 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM Risk Signal Framework: Hierarchy-Based Red Lines for AI Behavioral Risk
Apr 13, 2026Current approaches to AI safety define red lines at the case level: specific prompts, specific outputs, specific harms. This paper argues that red lines can be set more fundamentally -- at the level of value, evidence, and source hierarchies that govern AI reasoning. Using the PRISM (Profile-based Reasoning Integrity Stack Measurement) framework, we define a taxonomy of 27 behavioral risk signals derived from structural anomalies in how AI systems prioritize values (L4), weight evidence types (L3), and trust information sources (L2). Each signal is evaluated through a dual-threshold principle combining absolute rank position and relative win-rate gap, producing a two-tier classification (Confirmed Risk vs. Watch Signal). The hierarchy-based approach offers three advantages over case-specific red lines: it is anticipatory rather than reactive (detecting dangerous reasoning structures before they produce harmful outputs), comprehensive rather than enumerative (a single value-hierarchy signal subsumes an unlimited number of case-specific violations), and measurable rather than subjective (grounded in empirical forced-choice data). We demonstrate the framework's detection capacity using approximately 397,000 forced-choice responses from 7 AI models across three Authority Stack layers, showing that the signal taxonomy successfully discriminates between models with structurally extreme profiles, models with context-dependent risk, and models with balanced hierarchies.
AI Integrity: A New Paradigm for Verifiable AI Governance
Apr 13, 2026AI systems increasingly shape high-stakes decisions in healthcare, law, defense, and education, yet existing governance paradigms -- AI Ethics, AI Safety, and AI Alignment -- share a common limitation: they evaluate outcomes rather than verifying the reasoning process itself. This paper introduces AI Integrity, a concept defined as a state in which the Authority Stack of an AI system -- its layered hierarchy of values, epistemological standards, source preferences, and data selection criteria -- is protected from corruption, contamination, manipulation, and bias, and maintained in a verifiable manner. We distinguish AI Integrity from the three existing paradigms, define the Authority Stack as a 4-layer cascade model (Normative, Epistemic, Source, and Data Authority) grounded in established academic frameworks -- Schwartz Basic Human Values for normative authority, Walton argumentation schemes with GRADE/CEBM hierarchies for epistemic authority, and Source Credibility Theory for source authority -- characterize the distinction between legitimate cascading and Authority Pollution, and identify Integrity Hallucination as the central measurable threat to value consistency. We further specify the PRISM (Profile-based Reasoning Integrity Stack Measurement) framework as the operational methodology, defining six core metrics and a phased research roadmap. Unlike normative frameworks that prescribe which values are correct, AI Integrity is a procedural concept: it requires that the path from evidence to conclusion be transparent and auditable, regardless of which values a system holds.
Measuring the Authority Stack of AI Systems: Empirical Analysis of 366,120 Forced-Choice Responses Across 8 AI Models
Apr 13, 2026What values, evidence preferences, and source trust hierarchies do AI systems actually exhibit when facing structured dilemmas? We present the first large-scale empirical mapping of AI decision-making across all three layers of the Authority Stack framework (S. Lee, 2026a): value priorities (L4), evidence-type preferences (L3), and source trust hierarchies (L2). Using the PRISM benchmark -- a forced-choice instrument of 14,175 unique scenarios per layer, spanning 7 professional domains, 3 severity levels, 3 decision timeframes, and 5 scenario variants -- we evaluated 8 major AI models at temperature 0, yielding 366,120 total responses. Key findings include: (1) a symmetric 4:4 split between Universalism-first and Security-first models at L4; (2) dramatic defense-domain value restructuring where Security surges to near-ceiling win-rates (95.1%-99.8%) in 6 of 8 models; (3) divergent evidence hierarchies at L3, with some models favoring empirical-scientific evidence while others prefer pattern-based or experiential evidence; (4) broad convergence on institutional source trust at L2; and (5) Paired Consistency Scores (PCS) ranging from 57.4% to 69.2%, revealing substantial framing sensitivity across scenario variants. Test-Retest Reliability (TRR) ranges from 91.7% to 98.6%, indicating that value instability stems primarily from variant sensitivity rather than stochastic noise. These findings demonstrate that AI models possess measurable -- if sometimes unstable -- Authority Stacks with consequential implications for deployment across professional domains.
