 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTexTS: Financial Text-Paired Time-Series Dataset via Semantic-Based and Multi-Level Pairing
Mar 03, 2026The financial domain involves a variety of important time-series problems. Recently, time-series analysis methods that jointly leverage textual and numerical information have gained increasing attention. Accordingly, numerous efforts have been made to construct text-paired time-series datasets in the financial domain. However, financial markets are characterized by complex interdependencies, in which a company's stock price is influenced not only by company-specific events but also by events in other companies and broader macroeconomic factors. Existing approaches that pair text with financial time-series data based on simple keyword matching often fail to capture such complex relationships. To address this limitation, we propose a semantic-based and multi-level pairing framework. Specifically, we extract company-specific context for the target company from SEC filings and apply an embedding-based matching mechanism to retrieve semantically relevant news articles based on this context. Furthermore, we classify news articles into four levels (macro-level, sector-level, related company-level, and target-company level) using large language models (LLMs), enabling multi-level pairing of news articles with the target company. Applying this framework to publicly-available news datasets, we construct \textbf{FinTexTS}, a new large-scale text-paired stock price dataset. Experimental results on \textbf{FinTexTS} demonstrate the effectiveness of our semantic-based and multi-level pairing strategy in stock price forecasting. In addition to publicly-available news underlying \textbf{FinTexTS}, we show that applying our method to proprietary yet carefully curated news sources leads to higher-quality paired data and improved stock price forecasting performance.
Evaluating LLMs in Finance Requires Explicit Bias Consideration
Feb 15, 2026Large Language Models (LLMs) are increasingly integrated into financial workflows, but evaluation practice has not kept up. Finance-specific biases can inflate performance, contaminate backtests, and make reported results useless for any deployment claim. We identify five recurring biases in financial LLM applications. They include look-ahead bias, survivorship bias, narrative bias, objective bias, and cost bias. These biases break financial tasks in distinct ways and they often compound to create an illusion of validity. We reviewed 164 papers from 2023 to 2025 and found that no single bias is discussed in more than 28 percent of studies. This position paper argues that bias in financial LLM systems requires explicit attention and that structural validity should be enforced before any result is used to support a deployment claim. We propose a Structural Validity Framework and an evaluation checklist with minimal requirements for bias diagnosis and future system design. The material is available at https://github.com/Eleanorkong/Awesome-Financial-LLM-Bias-Mitigation.
Cross-Sectional Asset Retrieval via Future-Aligned Soft Contrastive Learning
Feb 11, 2026Asset retrieval--finding similar assets in a financial universe--is central to quantitative investment decision-making. Existing approaches define similarity through historical price patterns or sector classifications, but such backward-looking criteria provide no guarantee about future behavior. We argue that effective asset retrieval should be future-aligned: the retrieved assets should be those most likely to exhibit correlated future returns. To this end, we propose Future-Aligned Soft Contrastive Learning (FASCL), a representation learning framework whose soft contrastive loss uses pairwise future return correlations as continuous supervision targets. We further introduce an evaluation protocol designed to directly assess whether retrieved assets share similar future trajectories. Experiments on 4,229 US equities demonstrate that FASCL consistently outperforms 13 baselines across all future-behavior metrics. The source code will be available soon.
Process-Aware Procurement Lead Time Prediction for Shipyard Delay Mitigation
Jan 27, 2026Accurately predicting procurement lead time (PLT) remains a challenge in engineered-to-order industries such as shipbuilding and plant construction, where delays in a single key component can disrupt project timelines. In shipyards, pipe spools are critical components; installed deep within hull blocks soon after steel erection, any delay in their procurement can halt all downstream tasks. Recognizing their importance, existing studies predict PLT using the static physical attributes of pipe spools. However, procurement is inherently a dynamic, multi-stakeholder business process involving a continuous sequence of internal and external events at the shipyard, factors often overlooked in traditional approaches. To address this issue, this paper proposes a novel framework that combines event logs, dataset records of the procurement events, with static attributes to predict PLT. The temporal attributes of each event are extracted to reflect the continuity and temporal context of the process. Subsequently, a deep sequential neural network combined with a multi-layered perceptron is employed to integrate these static and dynamic features, enabling the model to capture both structural and contextual information in procurement. Comparative experiments are conducted using real-world pipe spool procurement data from a globally renowned South Korean shipbuilding corporation. Three tasks are evaluated, which are production, post-processing, and procurement lead time prediction. The results show a 22.6% to 50.4% improvement in prediction performance in terms of mean absolute error over the best-performing existing approaches across the three tasks. These findings indicate the value of considering procurement process information for more accurate PLT prediction.
