 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training and Test-Time Scaling of Generative Agent Behavior Models for Interactive Autonomous Driving
Dec 15, 2025Learning interactive motion behaviors among multiple agents is a core challenge in autonomous driving. While imitation learning models generate realistic trajectories, they often inherit biases from datasets dominated by safe demonstrations, limiting robustness in safety-critical cases. Moreover, most studies rely on open-loop evaluation, overlooking compounding errors in closed-loop execution. We address these limitations with two complementary strategies. First, we propose Group Relative Behavior Optimization (GRBO), a reinforcement learning post-training method that fine-tunes pretrained behavior models via group relative advantage maximization with human regularization. Using only 10% of the training dataset, GRBO improves safety performance by over 40% while preserving behavioral realism. Second, we introduce Warm-K, a warm-started Top-K sampling strategy that balances consistency and diversity in motion selection. Our Warm-K method-based test-time scaling enhances behavioral consistency and reactivity at test time without retraining, mitigating covariate shift and reducing performance discrepancies. Demo videos are available in the supplementary material.
VLA-R: Vision-Language Action Retrieval toward Open-World End-to-End Autonomous Driving
Nov 16, 2025Exploring open-world situations in an end-to-end manner is a promising yet challenging task due to the need for strong generalization capabilities. In particular, end-to-end autonomous driving in unstructured outdoor environments often encounters conditions that were unfamiliar during training. In this work, we present Vision-Language Action Retrieval (VLA-R), an open-world end-to-end autonomous driving (OW-E2EAD) framework that integrates open-world perception with a novel vision-action retrieval paradigm. We leverage a frozen vision-language model for open-world detection and segmentation to obtain multi-scale, prompt-guided, and interpretable perception features without domain-specific tuning. A Q-Former bottleneck aggregates fine-grained visual representations with language-aligned visual features, bridging perception and action domains. To learn transferable driving behaviors, we introduce a vision-action contrastive learning scheme that aligns vision-language and action embeddings for effective open-world reasoning and action retrieval. Our experiments on a real-world robotic platform demonstrate strong generalization and exploratory performance in unstructured, unseen environments, even with limited data. Demo videos are provided in the supplementary material.
Learning from Demonstration with Hierarchical Policy Abstractions Toward High-Performance and Courteous Autonomous Racing
Nov 07, 2024



Fully autonomous racing demands not only high-speed driving but also fair and courteous maneuvers. In this paper, we propose an autonomous racing framework that learns complex racing behaviors from expert demonstrations using hierarchical policy abstractions. At the trajectory level, our policy model predicts a dense distribution map indicating the likelihood of trajectories learned from offline demonstrations. The maximum likelihood trajectory is then passed to the control-level policy, which generates control inputs in a residual fashion, considering vehicle dynamics at the limits of performance. We evaluate our framework in a high-fidelity racing simulator and compare it against competing baselines in challenging multi-agent adversarial scenarios. Quantitative and qualitative results show that our trajectory planning policy significantly outperforms the baselines, and the residual control policy improves lap time and tracking accuracy. Moreover, challenging closed-loop experiments with ten opponents show that our framework can overtake other vehicles by understanding nuanced interactions, effectively balancing performance and courtesy like professional drivers.
Words to Wheels: Vision-Based Autonomous Driving Understanding Human Language Instructions Using Foundation Models
Oct 14, 2024



This paper introduces an innovative application of foundation models, enabling Unmanned Ground Vehicles (UGVs) equipped with an RGB-D camera to navigate to designated destinations based on human language instructions. Unlike learning-based methods, this approach does not require prior training but instead leverages existing foundation models, thus facilitating generalization to novel environments. Upon receiving human language instructions, these are transformed into a 'cognitive route description' using a large language model (LLM)-a detailed navigation route expressed in human language. The vehicle then decomposes this description into landmarks and navigation maneuvers. The vehicle also determines elevation costs and identifies navigability levels of different regions through a terrain segmentation model, GANav, trained on open datasets. Semantic elevation costs, which take both elevation and navigability levels into account, are estimated and provided to the Model Predictive Path Integral (MPPI) planner, responsible for local path planning. Concurrently, the vehicle searches for target landmarks using foundation models, including YOLO-World and EfficientViT-SAM. Ultimately, the vehicle executes the navigation commands to reach the designated destination, the final landmark. Our experiments demonstrate that this application successfully guides UGVs to their destinations following human language instructions in novel environments, such as unfamiliar terrain or urban settings.