TransPL: VQ-Code Transition Matrices for Pseudo-Labeling of Time Series Unsupervised Domain Adaptation
May 15, 2025



Unsupervised domain adaptation (UDA) for time series data remains a critical challenge in deep learning, with traditional pseudo-labeling strategies failing to capture temporal patterns and channel-wise shifts between domains, producing sub-optimal pseudo-labels. As such, we introduce TransPL, a novel approach that addresses these limitations by modeling the joint distribution $P(\mathbf{X}, y)$ of the source domain through code transition matrices, where the codes are derived from vector quantization (VQ) of time series patches. Our method constructs class- and channel-wise code transition matrices from the source domain and employs Bayes' rule for target domain adaptation, generating pseudo-labels based on channel-wise weighted class-conditional likelihoods. TransPL offers three key advantages: explicit modeling of temporal transitions and channel-wise shifts between different domains, versatility towards different UDA scenarios (e.g., weakly-supervised UDA), and explainable pseudo-label generation. We validate TransPL's effectiveness through extensive analysis on four time series UDA benchmarks and confirm that it consistently outperforms state-of-the-art pseudo-labeling methods by a strong margin (6.1% accuracy improvement, 4.9% F1 improvement), while providing interpretable insights into the domain adaptation process through its learned code transition matrices.
Position: The AI Conference Peer Review Crisis Demands Author Feedback and Reviewer Rewards
May 08, 2025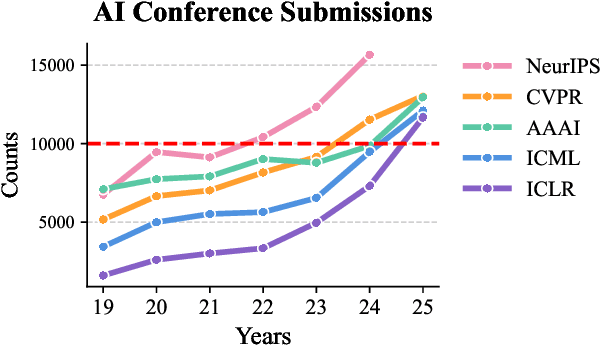
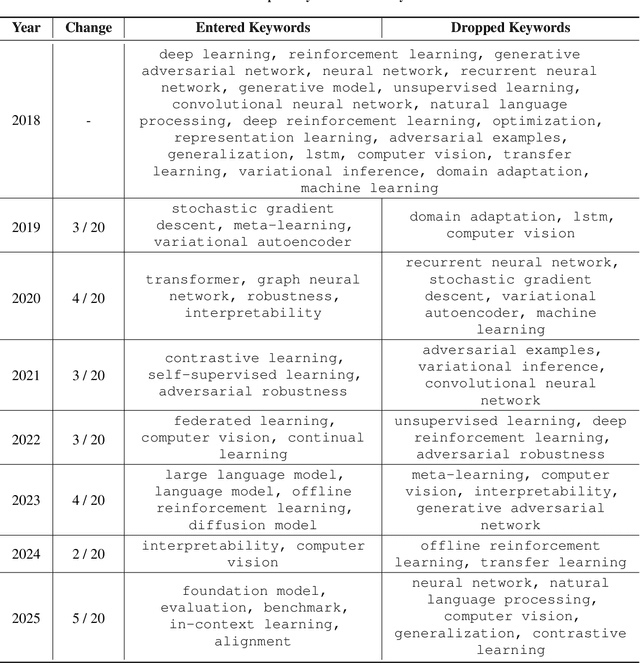
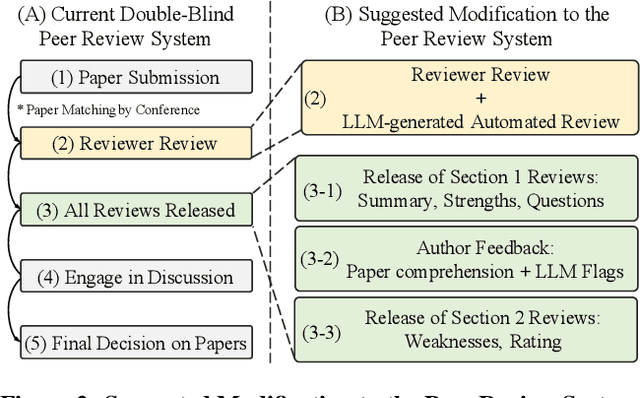
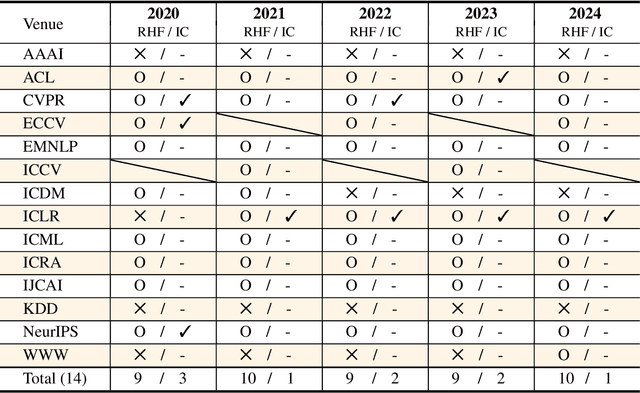
The peer review process in major artificial intelligence (AI) conferences faces unprecedented challenges with the surge of paper submissions (exceeding 10,000 submissions per venue), accompanied by growing concerns over review quality and reviewer responsibility. This position paper argues for the need to transform the traditional one-way review system into a bi-directional feedback loop where authors evaluate review quality and reviewers earn formal accreditation, creating an accountability framework that promotes a sustainable, high-quality peer review system. The current review system can be viewed as an interaction between three parties: the authors, reviewers, and system (i.e., conference), where