 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs in Finance Requires Explicit Bias Consideration
Feb 15, 2026Large Language Models (LLMs) are increasingly integrated into financial workflows, but evaluation practice has not kept up. Finance-specific biases can inflate performance, contaminate backtests, and make reported results useless for any deployment claim. We identify five recurring biases in financial LLM applications. They include look-ahead bias, survivorship bias, narrative bias, objective bias, and cost bias. These biases break financial tasks in distinct ways and they often compound to create an illusion of validity. We reviewed 164 papers from 2023 to 2025 and found that no single bias is discussed in more than 28 percent of studies. This position paper argues that bias in financial LLM systems requires explicit attention and that structural validity should be enforced before any result is used to support a deployment claim. We propose a Structural Validity Framework and an evaluation checklist with minimal requirements for bias diagnosis and future system design. The material is available at https://github.com/Eleanorkong/Awesome-Financial-LLM-Bias-Mitigation.
NavFormer: IGRF Forecasting in Moving Coordinate Frames
Jan 14, 2026Triad magnetometer components change with sensor attitude even when the IGRF total intensity target stays invariant. NavFormer forecasts this invariant target with rotation invariant scalar features and a Canonical SPD module that stabilizes the spectrum of window level second moments of the triads without sign discontinuities. The module builds a canonical frame from a Gram matrix per window and applies state dependent spectral scaling in the original coordinates. Experiments across five flights show lower error than strong baselines in standard training, few shot training, and zero shot transfer. The code is available at: https://anonymous.4open.science/r/NavFormer-Robust-IGRF-Forecasting-for-Autonomous-Navigators-0765
Fusing Narrative Semantics for Financial Volatility Forecasting
Oct 23, 2025We introduce M2VN: Multi-Modal Volatility Network, a novel deep learning-based framework for financial volatility forecasting that unifies time series features with unstructured news data. M2VN leverages the representational power of deep neural networks to address two key challenges in this domain: (i) aligning and fusing heterogeneous data modalities, numerical financial data and textual information, and (ii) mitigating look-ahead bias that can undermine the validity of financial models. To achieve this, M2VN combines open-source market features with news embeddings generated by Time Machine GPT, a recently introduced point-in-time LLM, ensuring temporal integrity. An auxiliary alignment loss is introduced to enhance the integration of structured and unstructured data within the deep learning architecture. Extensive experiments demonstrate that M2VN consistently outperforms existing baselines, underscoring its practical value for risk management and financial decision-making in dynamic markets.
Decision-informed Neural Networks with Large Language Model Integration for Portfolio Optimization
Feb 02, 2025This paper addresses the critical disconnect between prediction and decision quality in portfolio optimization by integrating Large Language Models (LLMs) with decision-focused learning. We demonstrate both theoretically and empirically that minimizing the prediction error alone leads to suboptimal portfolio decisions. We aim to exploit the representational power of LLMs for investment decisions. An attention mechanism processes asset relationships, temporal dependencies, and macro variables, which are then directly integrated into a portfolio optimization layer. This enables the model to capture complex market dynamics and align predictions with the decision objectives. Extensive experiments on S\&P100 and DOW30 datasets show that our model consistently outperforms state-of-the-art deep learning models. In addition, gradient-based analyses show that our model prioritizes the assets most crucial to decision making, thus mitigating the effects of prediction errors on portfolio performance. These findings underscore the value of integrating decision objectives into predictions for more robust and context-aware portfolio management.
Geodesic Flow Kernels for Semi-Supervised Learning on Mixed-Variable Tabular Dataset
Dec 17, 2024Tabular data poses unique challenges due to its heterogeneous nature, combining both continuous and categorical variables. Existing approaches often struggle to effectively capture the underlying structure and relationships within such data. We propose GFTab (Geodesic Flow Kernels for Semi- Supervised Learning on Mixed-Variable Tabular Dataset), a semi-supervised framework specifically designed for tabular datasets. GFTab incorporates three key innovations: 1) Variable-specific corruption methods tailored to the distinct properties of continuous and categorical variables, 2) A Geodesic flow kernel based similarity measure to capture geometric changes between corrupted inputs, and 3) Tree-based embedding to leverage hierarchical relationships from available labeled data. To rigorously evaluate GFTab, we curate a comprehensive set of 21 tabular datasets spanning various domains, sizes, and variable compositions. Our experimental results show that GFTab outperforms existing ML/DL models across many of these datasets, particularly in settings with limited labeled data.
