 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntagonistic Bowden-Cable Actuation of a Lightweight Robotic Hand: Toward Dexterous Manipulation for Payload Constrained Humanoids
Dec 31, 2025Humanoid robots toward human-level dexterity require robotic hands capable of simultaneously providing high grasping force, rapid actuation speeds, multiple degrees of freedom, and lightweight structures within human-like size constraints. Meeting these conflicting requirements remains challenging, as satisfying this combination typically necessitates heavier actuators and bulkier transmission systems, significantly restricting the payload capacity of robot arms. In this letter, we present a lightweight anthropomorphic hand actuated by Bowden cables, which uniquely combines rolling-contact joint optimization with antagonistic cable actuation, enabling single-motor-per-joint control with negligible cable-length deviation. By relocating the actuator module to the torso, the design substantially reduces distal mass while maintaining anthropomorphic scale and dexterity. Additionally, this antagonistic cable actuation eliminates the need for synchronization between motors. Using the proposed methods, the hand assembly with a distal mass of 236g (excluding remote actuators and Bowden sheaths) demonstrated reliable execution of dexterous tasks, exceeding 18N fingertip force and lifting payloads over one hundred times its own mass. Furthermore, robustness was validated through Cutkosky taxonomy grasps and trajectory consistency under perturbed actuator-hand transformations.
Drift-Corrected Monocular VIO and Perception-Aware Planning for Autonomous Drone Racing
Dec 23, 2025



The Abu Dhabi Autonomous Racing League(A2RL) x Drone Champions League competition(DCL) requires teams to perform high-speed autonomous drone racing using only a single camera and a low-quality inertial measurement unit -- a minimal sensor set that mirrors expert human drone racing pilots. This sensor limitation makes the system susceptible to drift from Visual-Inertial Odometry (VIO), particularly during long and fast flights with aggressive maneuvers. This paper presents the system developed for the championship, which achieved a competitive performance. Our approach corrected VIO drift by fusing its output with global position measurements derived from a YOLO-based gate detector using a Kalman filter. A perception-aware planner generated trajectories that balance speed with the need to keep gates visible for the perception system. The system demonstrated high performance, securing podium finishes across multiple categories: third place in the AI Grand Challenge with top speed of 43.2 km/h, second place in the AI Drag Race with over 59 km/h, and second place in the AI Multi-Drone Race. We detail the complete architecture and present a performance analysis based on experimental data from the competition, contributing our insights on building a successful system for monocular vision-based autonomous drone flight.
VLA-R: Vision-Language Action Retrieval toward Open-World End-to-End Autonomous Driving
Nov 16, 2025Exploring open-world situations in an end-to-end manner is a promising yet challenging task due to the need for strong generalization capabilities. In particular, end-to-end autonomous driving in unstructured outdoor environments often encounters conditions that were unfamiliar during training. In this work, we present Vision-Language Action Retrieval (VLA-R), an open-world end-to-end autonomous driving (OW-E2EAD) framework that integrates open-world perception with a novel vision-action retrieval paradigm. We leverage a frozen vision-language model for open-world detection and segmentation to obtain multi-scale, prompt-guided, and interpretable perception features without domain-specific tuning. A Q-Former bottleneck aggregates fine-grained visual representations with language-aligned visual features, bridging perception and action domains. To learn transferable driving behaviors, we introduce a vision-action contrastive learning scheme that aligns vision-language and action embeddings for effective open-world reasoning and action retrieval. Our experiments on a real-world robotic platform demonstrate strong generalization and exploratory performance in unstructured, unseen environments, even with limited data. Demo videos are provided in the supplementary material.
DINO-VO: A Feature-based Visual Odometry Leveraging a Visual Foundation Model
Jul 17, 2025Learning-based monocular visual odometry (VO) poses robustness, generalization, and efficiency challenges in robotics. Recent advances in visual foundation models, such as DINOv2, have improved robustness and generalization in various vision tasks, yet their integration in VO remains limited due to coarse feature granularity. In this paper, we present DINO-VO, a feature-based VO system leveraging DINOv2 visual foundation model for its sparse feature matching. To address the integration challenge, we propose a salient keypoints detector tailored to DINOv2's coarse features. Furthermore, we complement DINOv2's robust-semantic features with fine-grained geometric features, resulting in more localizable representations. Finally, a transformer-based matcher and differentiable pose estimation layer enable precise camera motion estimation by learning good matches. Against prior detector-descriptor networks like SuperPoint, DINO-VO demonstrates greater robustness in challenging environments. Furthermore, we show superior accuracy and generalization of the proposed feature descriptors against standalone DINOv2 coarse features. DINO-VO outperforms prior frame-to-frame VO methods on the TartanAir and KITTI datasets and is competitive on EuRoC dataset, while running efficiently at 72 FPS with less than 1GB of memory usage on a single GPU. Moreover, it performs competitively against Visual SLAM systems on outdoor driving scenarios, showcasing its generalization capabilities.
