 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards
Dec 25, 2025Large reasoning models (LRMs) are typically trained using reinforcement learning with verifiable reward (RLVR) to enhance their reasoning abilities. In this paradigm, policies are updated using both positive and negative self-generated rollouts, which correspond to distinct sample polarities. In this paper, we provide a systematic investigation into how these sample polarities affect RLVR training dynamics and behaviors. We find that positive samples sharpen existing correct reasoning patterns, while negative samples encourage exploration of new reasoning paths. We further explore how adjusting the advantage values of positive and negative samples at both the sample level and the token level affects RLVR training. Based on these insights, we propose an Adaptive and Asymmetric token-level Advantage shaping method for Policy Optimization, namely A3PO, that more precisely allocates advantage signals to key tokens across different polarities. Experiments across five reasoning benchmarks demonstrate the effectiveness of our approach.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Enhancing Cross-task Transfer of Large Language Models via Activation Steering
Jul 17, 2025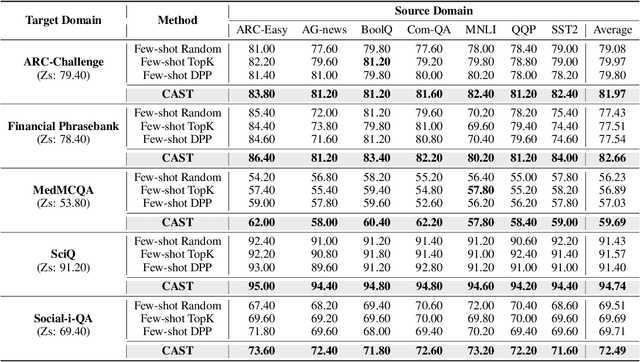
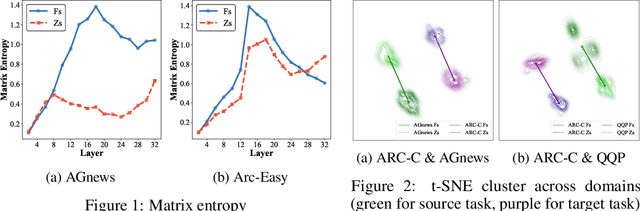

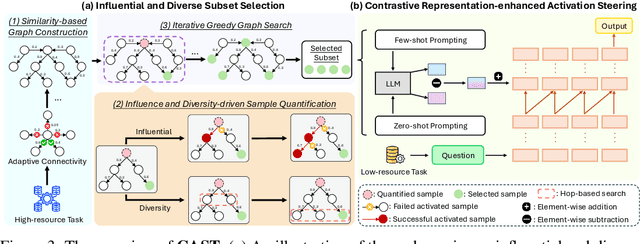
Large language models (LLMs) have shown impressive abilities in leveraging pretrained knowledge through prompting, but they often struggle with unseen tasks, particularly in data-scarce scenarios. While cross-task in-context learning offers a direct solution for transferring knowledge across tasks, it still faces critical challenges in terms of robustness, scalability, and efficiency. In this paper, we investigate whether cross-task transfer can be achieved via latent space steering without parameter updates or input expansion. Through an analysis of activation patterns in the latent space of LLMs, we observe that the enhanced activations induced by in-context examples have consistent patterns across different tasks. Inspired by these findings, we propose CAST, a novel Cross-task Activation Steering Transfer framework that enables effective transfer by manipulating the model's internal activation states. Our approach first selects influential and diverse samples from high-resource tasks, then utilizes their contrastive representation-enhanced activations to adapt LLMs to low-resource tasks. Extensive experiments across both cross-domain and cross-lingual transfer settings show that our method outperforms competitive baselines and demonstrates superior scalability and lower computational costs.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
CARE: A Clue-guided Assistant for CSRs to Read User Manuals
Aug 07, 2024



