 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHerculean: An Agentic Benchmark for Financial Intelligence
May 14, 2026As AI agents improve, the central question is no longer whether they can solve isolated well-defined financial tasks, but whether they can reliably carry out financial professional work. Existing financial benchmarks offer only a partial view of this ability, as they primarily evaluate static competencies such as question answering, retrieval, summarization, and classification. We introduce Herculean, the first skilled benchmark for agentic financial intelligence spanning four representative workflows, including Trading, Hedging, Market Insights, and Auditing. Each workflow is instantiated as a standardized MCP-based skill environment with its own tools, interaction dynamics, constraints, and success criteria, enabling consistent end-to-end assessment of heterogeneous agent systems. Across frontier agents, we find agents perform relatively well on Trading and Market Insights, but struggle substantially on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification are critical. Overall, our results point to a key gap in current agents in turning financial reasoning into dependable workflow execution in high-stakes financial workflows.
Concordia: Self-Improving Synthetic Tables for Federated LLMs
May 11, 2026Federated learning (FL) enables training large language models (LLMs) without sharing raw data, but adapting LLMs under strict data isolation and non-IID client distributions remains challenging in practice. Synthetic data offers a natural privacy-preserving surrogate for local training, yet existing federated pipelines typically treat synthetic generation as static or loosely coupled with downstream optimization, leading to rapidly diminishing utility under heterogeneous clients. We study federated adaptation of LLMs on tabular tasks where raw records and validation data cannot be shared, and local training must rely entirely on synthetic tables. We propose Concordia, a tri-level optimization framework that aligns synthetic data generation with federated validation utility despite these constraints. At the client level, models are adapted via parameter-efficient LoRA training on synthetic tables. Clients additionally learn lightweight utility scorers from private validation feedback to reweight synthetic samples during local training. At the outer level, each client refines its own synthetic table generator using group-relative policy optimization (GRPO), guided by an ensemble of heterogeneous scorers shared across clients, without aggregating generator parameters or exposing validation data. Experiments on privacy-sensitive tabular benchmarks from finance and healthcare demonstrate that Concordia consistently improves federated performance, cross-client stability, and robustness to distribution shift compared to static and decoupled synthetic-data baselines.
Evaluating LLMs in Finance Requires Explicit Bias Consideration
Feb 15, 2026Large Language Models (LLMs) are increasingly integrated into financial workflows, but evaluation practice has not kept up. Finance-specific biases can inflate performance, contaminate backtests, and make reported results useless for any deployment claim. We identify five recurring biases in financial LLM applications. They include look-ahead bias, survivorship bias, narrative bias, objective bias, and cost bias. These biases break financial tasks in distinct ways and they often compound to create an illusion of validity. We reviewed 164 papers from 2023 to 2025 and found that no single bias is discussed in more than 28 percent of studies. This position paper argues that bias in financial LLM systems requires explicit attention and that structural validity should be enforced before any result is used to support a deployment claim. We propose a Structural Validity Framework and an evaluation checklist with minimal requirements for bias diagnosis and future system design. The material is available at https://github.com/Eleanorkong/Awesome-Financial-LLM-Bias-Mitigation.
Cross-Sectional Asset Retrieval via Future-Aligned Soft Contrastive Learning
Feb 11, 2026Asset retrieval--finding similar assets in a financial universe--is central to quantitative investment decision-making. Existing approaches define similarity through historical price patterns or sector classifications, but such backward-looking criteria provide no guarantee about future behavior. We argue that effective asset retrieval should be future-aligned: the retrieved assets should be those most likely to exhibit correlated future returns. To this end, we propose Future-Aligned Soft Contrastive Learning (FASCL), a representation learning framework whose soft contrastive loss uses pairwise future return correlations as continuous supervision targets. We further introduce an evaluation protocol designed to directly assess whether retrieved assets share similar future trajectories. Experiments on 4,229 US equities demonstrate that FASCL consistently outperforms 13 baselines across all future-behavior metrics. The source code will be available soon.
All That Glisters Is Not Gold: A Benchmark for Reference-Free Counterfactual Financial Misinformation Detection
Jan 08, 2026We introduce RFC Bench, a benchmark for evaluating large language models on financial misinformation under realistic news. RFC Bench operates at the paragraph level and captures the contextual complexity of financial news where meaning emerges from dispersed cues. The benchmark defines two complementary tasks: reference free misinformation detection and comparison based diagnosis using paired original perturbed inputs. Experiments reveal a consistent pattern: performance is substantially stronger when comparative context is available, while reference free settings expose significant weaknesses, including unstable predictions and elevated invalid outputs. These results indicate that current models struggle to maintain coherent belief states without external grounding. By highlighting this gap, RFC Bench provides a structured testbed for studying reference free reasoning and advancing more reliable financial misinformation detection in real world settings.