Learning from Demonstration with Hierarchical Policy Abstractions Toward High-Performance and Courteous Autonomous Racing
Nov 07, 2024



Fully autonomous racing demands not only high-speed driving but also fair and courteous maneuvers. In this paper, we propose an autonomous racing framework that learns complex racing behaviors from expert demonstrations using hierarchical policy abstractions. At the trajectory level, our policy model predicts a dense distribution map indicating the likelihood of trajectories learned from offline demonstrations. The maximum likelihood trajectory is then passed to the control-level policy, which generates control inputs in a residual fashion, considering vehicle dynamics at the limits of performance. We evaluate our framework in a high-fidelity racing simulator and compare it against competing baselines in challenging multi-agent adversarial scenarios. Quantitative and qualitative results show that our trajectory planning policy significantly outperforms the baselines, and the residual control policy improves lap time and tracking accuracy. Moreover, challenging closed-loop experiments with ten opponents show that our framework can overtake other vehicles by understanding nuanced interactions, effectively balancing performance and courtesy like professional drivers.
A Collaborative Team of UAV-Hexapod for an Autonomous Retrieval System in GNSS-Denied Maritime Environments
Oct 12, 2024
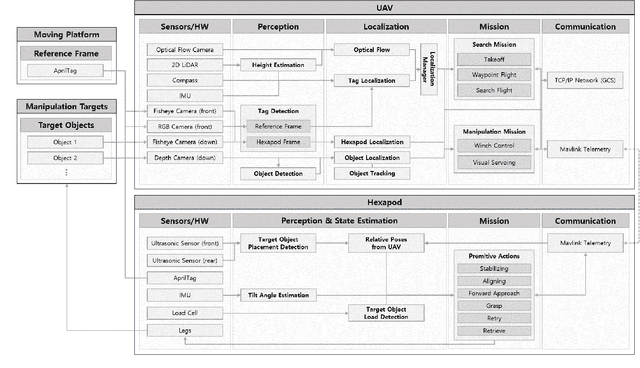
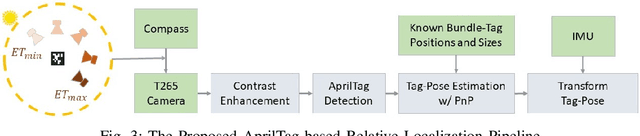
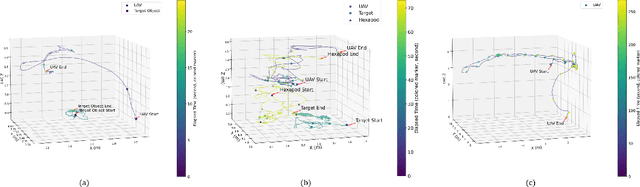
We present an integrated UAV-hexapod robotic system designed for GNSS-denied maritime operations, capable of autonomous deployment and retrieval of a hexapod robot via a winch mechanism installed on a UAV. This system is intended to address the challenges of localization, control, and mobility in dynamic maritime environments. Our solution leverages sensor fusion techniques, combining optical flow, LiDAR, and depth data for precise localization. Experimental results demonstrate the effectiveness of this system in real-world scenarios, validating its performance during field tests in both controlled and operational conditions in the MBZIRC 2023 Maritime Challenge.
