 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeaiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
Random Long-Context Access for Mamba via Hardware-aligned Hierarchical Sparse Attention
Apr 23, 2025A key advantage of Recurrent Neural Networks (RNNs) over Transformers is their linear computational and space complexity enables faster training and inference for long sequences. However, RNNs are fundamentally unable to randomly access historical context, and simply integrating attention mechanisms may undermine their efficiency advantages. To overcome this limitation, we propose \textbf{H}ierarchical \textbf{S}parse \textbf{A}ttention (HSA), a novel attention mechanism that enhances RNNs with long-range random access flexibility while preserving their merits in efficiency and length generalization. HSA divides inputs into chunks, selecting the top-$k$ chunks and hierarchically aggregates information. The core innovation lies in learning token-to-chunk relevance based on fine-grained token-level information inside each chunk. This approach enhances the precision of chunk selection across both in-domain and out-of-domain context lengths. To make HSA efficient, we further introduce a hardware-aligned kernel design. By combining HSA with Mamba, we introduce RAMba, which achieves perfect accuracy in passkey retrieval across 64 million contexts despite pre-training on only 4K-length contexts, and significant improvements on various downstream tasks, with nearly constant memory footprint. These results show RAMba's huge potential in long-context modeling.
SD-ReID: View-aware Stable Diffusion for Aerial-Ground Person Re-Identification
Apr 13, 2025Aerial-Ground Person Re-IDentification (AG-ReID) aims to retrieve specific persons across cameras with different viewpoints. Previous works focus on designing discriminative ReID models to maintain identity consistency despite drastic changes in camera viewpoints. The core idea behind these methods is quite natural, but designing a view-robust network is a very challenging task. Moreover, they overlook the contribution of view-specific features in enhancing the model's capability to represent persons. To address these issues, we propose a novel two-stage feature learning framework named SD-ReID for AG-ReID, which takes advantage of the powerful understanding capacity of generative models, e.g., Stable Diffusion (SD), to generate view-specific features between different viewpoints. In the first stage, we train a simple ViT-based model to extract coarse-grained representations and controllable conditions. Then, in the second stage, we fine-tune the SD model to learn complementary representations guided by the controllable conditions. Furthermore, we propose the View-Refine Decoder (VRD) to obtain additional controllable conditions to generate missing cross-view features. Finally, we use the coarse-grained representations and all-view features generated by SD to retrieve target persons. Extensive experiments on the AG-ReID benchmarks demonstrate the effectiveness of our proposed SD-ReID. The source code will be available upon acceptance.
LATex: Leveraging Attribute-based Text Knowledge for Aerial-Ground Person Re-Identification
Mar 31, 2025Aerial-Ground person Re-IDentification (AG-ReID) aims to retrieve specific persons across heterogeneous cameras in different views. Previous methods usually adopt large-scale models, focusing on view-invariant features. However, they overlook the semantic information in person attributes. Additionally, existing training strategies often rely on full fine-tuning large-scale models, which significantly increases training costs. To address these issues, we propose a novel framework named LATex for AG-ReID, which adopts prompt-tuning strategies to leverage attribute-based text knowledge. More specifically, we first introduce the Contrastive Language-Image Pre-training (CLIP) model as the backbone, and propose an Attribute-aware Image Encoder (AIE) to extract global semantic features and attribute-aware features. Then, with these features, we propose a Prompted Attribute Classifier Group (PACG) to generate person attribute predictions and obtain the encoded representations of predicted attributes. Finally, we design a Coupled Prompt Template (CPT) to transform attribute tokens and view information into structured sentences. These sentences are processed by the text encoder of CLIP to generate more discriminative features. As a result, our framework can fully leverage attribute-based text knowledge to improve the AG-ReID. Extensive experiments on three AG-ReID benchmarks demonstrate the effectiveness of our proposed LATex. The source code will be available.
Nova: An Iterative Planning and Search Approach to Enhance Novelty and Diversity of LLM Generated Ideas
Oct 18, 2024Scientific innovation is pivotal for humanity, and harnessing large language models (LLMs) to generate research ideas could transform discovery. However, existing LLMs often produce simplistic and repetitive suggestions due to their limited ability in acquiring external knowledge for innovation. To address this problem, we introduce an enhanced planning and search methodology designed to boost the creative potential of LLM-based systems. Our approach involves an iterative process to purposely plan the retrieval of external knowledge, progressively enriching the idea generation with broader and deeper insights. Validation through automated and human assessments indicates that our framework substantially elevates the quality of generated ideas, particularly in novelty and diversity. The number of unique novel ideas produced by our framework is 3.4 times higher than without it. Moreover, our method outperforms the current state-of-the-art, generating at least 2.5 times more top-rated ideas based on 170 seed papers in a Swiss Tournament evaluation.