Your AI, Not Your View: The Bias of LLMs in Investment Analysis
Jul 28, 2025In finance, Large Language Models (LLMs) face frequent knowledge conflicts due to discrepancies between pre-trained parametric knowledge and real-time market data. These conflicts become particularly problematic when LLMs are deployed in real-world investment services, where misalignment between a model's embedded preferences and those of the financial institution can lead to unreliable recommendations. Yet little research has examined what investment views LLMs actually hold. We propose an experimental framework to investigate such conflicts, offering the first quantitative analysis of confirmation bias in LLM-based investment analysis. Using hypothetical scenarios with balanced and imbalanced arguments, we extract models' latent preferences and measure their persistence. Focusing on sector, size, and momentum, our analysis reveals distinct, model-specific tendencies. In particular, we observe a consistent preference for large-cap stocks and contrarian strategies across most models. These preferences often harden into confirmation bias, with models clinging to initial judgments despite counter-evidence.
FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation
Apr 22, 2025In the fast-paced financial domain, accurate and up-to-date information is critical to addressing ever-evolving market conditions. Retrieving this information correctly is essential in financial Question-Answering (QA), since many language models struggle with factual accuracy in this domain. We present FinDER, an expert-generated dataset tailored for Retrieval-Augmented Generation (RAG) in finance. Unlike existing QA datasets that provide predefined contexts and rely on relatively clear and straightforward queries, FinDER focuses on annotating search-relevant evidence by domain experts, offering 5,703 query-evidence-answer triplets derived from real-world financial inquiries. These queries frequently include abbreviations, acronyms, and concise expressions, capturing the brevity and ambiguity common in the realistic search behavior of professionals. By challenging models to retrieve relevant information from large corpora rather than relying on readily determined contexts, FinDER offers a more realistic benchmark for evaluating RAG systems. We further present a comprehensive evaluation of multiple state-of-the-art retrieval models and Large Language Models, showcasing challenges derived from a realistic benchmark to drive future research on truthful and precise RAG in the financial domain.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
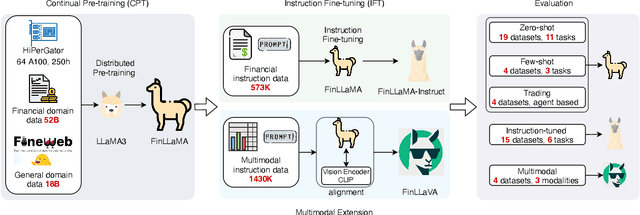
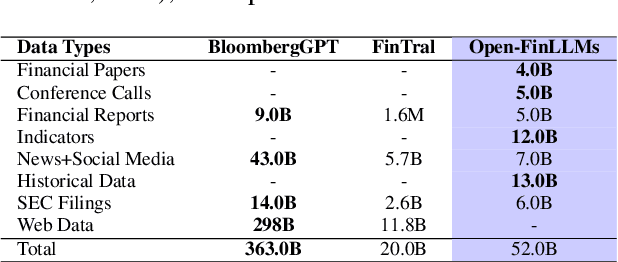
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
Mar 10, 2024



While the progression of Large Language Models (LLMs) has notably propelled financial analysis, their application has largely been confined to singular language realms, leaving untapped the potential of bilingual Chinese-English capacity. To bridge this chasm, we introduce ICE-PIXIU, seamlessly amalgamating the ICE-INTENT model and ICE-FLARE benchmark for bilingual financial analysis. ICE-PIXIU uniquely integrates a spectrum of Chinese tasks, alongside translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It provides unrestricted access to diverse model variants, a substantial compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, comprising 10 NLP tasks, 20 bilingual specific tasks, totaling 1,185k datasets. Our thorough evaluation emphasizes the advantages of incorporating these bilingual datasets, especially in translation tasks and utilizing original English data, enhancing both linguistic flexibility and analytical acuity in financial contexts. Notably, ICE-INTENT distinguishes itself by showcasing significant enhancements over conventional LLMs and existing financial LLMs in bilingual milieus, underscoring the profound impact of robust bilingual data on the accuracy and efficacy of financial NLP.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.