we posit that all three parties share responsibility for the current problems. However, issues with authors can only be addressed through policy enforcement and detection tools, and ethical concerns can only be corrected through self-reflection. As such, this paper focuses on reforming reviewer accountability with systematic rewards through two key mechanisms: (1) a two-stage bi-directional review system that allows authors to evaluate reviews while minimizing retaliatory behavior, (2)a systematic reviewer reward system that incentivizes quality reviewing. We ask for the community's strong interest in these problems and the reforms that are needed to enhance the peer review process.
On-device Sora: Enabling Training-Free Diffusion-based Text-to-Video Generation for Mobile Devices
Apr 01, 2025We present On-device Sora, the first model training-free solution for diffusion-based on-device text-to-video generation that operates efficiently on smartphone-grade devices. To address the challenges of diffusion-based text-to-video generation on computation- and memory-limited mobile devices, the proposed On-device Sora applies three novel techniques to pre-trained video generative models. First, Linear Proportional Leap (LPL) reduces the excessive denoising steps required in video diffusion through an efficient leap-based approach. Second, Temporal Dimension Token Merging (TDTM) minimizes intensive token-processing computation in attention layers by merging consecutive tokens along the temporal dimension. Third, Concurrent Inference with Dynamic Loading (CI-DL) dynamically partitions large models into smaller blocks and loads them into memory for concurrent model inference, effectively addressing the challenges of limited device memory. We implement On-device Sora on the iPhone 15 Pro, and the experimental evaluations show that it is capable of generating high-quality videos on the device, comparable to those produced by high-end GPUs. These results show that On-device Sora enables efficient and high-quality video generation on resource-constrained mobile devices. We envision the proposed On-device Sora as a significant first step toward democratizing state-of-the-art generative technologies, enabling video generation on commodity mobile and embedded devices without resource-intensive re-training for model optimization (compression). The code implementation is available at a GitHub repository(https://github.com/eai-lab/On-device-Sora).
