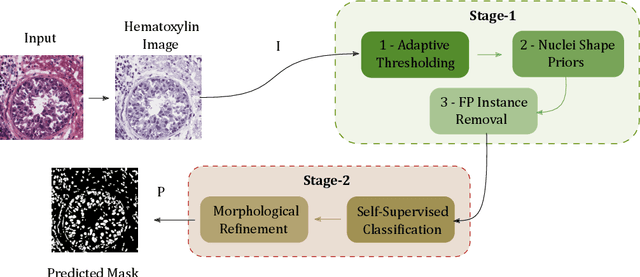
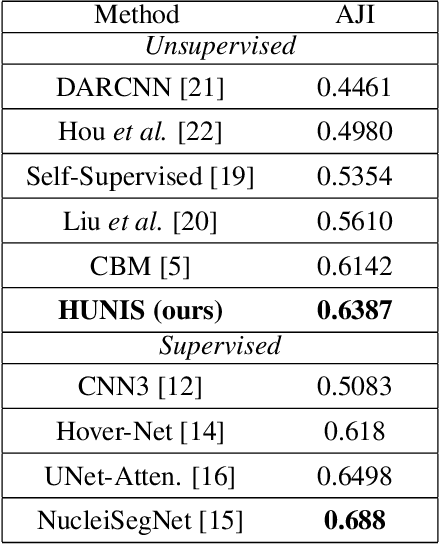
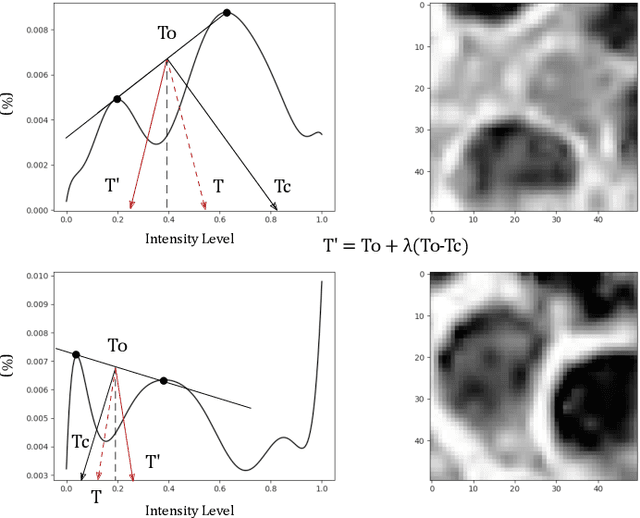
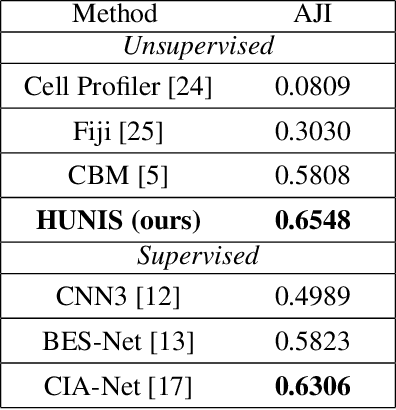
A high-performance unsupervised nuclei instance segmentation (HUNIS) method is proposed in this work. HUNIS consists of two-stage block-wise operations. The first stage includes: 1) adaptive thresholding of pixel intensities, 2) incorporation of nuclei size/shape priors and 3) removal of false positive nuclei instances. Then, HUNIS conducts the second stage segmentation by receiving guidance from the first one. The second stage exploits the segmentation masks obtained in the first stage and leverages color and shape distributions for a more accurate segmentation. The main purpose of the two-stage design is to provide pixel-wise pseudo-labels from the first to the second stage. This self-supervision mechanism is novel and effective. Experimental results on the MoNuSeg dataset show that HUNIS outperforms all other unsupervised methods by a substantial margin. It also has a competitive standing among state-of-the-art supervised methods.
