 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMETRO: Towards Strategy Induction from Expert Dialogue Transcripts for Non-collaborative Dialogues
Apr 14, 2026Developing non-collaborative dialogue agents traditionally requires the manual, unscalable codification of expert strategies. We propose \ours, a method that leverages large language models to autonomously induce both strategy actions and planning logic directly from raw transcripts. METRO formalizes expert knowledge into a Strategy Forest, a hierarchical structure that captures both short-term responses (nodes) and long-term strategic foresight (branches). Experimental results across two benchmarks show that METRO demonstrates promising performance, outperforming existing methods by an average of 9%-10%. Our further analysis not only reveals the success behind METRO (strategic behavioral diversity and foresight), but also demonstrates its robust cross-task transferability. This offers new insights into building non-collaborative agents in a cost-effective and scalable way. Our code is available at https://github.com/Humphrey-0125/METRO.
Beyond Prompt: Fine-grained Simulation of Cognitively Impaired Standardized Patients via Stochastic Steering
Apr 14, 2026Simulating Standardized Patients with cognitive impairment offers a scalable and ethical solution for clinical training. However, existing methods rely on discrete prompt engineering and fail to capture the heterogeneity of deficits across varying domains and severity levels. To address this limitation, we propose StsPatient for the fine-grained simulation of cognitively impaired patients. We innovatively capture domain-specific features by extracting steering vectors from contrastive pairs of instructions and responses. Furthermore, we introduce a Stochastic Token Modulation (STM) mechanism to regulate the intervention probability. STM enables precise control over impairment severity while mitigating the instability of conventional vector methods. Comprehensive experiments demonstrate that StsPatient significantly outperforms baselines in both clinical authenticity and severity controllability.
Towards Proactive Information Probing: Customer Service Chatbots Harvesting Value from Conversation
Apr 13, 2026Customer service chatbots are increasingly expected to serve not merely as reactive support tools for users, but as strategic interfaces for harvesting high-value information and business intelligence. In response, we make three main contributions. 1) We introduce and define a novel task of Proactive Information Probing, which optimizes when to probe users for pre-specified target information while minimizing conversation turns and user friction. 2) We propose PROCHATIP, a proactive chatbot framework featuring a specialized conversation strategy module trained to master the delicate timing of probes. 3) Experiments demonstrate that PROCHATIP significantly outperforms baselines, exhibiting superior capability in both information probing and service quality. We believe that our work effectively redefines the commercial utility of chatbots, positioning them as scalable, cost-effective engines for proactive business intelligence. Our code is available at https://github.com/SCUNLP/PROCHATIP.
METER: Evaluating Multi-Level Contextual Causal Reasoning in Large Language Models
Apr 13, 2026Contextual causal reasoning is a critical yet challenging capability for Large Language Models (LLMs). Existing benchmarks, however, often evaluate this skill in fragmented settings, failing to ensure context consistency or cover the full causal hierarchy. To address this, we pioneer METER to systematically benchmark LLMs across all three levels of the causal ladder under a unified context setting. Our extensive evaluation of various LLMs reveals a significant decline in proficiency as tasks ascend the causal hierarchy. To diagnose this degradation, we conduct a deep mechanistic analysis via both error pattern identification and internal information flow tracing. Our analysis reveals two primary failure modes: (1) LLMs are susceptible to distraction by causally irrelevant but factually correct information at lower level of causality; and (2) as tasks ascend the causal hierarchy, faithfulness to the provided context degrades, leading to a reduced performance. We belive our work advances our understanding of the mechanisms behind LLM contextual causal reasoning and establishes a critical foundation for future research. Our code and dataset are available at https://github.com/SCUNLP/METER .