GuruAgents: Emulating Wise Investors with Prompt-Guided LLM Agents
Oct 02, 2025This study demonstrates that GuruAgents, prompt-guided AI agents, can systematically operationalize the strategies of legendary investment gurus. We develop five distinct GuruAgents, each designed to emulate an iconic investor, by encoding their distinct philosophies into LLM prompts that integrate financial tools and a deterministic reasoning pipeline. In a backtest on NASDAQ-100 constituents from Q4 2023 to Q2 2025, the GuruAgents exhibit unique behaviors driven by their prompted personas. The Buffett GuruAgent achieves the highest performance, delivering a 42.2\% CAGR that significantly outperforms benchmarks, while other agents show varied results. These findings confirm that prompt engineering can successfully translate the qualitative philosophies of investment gurus into reproducible, quantitative strategies, highlighting a novel direction for automated systematic investing. The source code and data are available at https://github.com/yejining99/GuruAgents.
* 7 Pages, 2 figures
Prediction Loss Guided Decision-Focused Learning
Sep 10, 2025Decision-making under uncertainty is often considered in two stages: predicting the unknown parameters, and then optimizing decisions based on predictions. While traditional prediction-focused learning (PFL) treats these two stages separately, decision-focused learning (DFL) trains the predictive model by directly optimizing the decision quality in an end-to-end manner. However, despite using exact or well-approximated gradients, vanilla DFL often suffers from unstable convergence due to its flat-and-sharp loss landscapes. In contrast, PFL yields more stable optimization, but overlooks the downstream decision quality. To address this, we propose a simple yet effective approach: perturbing the decision loss gradient using the prediction loss gradient to construct an update direction. Our method requires no additional training and can be integrated with any DFL solvers. Using the sigmoid-like decaying parameter, we let the prediction loss gradient guide the decision loss gradient to train a predictive model that optimizes decision quality. Also, we provide a theoretical convergence guarantee to Pareto stationary point under mild assumptions. Empirically, we demonstrate our method across three stochastic optimization problems, showing promising results compared to other baselines. We validate that our approach achieves lower regret with more stable training, even in situations where either PFL or DFL struggles.
THEME : Enhancing Thematic Investing with Semantic Stock Representations and Temporal Dynamics
Aug 23, 2025Thematic investing aims to construct portfolios aligned with structural trends, yet selecting relevant stocks remains challenging due to overlapping sector boundaries and evolving market dynamics. To address this challenge, we construct the Thematic Representation Set (TRS), an extended dataset that begins with real-world thematic ETFs and expands upon them by incorporating industry classifications and financial news to overcome their coverage limitations. The final dataset contains both the explicit mapping of themes to their constituent stocks and the rich textual profiles for each. Building on this dataset, we introduce \textsc{THEME}, a hierarchical contrastive learning framework. By representing the textual profiles of themes and stocks as embeddings, \textsc{THEME} first leverages their hierarchical relationship to achieve semantic alignment. Subsequently, it refines these semantic embeddings through a temporal refinement stage that incorporates individual stock returns. The final stock representations are designed for effective retrieval of thematically aligned assets with strong return potential. Empirical results show that \textsc{THEME} outperforms strong baselines across multiple retrieval metrics and significantly improves performance in portfolio construction. By jointly modeling thematic relationships from text and market dynamics from returns, \textsc{THEME} provides a scalable and adaptive solution for navigating complex investment themes.
