 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcordia: Self-Improving Synthetic Tables for Federated LLMs
May 11, 2026Federated learning (FL) enables training large language models (LLMs) without sharing raw data, but adapting LLMs under strict data isolation and non-IID client distributions remains challenging in practice. Synthetic data offers a natural privacy-preserving surrogate for local training, yet existing federated pipelines typically treat synthetic generation as static or loosely coupled with downstream optimization, leading to rapidly diminishing utility under heterogeneous clients. We study federated adaptation of LLMs on tabular tasks where raw records and validation data cannot be shared, and local training must rely entirely on synthetic tables. We propose Concordia, a tri-level optimization framework that aligns synthetic data generation with federated validation utility despite these constraints. At the client level, models are adapted via parameter-efficient LoRA training on synthetic tables. Clients additionally learn lightweight utility scorers from private validation feedback to reweight synthetic samples during local training. At the outer level, each client refines its own synthetic table generator using group-relative policy optimization (GRPO), guided by an ensemble of heterogeneous scorers shared across clients, without aggregating generator parameters or exposing validation data. Experiments on privacy-sensitive tabular benchmarks from finance and healthcare demonstrate that Concordia consistently improves federated performance, cross-client stability, and robustness to distribution shift compared to static and decoupled synthetic-data baselines.
MicroEvoEval: A Systematic Evaluation Framework for Image-Based Microstructure Evolution Prediction
Nov 18, 2025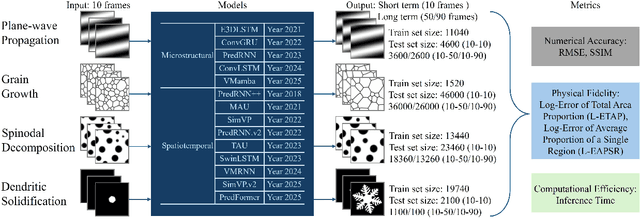
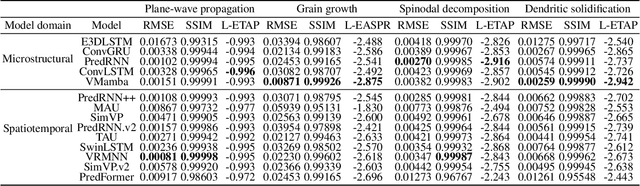
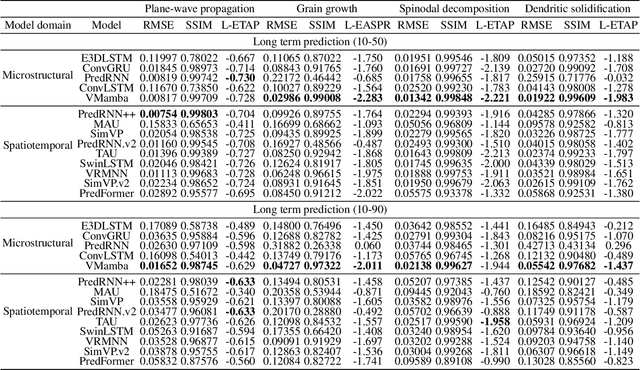

