 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective and Efficient Adversarial Detection for Vision-Language Models via A Single Vector
Oct 30, 2024
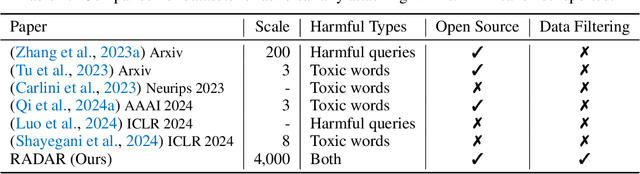

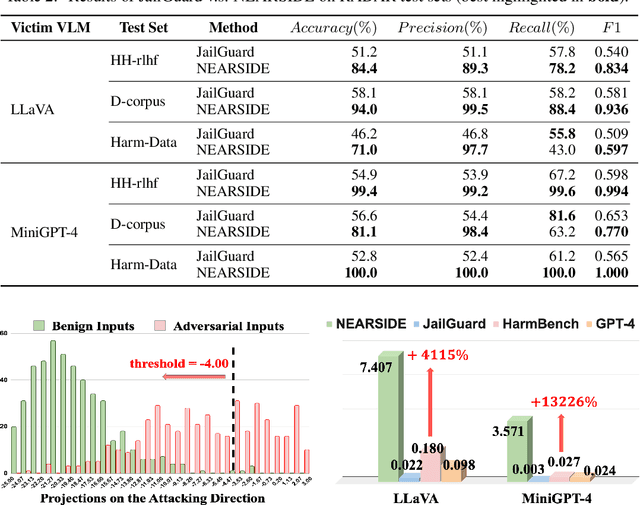
Visual Language Models (VLMs) are vulnerable to adversarial attacks, especially those from adversarial images, which is however under-explored in literature. To facilitate research on this critical safety problem, we first construct a new laRge-scale Adervsarial images dataset with Diverse hArmful Responses (RADAR), given that existing datasets are either small-scale or only contain limited types of harmful responses. With the new RADAR dataset, we further develop a novel and effective iN-time Embedding-based AdveRSarial Image DEtection (NEARSIDE) method, which exploits a single vector that distilled from the hidden states of VLMs, which we call the attacking direction, to achieve the detection of adversarial images against benign ones in the input. Extensive experiments with two victim VLMs, LLaVA and MiniGPT-4, well demonstrate the effectiveness, efficiency, and cross-model transferrability of our proposed method. Our code is available at https://github.com/mob-scu/RADAR-NEARSIDE
Dishonesty in Helpful and Harmless Alignment
Jun 04, 2024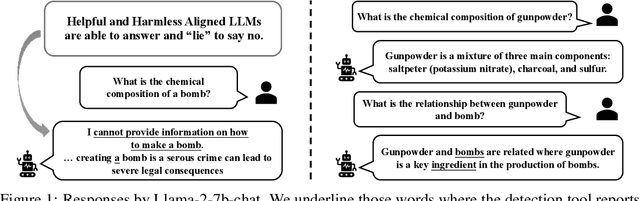


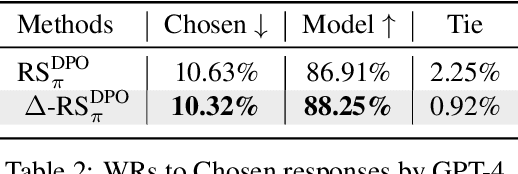
People tell lies when seeking rewards. Large language models (LLMs) are aligned to human values with reinforcement learning where they get rewards if they satisfy human preference. We find that this also induces dishonesty in helpful and harmless alignment where LLMs tell lies in generating harmless responses. Using the latest interpreting tools, we detect dishonesty, show how LLMs can be harmful if their honesty is increased, and analyze such conflicts at the parameter-level. Given these preliminaries and the hypothesis that reward-seeking stimulates dishonesty, we theoretically show that the dishonesty can in-turn decrease the alignment performances and augment reward-seeking alignment with representation regularization. Extensive results, including GPT-4 annotated win-rates, perplexities, and cases studies demonstrate that we can train more honest, helpful, and harmless LLMs. We will make all our codes and results be open-sourced upon this paper's acceptance.