Your AI, Not Your View: The Bias of LLMs in Investment Analysis
Jul 28, 2025In finance, Large Language Models (LLMs) face frequent knowledge conflicts due to discrepancies between pre-trained parametric knowledge and real-time market data. These conflicts become particularly problematic when LLMs are deployed in real-world investment services, where misalignment between a model's embedded preferences and those of the financial institution can lead to unreliable recommendations. Yet little research has examined what investment views LLMs actually hold. We propose an experimental framework to investigate such conflicts, offering the first quantitative analysis of confirmation bias in LLM-based investment analysis. Using hypothetical scenarios with balanced and imbalanced arguments, we extract models' latent preferences and measure their persistence. Focusing on sector, size, and momentum, our analysis reveals distinct, model-specific tendencies. In particular, we observe a consistent preference for large-cap stocks and contrarian strategies across most models. These preferences often harden into confirmation bias, with models clinging to initial judgments despite counter-evidence.
FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation
Apr 22, 2025In the fast-paced financial domain, accurate and up-to-date information is critical to addressing ever-evolving market conditions. Retrieving this information correctly is essential in financial Question-Answering (QA), since many language models struggle with factual accuracy in this domain. We present FinDER, an expert-generated dataset tailored for Retrieval-Augmented Generation (RAG) in finance. Unlike existing QA datasets that provide predefined contexts and rely on relatively clear and straightforward queries, FinDER focuses on annotating search-relevant evidence by domain experts, offering 5,703 query-evidence-answer triplets derived from real-world financial inquiries. These queries frequently include abbreviations, acronyms, and concise expressions, capturing the brevity and ambiguity common in the realistic search behavior of professionals. By challenging models to retrieve relevant information from large corpora rather than relying on readily determined contexts, FinDER offers a more realistic benchmark for evaluating RAG systems. We further present a comprehensive evaluation of multiple state-of-the-art retrieval models and Large Language Models, showcasing challenges derived from a realistic benchmark to drive future research on truthful and precise RAG in the financial domain.
Integrating LLM-Generated Views into Mean-Variance Optimization Using the Black-Litterman Model
Apr 19, 2025
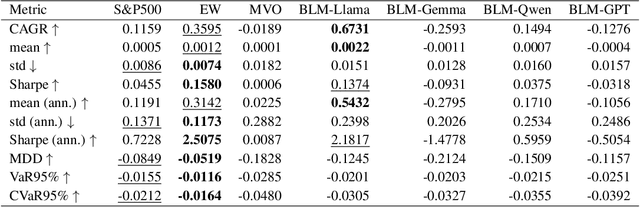
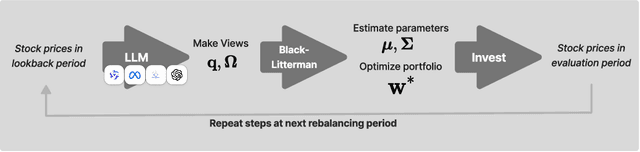
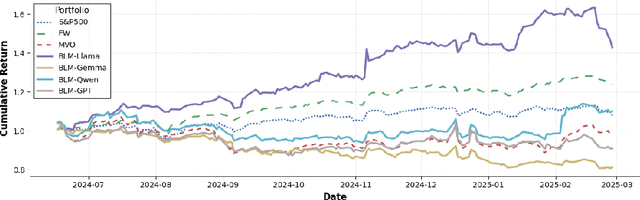
Portfolio optimization faces challenges due to the sensitivity in traditional mean-variance models. The Black-Litterman model mitigates this by integrating investor views, but defining these views remains difficult. This study explores the integration of large language models (LLMs) generated views into portfolio optimization using the Black-Litterman framework. Our method leverages LLMs to estimate expected stock returns from historical prices and company metadata, incorporating uncertainty through the variance in predictions. We conduct a backtest of the LLM-optimized portfolios from June 2024 to February 2025, rebalancing biweekly using the previous two weeks of price data. As baselines, we compare against the S&P 500, an equal-weighted portfolio, and a traditional mean-variance optimized portfolio constructed using the same set of stocks. Empirical results suggest that different LLMs exhibit varying levels of predictive optimism and confidence stability, which impact portfolio performance. The source code and data are available at https://github.com/youngandbin/LLM-MVO-BLM.