Simulating microstructure evolution (MicroEvo) is vital for materials design but demands high numerical accuracy, efficiency, and physical fidelity. Although recent studies on deep learning (DL) offer a promising alternative to traditional solvers, the field lacks standardized benchmarks. Existing studies are flawed due to a lack of comparing specialized MicroEvo DL models with state-of-the-art spatio-temporal architectures, an overemphasis on numerical accuracy over physical fidelity, and a failure to analyze error propagation over time. To address these gaps, we introduce MicroEvoEval, the first comprehensive benchmark for image-based microstructure evolution prediction. We evaluate 14 models, encompassing both domain-specific and general-purpose architectures, across four representative MicroEvo tasks with datasets specifically structured for both short- and long-term assessment. Our multi-faceted evaluation framework goes beyond numerical accuracy and computational cost, incorporating a curated set of structure-preserving metrics to assess physical fidelity. Our extensive evaluations yield several key insights. Notably, we find that modern architectures (e.g., VMamba), not only achieve superior long-term stability and physical fidelity but also operate with an order-of-magnitude greater computational efficiency. The results highlight the necessity of holistic evaluation and identify these modern architectures as a highly promising direction for developing efficient and reliable surrogate models in data-driven materials science.
AMaPO: Adaptive Margin-attached Preference Optimization for Language Model Alignment
Nov 15, 2025Offline preference optimization offers a simpler and more stable alternative to RLHF for aligning language models. However, their effectiveness is critically dependent on ranking accuracy, a metric where further gains are highly impactful. This limitation arises from a fundamental problem that we identify and formalize as the Overfitting-Underfitting Dilemma: current margin designs cause models to apply excessive, wasteful gradients to correctly ranked samples (overfitting) while providing insufficient corrective signals for misranked ones (underfitting). To resolve this dilemma, we propose Adaptive Margin-attached Preference Optimization (AMaPO), a simple yet principled algorithm. AMaPO employs an instance-wise adaptive margin, refined by Z-normalization and exponential scaling, which dynamically reallocates learning effort by amplifying gradients for misranked samples and suppressing them for correct ones. Extensive experiments on widely used benchmarks demonstrate that AMaPO not only achieves better ranking accuracy and superior downstream alignment performance, but targeted analysis also confirms that it successfully mitigates the core overfitting and underfitting issues.
Cross-model Transferability among Large Language Models on the Platonic Representations of Concepts
Jan 02, 2025



Understanding the inner workings of Large Language Models (LLMs) is a critical research frontier. Prior research has shown that a single LLM's concept representations can be captured as steering vectors (SVs), enabling the control of LLM behavior (e.g., towards generating harmful content). Our work takes a novel approach by exploring the intricate relationships between concept representations across different LLMs, drawing an intriguing parallel to Plato's Allegory of the Cave. In particular, we introduce a linear transformation method to bridge these representations and present three key findings: 1) Concept representations across different LLMs can be effectively aligned using simple linear transformations, enabling efficient cross-model transfer and behavioral control via SVs. 2) This linear transformation generalizes across concepts, facilitating alignment and control of SVs representing different concepts across LLMs. 3) A weak-to-strong transferability exists between LLM concept representations, whereby SVs extracted from smaller LLMs can effectively control the behavior of larger LLMs.
A Hybrid Loss Framework for Decomposition-based Time Series Forecasting Methods: Balancing Global and Component Errors
Nov 18, 2024Accurate time series forecasting, predicting future values based on past data, is crucial for diverse industries. Many current time series methods decompose time series into multiple sub-series, applying different model architectures and training with an end-to-end overall loss for forecasting. However, this raises a question: does this overall loss prioritize the importance of critical sub-series within the decomposition for the better performance? To investigate this, we conduct a study on the impact of overall loss on existing time series methods with sequence decomposition. Our findings reveal that overall loss may introduce bias in model learning, hindering the learning of the prioritization of more significant sub-series and limiting the forecasting performance. To address this, we propose a hybrid loss framework combining the global and component losses. This framework introduces component losses for each sub-series alongside the original overall loss. It employs a dual min-max algorithm to dynamically adjust weights between the overall loss and component losses, and within component losses. This enables the model to achieve better performance of current time series methods by focusing on more critical sub-series while still maintaining a low overall loss. We integrate our loss framework into several time series methods and evaluate the performance on multiple datasets. Results show an average improvement of 0.5-2% over existing methods without any modifications to the model architectures.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
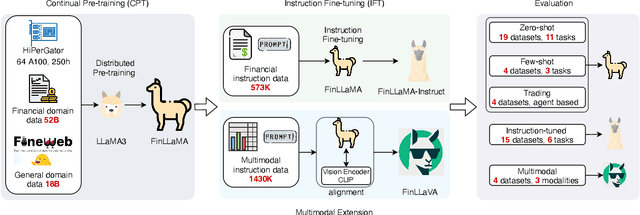
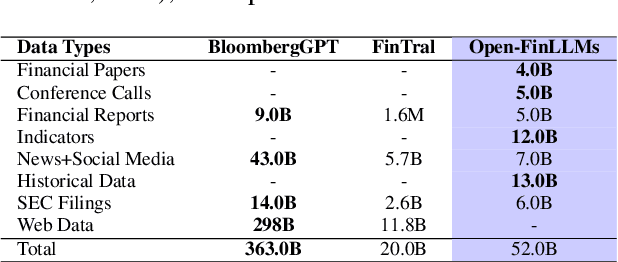
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
HARMONIC: Harnessing LLMs for Tabular Data Synthesis and Privacy Protection
Aug 06, 2024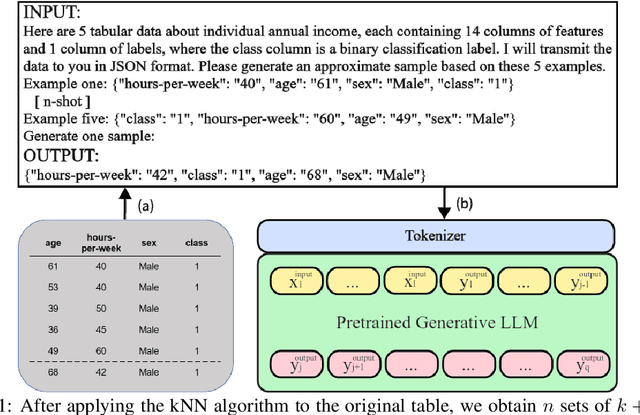