Efficient Long-range Language Modeling with Self-supervised Causal Retrieval
Oct 02, 2024Recently, retrieval-based language models (RLMs) have received much attention. However, most of them leverage a pre-trained retriever with fixed parameters, which may not adapt well to causal language models. In this work, we propose Grouped Cross-Attention, a novel module enabling joint pre-training of the retriever and causal LM, and apply it to long-context modeling. For a given input sequence, we split it into chunks and use the current chunk to retrieve past chunks for subsequent text generation. Our innovation allows the retriever to learn how to retrieve past chunks that better minimize the auto-regressive loss of subsequent tokens in an end-to-end manner. By integrating top-$k$ retrieval, our model can be pre-trained efficiently from scratch with context lengths up to 64K tokens. Our experiments show our model, compared with long-range LM baselines, can achieve lower perplexity with comparable or lower pre-training and inference costs.
Unsupervised Morphological Tree Tokenizer
Jun 21, 2024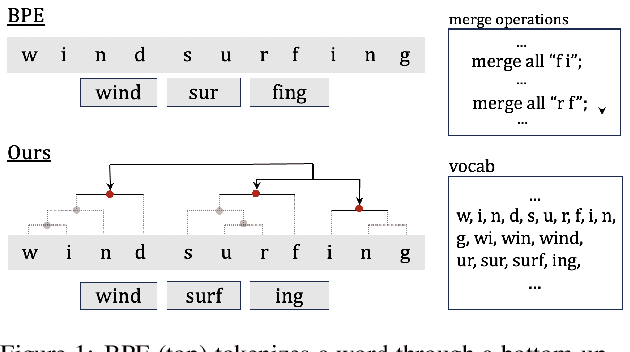
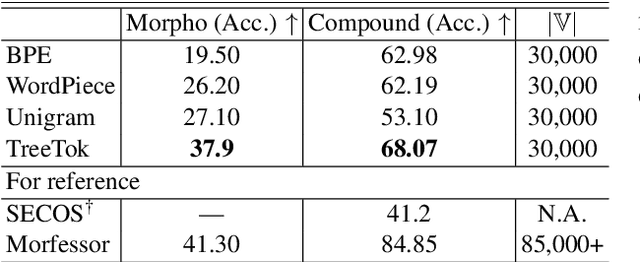
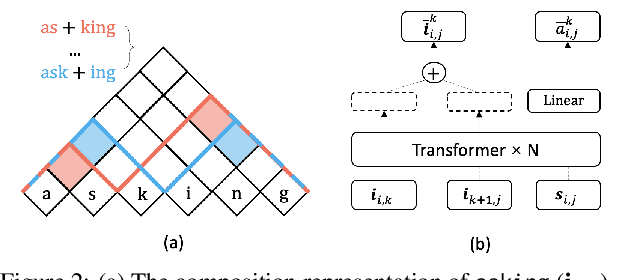
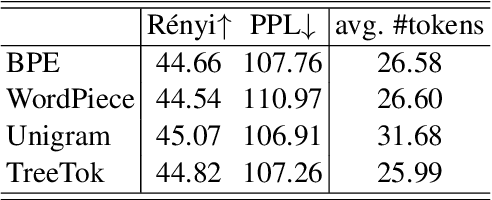
As a cornerstone in language modeling, tokenization involves segmenting text inputs into pre-defined atomic units. Conventional statistical tokenizers often disrupt constituent boundaries within words, thereby corrupting semantic information. To address this drawback, we introduce morphological structure guidance to tokenization and propose a deep model to induce character-level structures of words. Specifically, the deep model jointly encodes internal structures and representations of words with a mechanism named $\textit{MorphOverriding}$ to ensure the indecomposability of morphemes. By training the model with self-supervised objectives, our method is capable of inducing character-level structures that align with morphological rules without annotated training data. Based on the induced structures, our algorithm tokenizes words through vocabulary matching in a top-down manner. Empirical results indicate that the proposed method effectively retains complete morphemes and outperforms widely adopted methods such as BPE and WordPiece on both morphological segmentation tasks and language modeling tasks. The code will be released later.
Generative Pretrained Structured Transformers: Unsupervised Syntactic Language Models at Scale
Mar 18, 2024A syntactic language model (SLM) incrementally generates a sentence with its syntactic tree in a left-to-right manner. We present Generative Pretrained Structured Transformers (GPST), an unsupervised SLM at scale capable of being pre-trained from scratch on raw texts with high parallelism. GPST circumvents the limitations of previous SLMs such as relying on gold trees and sequential training. It consists of two components, a usual SLM supervised by a uni-directional language modeling loss, and an additional composition model, which induces syntactic parse trees and computes constituent representations, supervised by a bi-directional language modeling loss. We propose a representation surrogate to enable joint parallel training of the two models in a hard-EM fashion. We pre-train GPST on OpenWebText, a corpus with $9$ billion tokens, and demonstrate the superiority of GPST over GPT-2 with a comparable size in numerous tasks covering both language understanding and language generation. Meanwhile, GPST also significantly outperforms existing unsupervised SLMs on left-to-right grammar induction, while holding a substantial acceleration on training.