AMaPO: Adaptive Margin-attached Preference Optimization for Language Model Alignment
Nov 15, 2025Offline preference optimization offers a simpler and more stable alternative to RLHF for aligning language models. However, their effectiveness is critically dependent on ranking accuracy, a metric where further gains are highly impactful. This limitation arises from a fundamental problem that we identify and formalize as the Overfitting-Underfitting Dilemma: current margin designs cause models to apply excessive, wasteful gradients to correctly ranked samples (overfitting) while providing insufficient corrective signals for misranked ones (underfitting). To resolve this dilemma, we propose Adaptive Margin-attached Preference Optimization (AMaPO), a simple yet principled algorithm. AMaPO employs an instance-wise adaptive margin, refined by Z-normalization and exponential scaling, which dynamically reallocates learning effort by amplifying gradients for misranked samples and suppressing them for correct ones. Extensive experiments on widely used benchmarks demonstrate that AMaPO not only achieves better ranking accuracy and superior downstream alignment performance, but targeted analysis also confirms that it successfully mitigates the core overfitting and underfitting issues.
VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
E2Edev: Benchmarking Large Language Models in End-to-End Software Development Task
Oct 16, 2025E2EDev comprises (i) a fine-grained set of user requirements, (ii) {multiple BDD test scenarios with corresponding Python step implementations for each requirement}, and (iii) a fully automated testing pipeline built on the Behave framework. To ensure its quality while reducing the annotation effort, E2EDev leverages our proposed Human-in-the-Loop Multi-Agent Annotation Framework (HITL-MAA). {By evaluating various E2ESD frameworks and LLM backbones with E2EDev}, our analysis reveals a persistent struggle to effectively solve these tasks, underscoring the critical need for more effective and cost-efficient E2ESD solutions. Our codebase and benchmark are publicly available at https://github.com/SCUNLP/E2EDev.
SCOP: Evaluating the Comprehension Process of Large Language Models from a Cognitive View
Jun 05, 2025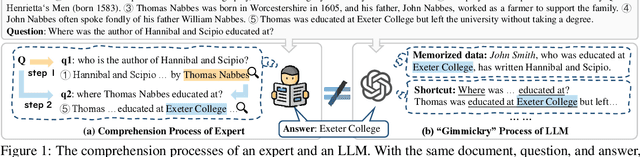

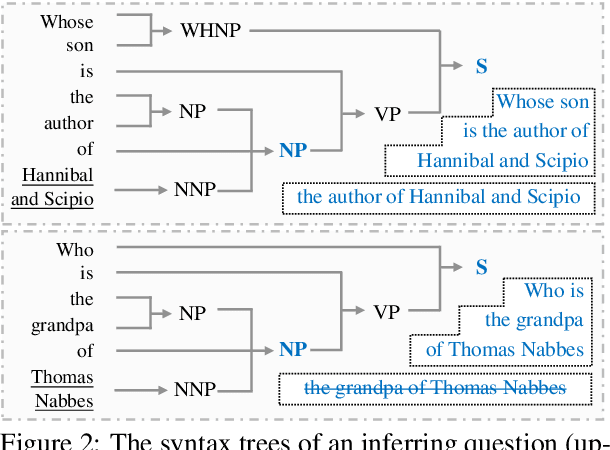

Despite the great potential of large language models(LLMs) in machine comprehension, it is still disturbing to fully count on them in real-world scenarios. This is probably because there is no rational explanation for whether the comprehension process of LLMs is aligned with that of experts. In this paper, we propose SCOP to carefully examine how LLMs perform during the comprehension process from a cognitive view. Specifically, it is equipped with a systematical definition of five requisite skills during the comprehension process, a strict framework to construct testing data for these skills, and a detailed analysis of advanced open-sourced and closed-sourced LLMs using the testing data. With SCOP, we find that it is still challenging for LLMs to perform an expert-level comprehension process. Even so, we notice that LLMs share some similarities with experts, e.g., performing better at comprehending local information than global information. Further analysis reveals that LLMs can be somewhat unreliable -- they might reach correct answers through flawed comprehension processes. Based on SCOP, we suggest that one direction for improving LLMs is to focus more on the comprehension process, ensuring all comprehension skills are thoroughly developed during training.