Skill Q-Network: Learning Adaptive Skill Ensemble for Mapless Navigation in Unknown Environments
Mar 25, 2024This paper focuses on the acquisition of mapless navigation skills within unknown environments. We introduce the Skill Q-Network (SQN), a novel reinforcement learning method featuring an adaptive skill ensemble mechanism. Unlike existing methods, our model concurrently learns a high-level skill decision process alongside multiple low-level navigation skills, all without the need for prior knowledge. Leveraging a tailored reward function for mapless navigation, the SQN is capable of learning adaptive maneuvers that incorporate both exploration and goal-directed skills, enabling effective navigation in new environments. Our experiments demonstrate that our SQN can effectively navigate complex environments, exhibiting a 40% higher performance compared to baseline models. Without explicit guidance, SQN discovers how to combine low-level skill policies, showcasing both goal-directed navigations to reach destinations and exploration maneuvers to escape from local minimum regions in challenging scenarios. Remarkably, our adaptive skill ensemble method enables zero-shot transfer to out-of-distribution domains, characterized by unseen observations from non-convex obstacles or uneven, subterranean-like environments.
Topological Exploration using Segmented Map with Keyframe Contribution in Subterranean Environments
Sep 15, 2023



Existing exploration algorithms mainly generate frontiers using random sampling or motion primitive methods within a specific sensor range or search space. However, frontiers generated within constrained spaces lead to back-and-forth maneuvers in large-scale environments, thereby diminishing exploration efficiency. To address this issue, we propose a method that utilizes a 3D dense map to generate Segmented Exploration Regions (SERs) and generate frontiers from a global-scale perspective. In particular, this paper presents a novel topological map generation approach that fully utilizes Line-of-Sight (LOS) features of LiDAR sensor points to enhance exploration efficiency inside large-scale subterranean environments. Our topological map contains the contributions of keyframes that generate each SER, enabling rapid exploration through a switch between local path planning and global path planning to each frontier. The proposed method achieved higher explored volume generation than the state-of-the-art algorithm in a large-scale simulation environment and demonstrated a 62% improvement in explored volume increment performance. For validation, we conducted field tests using UAVs in real subterranean environments, demonstrating the efficiency and speed of our method.
TempFuser: Learning Tactical and Agile Flight Maneuvers in Aerial Dogfights using a Long Short-Term Temporal Fusion Transformer
Aug 07, 2023Aerial dogfights necessitate understanding the tactically changing maneuvers from a long-term perspective, along with the rapidly changing aerodynamics from a short-term view. In this paper, we propose a novel long short-term temporal fusion transformer (TempFuser) for a policy network in aerial dogfights. Our method uses two LSTM-based input embeddings to encode long-term, sparse state trajectories, as well as short-term, dense state trajectories. By integrating the two embeddings through a transformer encoder, the method subsequently derives end-to-end flight commands for agile and tactical maneuvers. We formulate a deep reinforcement learning framework to train our TempFuser-based policy model. We then extensively validate our model, demonstrating that it outperforms other baseline models against a diverse range of opponent aircraft in a high-fidelity environment. Our model successfully learns basic fighter maneuvers, human pilot-like tactical maneuvers, and robust supersonic pursuit in low altitudes without explicitly coded prior knowledge. Videos are available at \url{https://sites.google.com/view/tempfuser}
A Versatile Door Opening System with Mobile Manipulator through Adaptive Position-Force Control and Reinforcement Learning
Jul 10, 2023


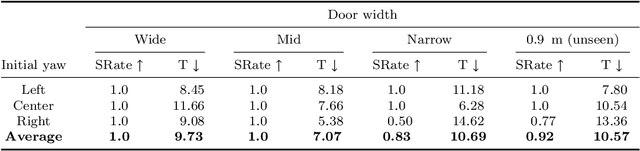