SPIBOT: A Drone-Tethered Mobile Gripper for Robust Aerial Object Retrieval in Dynamic Environments
Sep 24, 2024



In real-world field operations, aerial grasping systems face significant challenges in dynamic environments due to strong winds, shifting surfaces, and the need to handle heavy loads. Particularly when dealing with heavy objects, the powerful propellers of the drone can inadvertently blow the target object away as it approaches, making the task even more difficult. To address these challenges, we introduce SPIBOT, a novel drone-tethered mobile gripper system designed for robust and stable autonomous target retrieval. SPIBOT operates via a tether, much like a spider, allowing the drone to maintain a safe distance from the target. To ensure both stable mobility and secure grasping capabilities, SPIBOT is equipped with six legs and sensors to estimate the robot's and mission's states. It is designed with a reduced volume and weight compared to other hexapod robots, allowing it to be easily stowed under the drone and reeled in as needed. Designed for the 2024 MBZIRC Maritime Grand Challenge, SPIBOT is built to retrieve a 1kg target object in the highly dynamic conditions of the moving deck of a ship. This system integrates a real-time action selection algorithm that dynamically adjusts the robot's actions based on proximity to the mission goal and environmental conditions, enabling rapid and robust mission execution. Experimental results across various terrains, including a pontoon on a lake, a grass field, and rubber mats on coastal sand, demonstrate SPIBOT's ability to efficiently and reliably retrieve targets. SPIBOT swiftly converges on the target and completes its mission, even when dealing with irregular initial states and noisy information introduced by the drone.
Skill Q-Network: Learning Adaptive Skill Ensemble for Mapless Navigation in Unknown Environments
Mar 25, 2024This paper focuses on the acquisition of mapless navigation skills within unknown environments. We introduce the Skill Q-Network (SQN), a novel reinforcement learning method featuring an adaptive skill ensemble mechanism. Unlike existing methods, our model concurrently learns a high-level skill decision process alongside multiple low-level navigation skills, all without the need for prior knowledge. Leveraging a tailored reward function for mapless navigation, the SQN is capable of learning adaptive maneuvers that incorporate both exploration and goal-directed skills, enabling effective navigation in new environments. Our experiments demonstrate that our SQN can effectively navigate complex environments, exhibiting a 40% higher performance compared to baseline models. Without explicit guidance, SQN discovers how to combine low-level skill policies, showcasing both goal-directed navigations to reach destinations and exploration maneuvers to escape from local minimum regions in challenging scenarios. Remarkably, our adaptive skill ensemble method enables zero-shot transfer to out-of-distribution domains, characterized by unseen observations from non-convex obstacles or uneven, subterranean-like environments.
TempFuser: Learning Tactical and Agile Flight Maneuvers in Aerial Dogfights using a Long Short-Term Temporal Fusion Transformer
Aug 07, 2023Aerial dogfights necessitate understanding the tactically changing maneuvers from a long-term perspective, along with the rapidly changing aerodynamics from a short-term view. In this paper, we propose a novel long short-term temporal fusion transformer (TempFuser) for a policy network in aerial dogfights. Our method uses two LSTM-based input embeddings to encode long-term, sparse state trajectories, as well as short-term, dense state trajectories. By integrating the two embeddings through a transformer encoder, the method subsequently derives end-to-end flight commands for agile and tactical maneuvers. We formulate a deep reinforcement learning framework to train our TempFuser-based policy model. We then extensively validate our model, demonstrating that it outperforms other baseline models against a diverse range of opponent aircraft in a high-fidelity environment. Our model successfully learns basic fighter maneuvers, human pilot-like tactical maneuvers, and robust supersonic pursuit in low altitudes without explicitly coded prior knowledge. Videos are available at \url{https://sites.google.com/view/tempfuser}
An Autonomous System for Head-to-Head Race: Design, Implementation and Analysis; Team KAIST at the Indy Autonomous Challenge
Mar 16, 2023While the majority of autonomous driving research has concentrated on everyday driving scenarios, further safety and performance improvements of autonomous vehicles require a focus on extreme driving conditions. In this context, autonomous racing is a new area of research that has been attracting considerable interest recently. Due to the fact that a vehicle is driven by its perception, planning, and control limits during racing, numerous research and development issues arise. This paper provides a comprehensive overview of the autonomous racing system built by team KAIST for the Indy Autonomous Challenge (IAC). Our autonomy stack consists primarily of a multi-modal perception module, a high-speed overtaking planner, a resilient control stack, and a system status manager. We present the details of all components of our autonomy solution, including algorithms, implementation, and unit test results. In addition, this paper outlines the design principles and the results of a systematical analysis. Even though our design principles are derived from the unique application domain of autonomous racing, they can also be applied to a variety of safety-critical, high-cost-of-failure robotics applications. The proposed system was integrated into a full-scale autonomous race car (Dallara AV-21) and field-tested extensively. As a result, team KAIST was one of three teams who qualified and participated in the official IAC race events without any accidents. Our proposed autonomous system successfully completed all missions, including overtaking at speeds of around $220 km/h$ in the IAC@CES2022, the world's first autonomous 1:1 head-to-head race.