ELABORATION: A Comprehensive Benchmark on Human-LLM Competitive Programming
May 22, 2025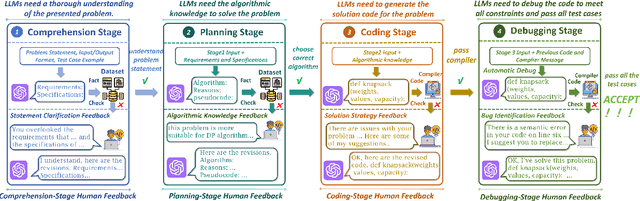
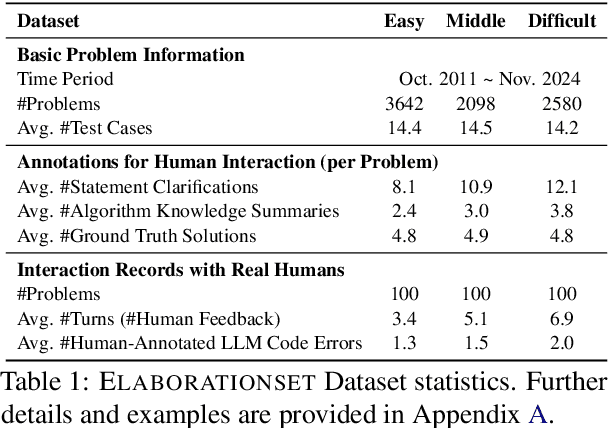

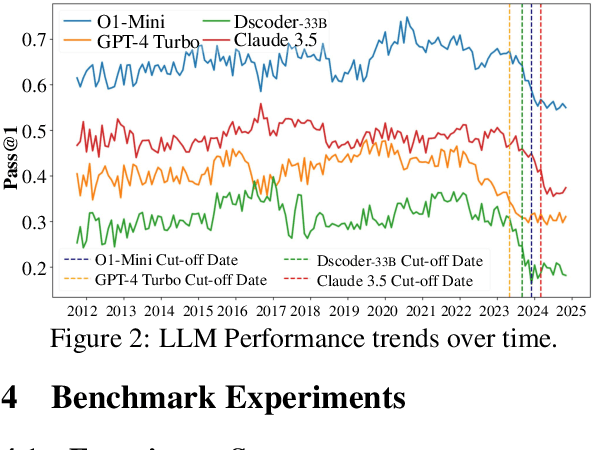
While recent research increasingly emphasizes the value of human-LLM collaboration in competitive programming and proposes numerous empirical methods, a comprehensive understanding remains elusive due to the fragmented nature of existing studies and their use of diverse, application-specific human feedback. Thus, our work serves a three-fold purpose: First, we present the first taxonomy of human feedback consolidating the entire programming process, which promotes fine-grained evaluation. Second, we introduce ELABORATIONSET, a novel programming dataset specifically designed for human-LLM collaboration, meticulously annotated to enable large-scale simulated human feedback and facilitate costeffective real human interaction studies. Third, we introduce ELABORATION, a novel benchmark to facilitate a thorough assessment of human-LLM competitive programming. With ELABORATION, we pinpoint strengthes and weaknesses of existing methods, thereby setting the foundation for future improvement. Our code and dataset are available at https://github.com/SCUNLP/ELABORATION
Can Large Language Models Understand Internet Buzzwords Through User-Generated Content
May 21, 2025The massive user-generated content (UGC) available in Chinese social media is giving rise to the possibility of studying internet buzzwords. In this paper, we study if large language models (LLMs) can generate accurate definitions for these buzzwords based on UGC as examples. Our work serves a threefold contribution. First, we introduce CHEER, the first dataset of Chinese internet buzzwords, each annotated with a definition and relevant UGC. Second, we propose a novel method, called RESS, to effectively steer the comprehending process of LLMs to produce more accurate buzzword definitions, mirroring the skills of human language learning. Third, with CHEER, we benchmark the strengths and weaknesses of various off-the-shelf definition generation methods and our RESS. Our benchmark demonstrates the effectiveness of RESS while revealing crucial shared challenges: over-reliance on prior exposure, underdeveloped inferential abilities, and difficulty identifying high-quality UGC to facilitate comprehension. We believe our work lays the groundwork for future advancements in LLM-based definition generation. Our dataset and code are available at https://github.com/SCUNLP/Buzzword.