Augmenting transformers with recursively composed multi-grained representations
Sep 28, 2023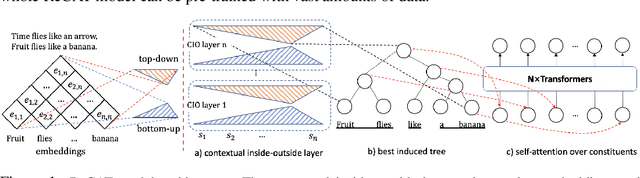

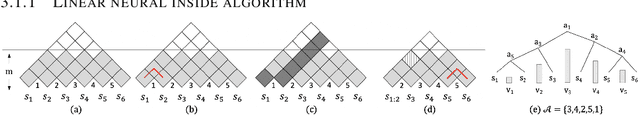
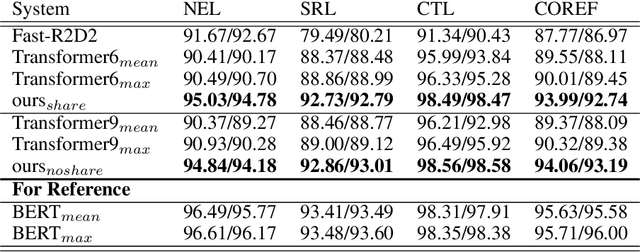
We present ReCAT, a recursive composition augmented Transformer that is able to explicitly model hierarchical syntactic structures of raw texts without relying on gold trees during both learning and inference. Existing research along this line restricts data to follow a hierarchical tree structure and thus lacks inter-span communications. To overcome the problem, we propose a novel contextual inside-outside (CIO) layer that learns contextualized representations of spans through bottom-up and top-down passes, where a bottom-up pass forms representations of high-level spans by composing low-level spans, while a top-down pass combines information inside and outside a span. By stacking several CIO layers between the embedding layer and the attention layers in Transformer, the ReCAT model can perform both deep intra-span and deep inter-span interactions, and thus generate multi-grained representations fully contextualized with other spans. Moreover, the CIO layers can be jointly pre-trained with Transformers, making ReCAT enjoy scaling ability, strong performance, and interpretability at the same time. We conduct experiments on various sentence-level and span-level tasks. Evaluation results indicate that ReCAT can significantly outperform vanilla Transformer models on all span-level tasks and baselines that combine recursive networks with Transformers on natural language inference tasks. More interestingly, the hierarchical structures induced by ReCAT exhibit strong consistency with human-annotated syntactic trees, indicating good interpretability brought by the CIO layers.
A Multi-Grained Self-Interpretable Symbolic-Neural Model For Single/Multi-Labeled Text Classification
Mar 06, 2023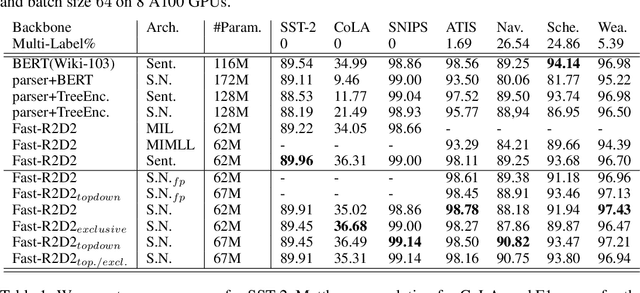
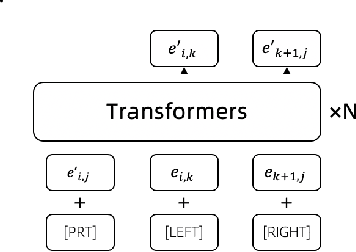
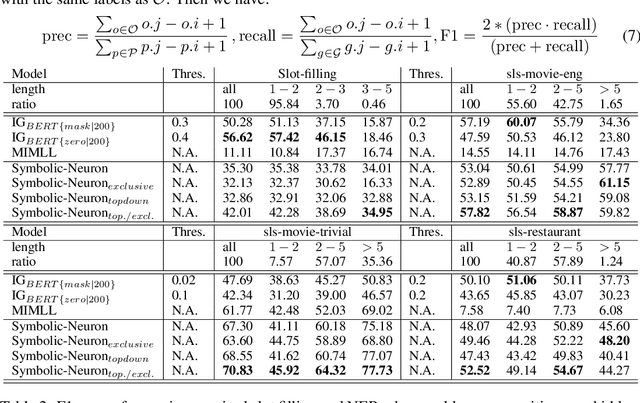

Deep neural networks based on layer-stacking architectures have historically suffered from poor inherent interpretability. Meanwhile, symbolic probabilistic models function with clear interpretability, but how to combine them with neural networks to enhance their performance remains to be explored. In this paper, we try to marry these two systems for text classification via a structured language model. We propose a Symbolic-Neural model that can learn to explicitly predict class labels of text spans from a constituency tree without requiring any access to span-level gold labels. As the structured language model learns to predict constituency trees in a self-supervised manner, only raw texts and sentence-level labels are required as training data, which makes it essentially a general constituent-level self-interpretable classification model. Our experiments demonstrate that our approach could achieve good prediction accuracy in downstream tasks. Meanwhile, the predicted span labels are consistent with human rationales to a certain degree.