 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Needle(s) in the Embodied Haystack: Environment, Architecture, and Training Considerations for Long Context Reasoning
May 22, 2025We introduce $\infty$-THOR, a new framework for long-horizon embodied tasks that advances long-context understanding in embodied AI. $\infty$-THOR provides: (1) a generation framework for synthesizing scalable, reproducible, and unlimited long-horizon trajectories; (2) a novel embodied QA task, Needle(s) in the Embodied Haystack, where multiple scattered clues across extended trajectories test agents' long-context reasoning ability; and (3) a long-horizon dataset and benchmark suite featuring complex tasks that span hundreds of environment steps, each paired with ground-truth action sequences. To enable this capability, we explore architectural adaptations, including interleaved Goal-State-Action modeling, context extension techniques, and Context Parallelism, to equip LLM-based agents for extreme long-context reasoning and interaction. Experimental results and analyses highlight the challenges posed by our benchmark and provide insights into training strategies and model behaviors under long-horizon conditions. Our work provides a foundation for the next generation of embodied AI systems capable of robust, long-term reasoning and planning.
On-device Sora: Enabling Training-Free Diffusion-based Text-to-Video Generation for Mobile Devices
Apr 01, 2025We present On-device Sora, the first model training-free solution for diffusion-based on-device text-to-video generation that operates efficiently on smartphone-grade devices. To address the challenges of diffusion-based text-to-video generation on computation- and memory-limited mobile devices, the proposed On-device Sora applies three novel techniques to pre-trained video generative models. First, Linear Proportional Leap (LPL) reduces the excessive denoising steps required in video diffusion through an efficient leap-based approach. Second, Temporal Dimension Token Merging (TDTM) minimizes intensive token-processing computation in attention layers by merging consecutive tokens along the temporal dimension. Third, Concurrent Inference with Dynamic Loading (CI-DL) dynamically partitions large models into smaller blocks and loads them into memory for concurrent model inference, effectively addressing the challenges of limited device memory. We implement On-device Sora on the iPhone 15 Pro, and the experimental evaluations show that it is capable of generating high-quality videos on the device, comparable to those produced by high-end GPUs. These results show that On-device Sora enables efficient and high-quality video generation on resource-constrained mobile devices. We envision the proposed On-device Sora as a significant first step toward democratizing state-of-the-art generative technologies, enabling video generation on commodity mobile and embedded devices without resource-intensive re-training for model optimization (compression). The code implementation is available at a GitHub repository(https://github.com/eai-lab/On-device-Sora).
On-device Sora: Enabling Diffusion-Based Text-to-Video Generation for Mobile Devices
Feb 05, 2025



We present On-device Sora, a first pioneering solution for diffusion-based on-device text-to-video generation that operates efficiently on smartphone-grade devices. Building on Open-Sora, On-device Sora applies three novel techniques to address the challenges of diffusion-based text-to-video generation on computation- and memory-limited mobile devices. First, Linear Proportional Leap (LPL) reduces the excessive denoising steps required in video diffusion through an efficient leap-based approach. Second, Temporal Dimension Token Merging (TDTM) minimizes intensive token-processing computation in attention layers by merging consecutive tokens along the temporal dimension. Third, Concurrent Inference with Dynamic Loading (CI-DL) dynamically partitions large models into smaller blocks and loads them into memory for concurrent model inference, effectively addressing the challenges of limited device memory. We implement On-device Sora on the iPhone 15 Pro, and the experimental evaluations demonstrate that it is capable of generating high-quality videos on the device, comparable to those produced by Open-Sora running on high-end GPUs. These results show that On-device Sora enables efficient and high-quality video generation on resource-constrained mobile devices, expanding accessibility, ensuring user privacy, reducing dependence on cloud infrastructure, and lowering associated costs. We envision the proposed On-device Sora as a significant first step toward democratizing state-of-the-art generative technologies, enabling video generation capabilities on commodity mobile and embedded devices. The code implementation is publicly available at an GitHub repository: https://github.com/eai-lab/On-device-Sora.
An Autonomous System for Head-to-Head Race: Design, Implementation and Analysis; Team KAIST at the Indy Autonomous Challenge
Mar 16, 2023While the majority of autonomous driving research has concentrated on everyday driving scenarios, further safety and performance improvements of autonomous vehicles require a focus on extreme driving conditions. In this context, autonomous racing is a new area of research that has been attracting considerable interest recently. Due to the fact that a vehicle is driven by its perception, planning, and control limits during racing, numerous research and development issues arise. This paper provides a comprehensive overview of the autonomous racing system built by team KAIST for the Indy Autonomous Challenge (IAC). Our autonomy stack consists primarily of a multi-modal perception module, a high-speed overtaking planner, a resilient control stack, and a system status manager. We present the details of all components of our autonomy solution, including algorithms, implementation, and unit test results. In addition, this paper outlines the design principles and the results of a systematical analysis. Even though our design principles are derived from the unique application domain of autonomous racing, they can also be applied to a variety of safety-critical, high-cost-of-failure robotics applications. The proposed system was integrated into a full-scale autonomous race car (Dallara AV-21) and field-tested extensively. As a result, team KAIST was one of three teams who qualified and participated in the official IAC race events without any accidents. Our proposed autonomous system successfully completed all missions, including overtaking at speeds of around $220 km/h$ in the IAC@CES2022, the world's first autonomous 1:1 head-to-head race.
Zero-shot Triplet Extraction by Template Infilling
Dec 21, 2022

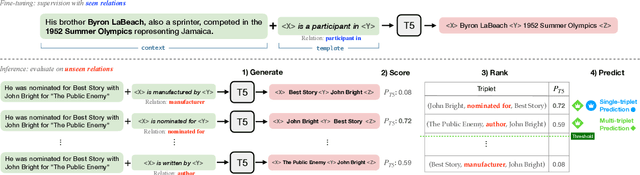
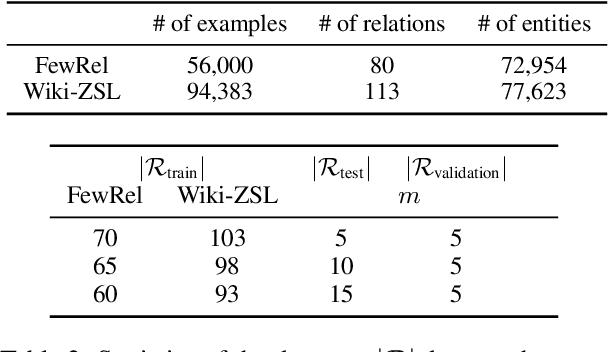
Triplet extraction aims to extract entities and their corresponding relations in unstructured text. Most existing methods train an extraction model on high-quality training data, and hence are incapable of extracting relations that were not observed during training. Generalizing the model to unseen relations typically requires fine-tuning on synthetic training data which is often noisy and unreliable. In this paper, we argue that reducing triplet extraction to a template filling task over a pre-trained language model can equip the model with zero-shot learning capabilities and enable it to leverage the implicit knowledge in the language model. Embodying these ideas, we propose a novel framework, ZETT (ZEro-shot Triplet extraction by Template infilling), that is based on end-to-end generative transformers. Our experiments show that without any data augmentation or pipeline systems, ZETT can outperform previous state-of-the-art models with 25% less parameters. We further show that ZETT is more robust in detecting entities and can be incorporated with automatically generated templates for relations.