Temporal Representation Learning for Stock Similarities and Its Applications in Investment Management
Jul 18, 2024In the era of rapid globalization and digitalization, accurate identification of similar stocks has become increasingly challenging due to the non-stationary nature of financial markets and the ambiguity in conventional regional and sector classifications. To address these challenges, we examine SimStock, a novel temporal self-supervised learning framework that combines techniques from self-supervised learning (SSL) and temporal domain generalization to learn robust and informative representations of financial time series data. The primary focus of our study is to understand the similarities between stocks from a broader perspective, considering the complex dynamics of the global financial landscape. We conduct extensive experiments on four real-world datasets with thousands of stocks and demonstrate the effectiveness of SimStock in finding similar stocks, outperforming existing methods. The practical utility of SimStock is showcased through its application to various investment strategies, such as pairs trading, index tracking, and portfolio optimization, where it leads to superior performance compared to conventional methods. Our findings empirically examine the potential of data-driven approach to enhance investment decision-making and risk management practices by leveraging the power of temporal self-supervised learning in the face of the ever-changing global financial landscape.
CAFO: Feature-Centric Explanation on Time Series Classification
Jun 03, 2024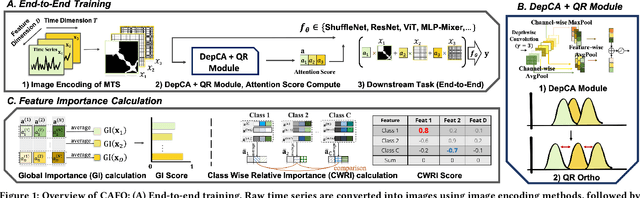
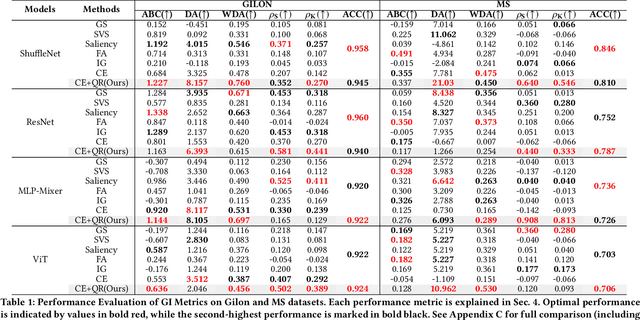

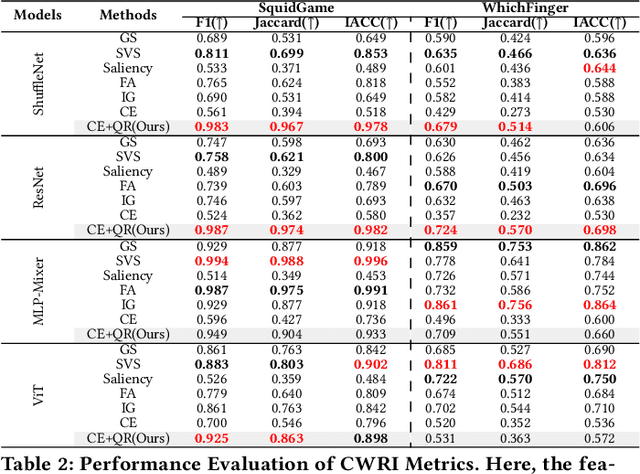
In multivariate time series (MTS) classification, finding the important features (e.g., sensors) for model performance is crucial yet challenging due to the complex, high-dimensional nature of MTS data, intricate temporal dynamics, and the necessity for domain-specific interpretations. Current explanation methods for MTS mostly focus on time-centric explanations, apt for pinpointing important time periods but less effective in identifying key features. This limitation underscores the pressing need for a feature-centric approach, a vital yet often overlooked perspective that complements time-centric analysis. To bridge this gap, our study introduces a novel feature-centric explanation and evaluation framework for MTS, named CAFO (Channel Attention and Feature Orthgonalization). CAFO employs a convolution-based approach with channel attention mechanisms, incorporating a depth-wise separable channel attention module (DepCA) and a QR decomposition-based loss for promoting feature-wise orthogonality. We demonstrate that this orthogonalization enhances the separability of attention distributions, thereby refining and stabilizing the ranking of feature importance. This improvement in feature-wise ranking enhances our understanding of feature explainability in MTS. Furthermore, we develop metrics to evaluate global and class-specific feature importance. Our framework's efficacy is validated through extensive empirical analyses on two major public benchmarks and real-world datasets, both synthetic and self-collected, specifically designed to highlight class-wise discriminative features. The results confirm CAFO's robustness and informative capacity in assessing feature importance in MTS classification tasks. This study not only advances the understanding of feature-centric explanations in MTS but also sets a foundation for future explorations in feature-centric explanations.