On Supervised Feature Selection from High Dimensional Feature Spaces
Mar 22, 2022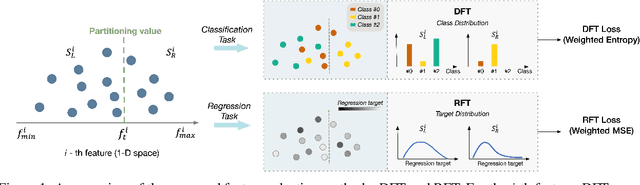
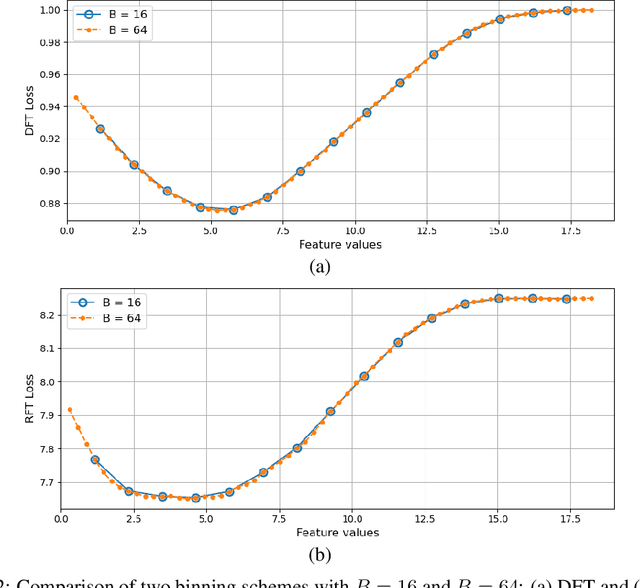
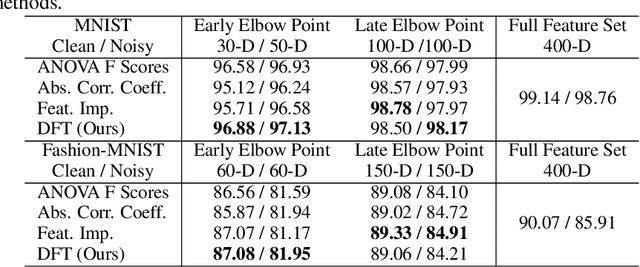
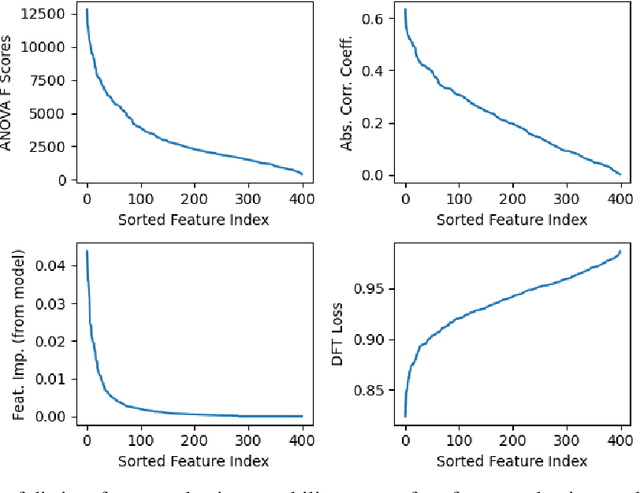
The application of machine learning to image and video data often yields a high dimensional feature space. Effective feature selection techniques identify a discriminant feature subspace that lowers computational and modeling costs with little performance degradation. A novel supervised feature selection methodology is proposed for machine learning decisions in this work. The resulting tests are called the discriminant feature test (DFT) and the relevant feature test (RFT) for the classification and regression problems, respectively. The DFT and RFT procedures are described in detail. Furthermore, we compare the effectiveness of DFT and RFT with several classic feature selection methods. To this end, we use deep features obtained by LeNet-5 for MNIST and Fashion-MNIST datasets as illustrative examples. It is shown by experimental results that DFT and RFT can select a lower dimensional feature subspace distinctly and robustly while maintaining high decision performance.