On-device Sora: Enabling Diffusion-Based Text-to-Video Generation for Mobile Devices
Feb 05, 2025



We present On-device Sora, a first pioneering solution for diffusion-based on-device text-to-video generation that operates efficiently on smartphone-grade devices. Building on Open-Sora, On-device Sora applies three novel techniques to address the challenges of diffusion-based text-to-video generation on computation- and memory-limited mobile devices. First, Linear Proportional Leap (LPL) reduces the excessive denoising steps required in video diffusion through an efficient leap-based approach. Second, Temporal Dimension Token Merging (TDTM) minimizes intensive token-processing computation in attention layers by merging consecutive tokens along the temporal dimension. Third, Concurrent Inference with Dynamic Loading (CI-DL) dynamically partitions large models into smaller blocks and loads them into memory for concurrent model inference, effectively addressing the challenges of limited device memory. We implement On-device Sora on the iPhone 15 Pro, and the experimental evaluations demonstrate that it is capable of generating high-quality videos on the device, comparable to those produced by Open-Sora running on high-end GPUs. These results show that On-device Sora enables efficient and high-quality video generation on resource-constrained mobile devices, expanding accessibility, ensuring user privacy, reducing dependence on cloud infrastructure, and lowering associated costs. We envision the proposed On-device Sora as a significant first step toward democratizing state-of-the-art generative technologies, enabling video generation capabilities on commodity mobile and embedded devices. The code implementation is publicly available at an GitHub repository: https://github.com/eai-lab/On-device-Sora.
SMMF: Square-Matricized Momentum Factorization for Memory-Efficient Optimization
Dec 12, 2024We propose SMMF (Square-Matricized Momentum Factorization), a memory-efficient optimizer that reduces the memory requirement of the widely used adaptive learning rate optimizers, such as Adam, by up to 96%. SMMF enables flexible and efficient factorization of an arbitrary rank (shape) of the first and second momentum tensors during optimization, based on the proposed square-matricization and one-time single matrix factorization. From this, it becomes effectively applicable to any rank (shape) of momentum tensors, i.e., bias, matrix, and any rank-d tensors, prevalent in various deep model architectures, such as CNNs (high rank) and Transformers (low rank), in contrast to existing memory-efficient optimizers that applies only to a particular (rank-2) momentum tensor, e.g., linear layers. We conduct a regret bound analysis of SMMF, which shows that it converges similarly to non-memory-efficient adaptive learning rate optimizers, such as AdamNC, providing a theoretical basis for its competitive optimization capability. In our experiment, SMMF takes up to 96% less memory compared to state-of-the-art memory efficient optimizers, e.g., Adafactor, CAME, and SM3, while achieving comparable model performance on various CNN and Transformer tasks.
Designing Extremely Memory-Efficient CNNs for On-device Vision Tasks
Aug 07, 2024
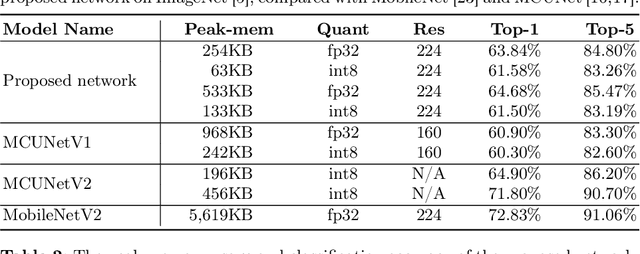


In this paper, we introduce a memory-efficient CNN (convolutional neural network), which enables resource-constrained low-end embedded and IoT devices to perform on-device vision tasks, such as image classification and object detection, using extremely low memory, i.e., only 63 KB on ImageNet classification. Based on the bottleneck block of MobileNet, we propose three design principles that significantly curtail the peak memory usage of a CNN so that it can fit the limited KB memory of the low-end device. First, 'input segmentation' divides an input image into a set of patches, including the central patch overlapped with the others, reducing the size (and memory requirement) of a large input image. Second, 'patch tunneling' builds independent tunnel-like paths consisting of multiple bottleneck blocks per patch, penetrating through the entire model from an input patch to the last layer of the network, maintaining lightweight memory usage throughout the whole network. Lastly, 'bottleneck reordering' rearranges the execution order of convolution operations inside the bottleneck block such that the memory usage remains constant regardless of the size of the convolution output channels. The experiment result shows that the proposed network classifies ImageNet with extremely low memory (i.e., 63 KB) while achieving competitive top-1 accuracy (i.e., 61.58\%). To the best of our knowledge, the memory usage of the proposed network is far smaller than state-of-the-art memory-efficient networks, i.e., up to 89x and 3.1x smaller than MobileNet (i.e., 5.6 MB) and MCUNet (i.e., 196 KB), respectively.