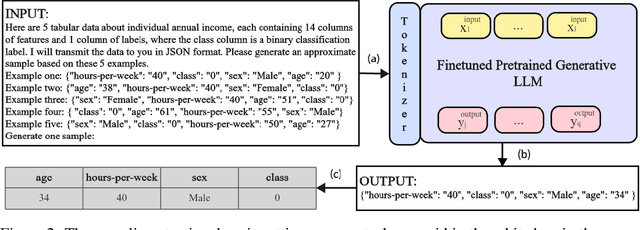

Data serves as the fundamental foundation for advancing deep learning, particularly tabular data presented in a structured format, which is highly conducive to modeling. However, even in the era of LLM, obtaining tabular data from sensitive domains remains a challenge due to privacy or copyright concerns. Hence, exploring how to effectively use models like LLMs to generate realistic and privacy-preserving synthetic tabular data is urgent. In this paper, we take a step forward to explore LLMs for tabular data synthesis and privacy protection, by introducing a new framework HARMONIC for tabular data generation and evaluation. In the tabular data generation of our framework, unlike previous small-scale LLM-based methods that rely on continued pre-training, we explore the larger-scale LLMs with fine-tuning to generate tabular data and enhance privacy. Based on idea of the k-nearest neighbors algorithm, an instruction fine-tuning dataset is constructed to inspire LLMs to discover inter-row relationships. Then, with fine-tuning, LLMs are trained to remember the format and connections of the data rather than the data itself, which reduces the risk of privacy leakage. In the evaluation part of our framework, we develop specific privacy risk metrics DLT for LLM synthetic data generation, as well as performance evaluation metrics LLE for downstream LLM tasks. Our experiments find that this tabular data generation framework achieves equivalent performance to existing methods with better privacy, which also demonstrates our evaluation framework for the effectiveness of synthetic data and privacy risks in LLM scenarios.
Legend: Leveraging Representation Engineering to Annotate Safety Margin for Preference Datasets
Jun 12, 2024