It is time-saving to build a reading assistant for customer service representations (CSRs) when reading user manuals, especially information-rich ones. Current solutions don't fit the online custom service scenarios well due to the lack of attention to user questions and possible responses. Hence, we propose to develop a time-saving and careful reading assistant for CSRs, named CARE. It can help the CSRs quickly find proper responses from the user manuals via explicit clue chains. Specifically, each of the clue chains is formed by inferring over the user manuals, starting from the question clue aligned with the user question and ending at a possible response. To overcome the shortage of supervised data, we adopt the self-supervised strategy for model learning. The offline experiment shows that CARE is efficient in automatically inferring accurate responses from the user manual. The online experiment further demonstrates the superiority of CARE to reduce CSRs' reading burden and keep high service quality, in particular with >35% decrease in time spent and keeping a >0.75 ICC score.
Hummer: Towards Limited Competitive Preference Dataset
May 21, 2024Preference datasets are essential for incorporating human preferences into pre-trained language models, playing a key role in the success of Reinforcement Learning from Human Feedback. However, these datasets often demonstrate conflicting alignment objectives, leading to increased vulnerability to jailbreak attacks and challenges in adapting downstream tasks to prioritize specific alignment objectives without negatively impacting others. In this work, we introduce a novel statistical metric, Alignment Dimension Conflict, to quantify the degree of conflict within preference datasets. We then present \texttt{Hummer} and its fine-grained variant, \texttt{Hummer-F}, as innovative pairwise preference datasets with reduced-conflict alignment objectives. \texttt{Hummer} is built based on UltraFeedback and is enhanced by AI feedback from GPT-4, marking as the first preference dataset aimed at reducing the competition between alignment objectives. Furthermore, we develop reward models, HummerRM and HummerRM-F, which employ a hybrid sampling approach to balance diverse alignment objectives effectively. This sampling method positions HummerRM as an ideal model for domain-specific further fine-tuning and reducing vulnerabilities to attacks.
Strength Lies in Differences! Towards Effective Non-collaborative Dialogues via Tailored Strategy Planning
Mar 11, 2024



We investigate non-collaborative dialogue agents that must engage in tailored strategic planning for diverse users to secure a favorable agreement. This poses challenges for existing dialogue agents due to two main reasons: their inability to integrate user-specific characteristics into their strategic planning and their training paradigm's failure to produce strategic planners that can generalize to diverse users. To address these challenges, we propose TRIP to enhance the capability in tailored strategic planning, incorporating a user-aware strategic planning module and a population-based training paradigm. Through experiments on benchmark non-collaborative dialogue tasks, we demonstrate the effectiveness of TRIP in catering to diverse users.
AMOR: A Recipe for Building Adaptable Modular Knowledge Agents Through Process Feedback
Feb 02, 2024



The notable success of large language models (LLMs) has sparked an upsurge in building language agents to complete various complex tasks. We present AMOR, an agent framework based on open-source LLMs, which reasons with external knowledge bases and adapts to specific domains through human supervision to the reasoning process. AMOR builds reasoning logic over a finite state machine (FSM) that solves problems through autonomous executions and transitions over disentangled modules. This allows humans to provide direct feedback to the individual modules, and thus naturally forms process supervision. Based on this reasoning and feedback framework, we develop AMOR through two-stage fine-tuning: warm-up and adaptation. The former fine-tunes the LLM with examples automatically constructed from various public datasets and enables AMOR to generalize across different knowledge environments, while the latter tailors AMOR to specific domains using process feedback. Extensive experiments across multiple domains demonstrate the advantage of AMOR to strong baselines, thanks to its FSM-based reasoning and process feedback mechanism.
Multi-granularity Correspondence Learning from Long-term Noisy Videos
Jan 30, 2024



Existing video-language studies mainly focus on learning short video clips, leaving long-term temporal dependencies rarely explored due to over-high computational cost of modeling long videos. To address this issue, one feasible solution is learning the correspondence between video clips and captions, which however inevitably encounters the multi-granularity noisy correspondence (MNC) problem. To be specific, MNC refers to the clip-caption misalignment (coarse-grained) and frame-word misalignment (fine-grained), hindering temporal learning and video understanding. In this paper, we propose NOise Robust Temporal Optimal traNsport (Norton) that addresses MNC in a unified optimal transport (OT) framework. In brief, Norton employs video-paragraph and clip-caption contrastive losses to capture long-term dependencies based on OT. To address coarse-grained misalignment in video-paragraph contrast, Norton filters out the irrelevant clips and captions through an alignable prompt bucket and realigns asynchronous clip-caption pairs based on transport distance. To address the fine-grained misalignment, Norton incorporates a soft-maximum operator to identify crucial words and key frames. Additionally, Norton exploits the potential faulty negative samples in clip-caption contrast by rectifying the alignment target with OT assignment to ensure precise temporal modeling. Extensive experiments on video retrieval, videoQA, and action segmentation verify the effectiveness of our method. Code is available at https://lin-yijie.github.io/projects/Norton.