CAFO: Feature-Centric Explanation on Time Series Classification
Jun 03, 2024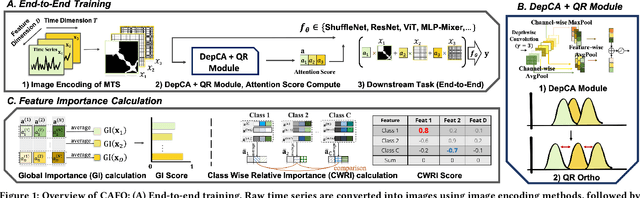
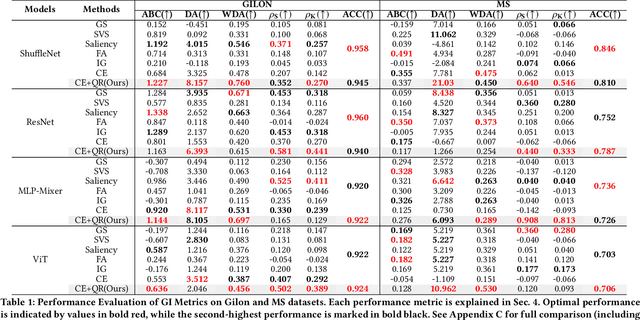

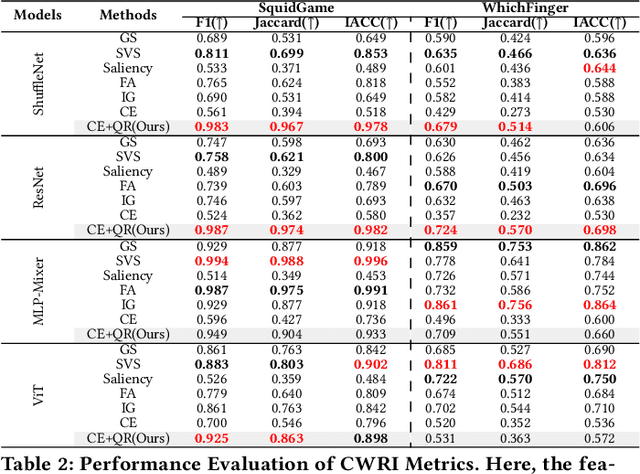
In multivariate time series (MTS) classification, finding the important features (e.g., sensors) for model performance is crucial yet challenging due to the complex, high-dimensional nature of MTS data, intricate temporal dynamics, and the necessity for domain-specific interpretations. Current explanation methods for MTS mostly focus on time-centric explanations, apt for pinpointing important time periods but less effective in identifying key features. This limitation underscores the pressing need for a feature-centric approach, a vital yet often overlooked perspective that complements time-centric analysis. To bridge this gap, our study introduces a novel feature-centric explanation and evaluation framework for MTS, named CAFO (Channel Attention and Feature Orthgonalization). CAFO employs a convolution-based approach with channel attention mechanisms, incorporating a depth-wise separable channel attention module (DepCA) and a QR decomposition-based loss for promoting feature-wise orthogonality. We demonstrate that this orthogonalization enhances the separability of attention distributions, thereby refining and stabilizing the ranking of feature importance. This improvement in feature-wise ranking enhances our understanding of feature explainability in MTS. Furthermore, we develop metrics to evaluate global and class-specific feature importance. Our framework's efficacy is validated through extensive empirical analyses on two major public benchmarks and real-world datasets, both synthetic and self-collected, specifically designed to highlight class-wise discriminative features. The results confirm CAFO's robustness and informative capacity in assessing feature importance in MTS classification tasks. This study not only advances the understanding of feature-centric explanations in MTS but also sets a foundation for future explorations in feature-centric explanations.