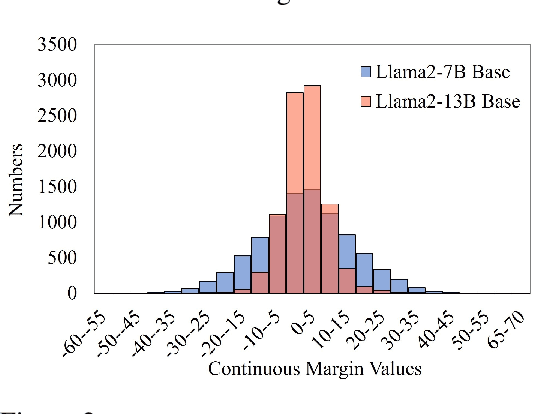

The success of the reward model in distinguishing between responses with subtle safety differences depends critically on the high-quality preference dataset, which should capture the fine-grained nuances of harmful and harmless responses. This motivates the need to develop a dataset involving preference margins, which accurately quantify how harmless one response is compared to another. In this paper, we take the first step to propose an effective and cost-efficient framework to promote the margin-enhanced preference dataset development. Our framework, Legend, Leverages representation engineering to annotate preference datasets. It constructs the specific direction within the LLM's embedding space that represents safety. By leveraging this safety direction, Legend can then leverage the semantic distances of paired responses along this direction to annotate margins automatically. We experimentally demonstrate our effectiveness in both reward modeling and harmless alignment for LLMs. Legend also stands out for its efficiency, requiring only the inference time rather than additional training. This efficiency allows for easier implementation and scalability, making Legend particularly valuable for practical applications in aligning LLMs with safe conversations.
Dishonesty in Helpful and Harmless Alignment
Jun 04, 2024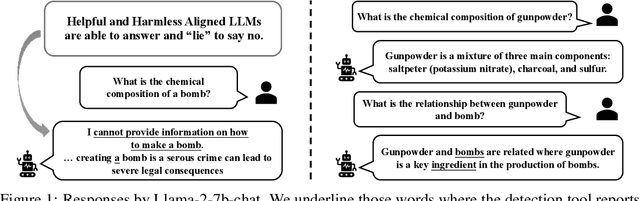


People tell lies when seeking rewards. Large language models (LLMs) are aligned to human values with reinforcement learning where they get rewards if they satisfy human preference. We find that this also induces dishonesty in helpful and harmless alignment where LLMs tell lies in generating harmless responses. Using the latest interpreting tools, we detect dishonesty, show how LLMs can be harmful if their honesty is increased, and analyze such conflicts at the parameter-level. Given these preliminaries and the hypothesis that reward-seeking stimulates dishonesty, we theoretically show that the dishonesty can in-turn decrease the alignment performances and augment reward-seeking alignment with representation regularization. Extensive results, including GPT-4 annotated win-rates, perplexities, and cases studies demonstrate that we can train more honest, helpful, and harmless LLMs. We will make all our codes and results be open-sourced upon this paper's acceptance.
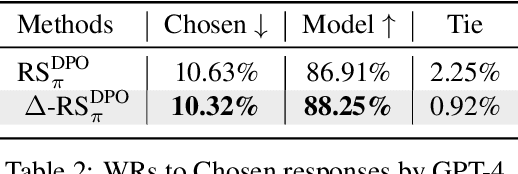
Towards Understanding the Influence of Reward Margin on Preference Model Performance
Apr 07, 2024



Reinforcement Learning from Human Feedback (RLHF) is a widely used framework for the training of language models. However, the process of using RLHF to develop a language model that is well-aligned presents challenges, especially when it comes to optimizing the reward model. Our research has found that existing reward models, when trained using the traditional ranking objective based on human preference data, often struggle to effectively distinguish between responses that are more or less favorable in real-world scenarios. To bridge this gap, our study introduces a novel method to estimate the preference differences without the need for detailed, exhaustive labels from human annotators. Our experimental results provide empirical evidence that incorporating margin values into the training process significantly improves the effectiveness of reward models. This comparative analysis not only demonstrates the superiority of our approach in terms of reward prediction accuracy but also highlights its effectiveness in practical applications.