The ability of robots to navigate through doors is crucial for their effective operation in indoor environments. Consequently, extensive research has been conducted to develop robots capable of opening specific doors. However, the diverse combinations of door handles and opening directions necessitate a more versatile door opening system for robots to successfully operate in real-world environments. In this paper, we propose a mobile manipulator system that can autonomously open various doors without prior knowledge. By using convolutional neural networks, point cloud extraction techniques, and external force measurements during exploratory motion, we obtained information regarding handle types, poses, and door characteristics. Through two different approaches, adaptive position-force control and deep reinforcement learning, we successfully opened doors without precise trajectory or excessive external force. The adaptive position-force control method involves moving the end-effector in the direction of the door opening while responding compliantly to external forces, ensuring safety and manipulator workspace. Meanwhile, the deep reinforcement learning policy minimizes applied forces and eliminates unnecessary movements, enabling stable operation across doors with different poses and widths. The RL-based approach outperforms the adaptive position-force control method in terms of compensating for external forces, ensuring smooth motion, and achieving efficient speed. It reduces the maximum force required by 3.27 times and improves motion smoothness by 1.82 times. However, the non-learning-based adaptive position-force control method demonstrates more versatility in opening a wider range of doors, encompassing revolute doors with four distinct opening directions and varying widths.
An Autonomous System for Head-to-Head Race: Design, Implementation and Analysis; Team KAIST at the Indy Autonomous Challenge
Mar 16, 2023While the majority of autonomous driving research has concentrated on everyday driving scenarios, further safety and performance improvements of autonomous vehicles require a focus on extreme driving conditions. In this context, autonomous racing is a new area of research that has been attracting considerable interest recently. Due to the fact that a vehicle is driven by its perception, planning, and control limits during racing, numerous research and development issues arise. This paper provides a comprehensive overview of the autonomous racing system built by team KAIST for the Indy Autonomous Challenge (IAC). Our autonomy stack consists primarily of a multi-modal perception module, a high-speed overtaking planner, a resilient control stack, and a system status manager. We present the details of all components of our autonomy solution, including algorithms, implementation, and unit test results. In addition, this paper outlines the design principles and the results of a systematical analysis. Even though our design principles are derived from the unique application domain of autonomous racing, they can also be applied to a variety of safety-critical, high-cost-of-failure robotics applications. The proposed system was integrated into a full-scale autonomous race car (Dallara AV-21) and field-tested extensively. As a result, team KAIST was one of three teams who qualified and participated in the official IAC race events without any accidents. Our proposed autonomous system successfully completed all missions, including overtaking at speeds of around $220 km/h$ in the IAC@CES2022, the world's first autonomous 1:1 head-to-head race.
Data-Driven Model Identification via Hyperparameter Optimization for Autonomous Racing Systems
Jan 06, 2023In this letter, we propose a model identification method via hyperparameter optimization (MIHO). Our method adopts an efficient explore-exploit strategy to identify the parameters of dynamic models in a data-driven optimization manner. We utilize MIHO for model parameter identification of the AV-21, a full-scaled autonomous race vehicle. We then incorporate the optimized parameters for the design of model-based planning and control systems of our platform. In experiments, the learned parametric models demonstrate good fitness to given datasets and show generalization ability in unseen dynamic scenarios. We further conduct extensive field tests to validate our model-based system. The tests show that our race systems leverage the learned model dynamics and successfully perform obstacle avoidance and high-speed driving over $200 km/h$ at the Indianapolis Motor Speedway and Las Vegas Motor Speedway. The source code for MIHO and videos of the tests are available at https://github.com/hynkis/MIHO.