 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Evaluating Bias in LLMs for Job-Resume Matching: Gender, Race, and Education
Mar 24, 2025Large Language Models (LLMs) offer the potential to automate hiring by matching job descriptions with candidate resumes, streamlining recruitment processes, and reducing operational costs. However, biases inherent in these models may lead to unfair hiring practices, reinforcing societal prejudices and undermining workplace diversity. This study examines the performance and fairness of LLMs in job-resume matching tasks within the English language and U.S. context. It evaluates how factors such as gender, race, and educational background influence model decisions, providing critical insights into the fairness and reliability of LLMs in HR applications. Our findings indicate that while recent models have reduced biases related to explicit attributes like gender and race, implicit biases concerning educational background remain significant. These results highlight the need for ongoing evaluation and the development of advanced bias mitigation strategies to ensure equitable hiring practices when using LLMs in industry settings.
From Single to Multi: How LLMs Hallucinate in Multi-Document Summarization
Oct 17, 2024



Although many studies have investigated and reduced hallucinations in large language models (LLMs) for single-document tasks, research on hallucination in multi-document summarization (MDS) tasks remains largely unexplored. Specifically, it is unclear how the challenges arising from handling multiple documents (e.g., repetition and diversity of information) affect models outputs. In this work, we investigate how hallucinations manifest in LLMs when summarizing topic-specific information from multiple documents. Since no benchmarks exist for investigating hallucinations in MDS, we use existing news and conversation datasets, annotated with topic-specific insights, to create two novel multi-document benchmarks. When evaluating 5 LLMs on our benchmarks, we observe that on average, up to 75% of the content in LLM-generated summary is hallucinated, with hallucinations more likely to occur towards the end of the summaries. Moreover, when summarizing non-existent topic-related information, gpt-3.5-turbo and GPT-4o still generate summaries about 79.35% and 44% of the time, raising concerns about their tendency to fabricate content. To understand the characteristics of these hallucinations, we manually evaluate 700+ insights and find that most errors stem from either failing to follow instructions or producing overly generic insights. Motivated by these observations, we investigate the efficacy of simple post-hoc baselines in mitigating hallucinations but find them only moderately effective. Our results underscore the need for more effective approaches to systematically mitigate hallucinations in MDS. We release our dataset and code at github.com/megagonlabs/Hallucination_MDS.
Holistic Reasoning with Long-Context LMs: A Benchmark for Database Operations on Massive Textual Data
Oct 15, 2024



The rapid increase in textual information means we need more efficient methods to sift through, organize, and understand it all. While retrieval-augmented generation (RAG) models excel in accessing information from large document collections, they struggle with complex tasks that require aggregation and reasoning over information spanning across multiple documents--what we call holistic reasoning. Long-context language models (LCLMs) have great potential for managing large-scale documents, but their holistic reasoning capabilities remain unclear. In this work, we introduce HoloBench, a novel framework that brings database reasoning operations into text-based contexts, making it easier to systematically evaluate how LCLMs handle holistic reasoning across large documents. Our approach adjusts key factors such as context length, information density, distribution of information, and query complexity to evaluate LCLMs comprehensively. Our experiments show that the amount of information in the context has a bigger influence on LCLM performance than the actual context length. Furthermore, the complexity of queries affects performance more than the amount of information, particularly for different types of queries. Interestingly, queries that involve finding maximum or minimum values are easier for LCLMs and are less affected by context length, even though they pose challenges for RAG systems. However, tasks requiring the aggregation of multiple pieces of information show a noticeable drop in accuracy as context length increases. Additionally, we find that while grouping relevant information generally improves performance, the optimal positioning varies across models. Our findings surface both the advancements and the ongoing challenges in achieving a holistic understanding of long contexts.
A Blueprint Architecture of Compound AI Systems for Enterprise
Jun 02, 2024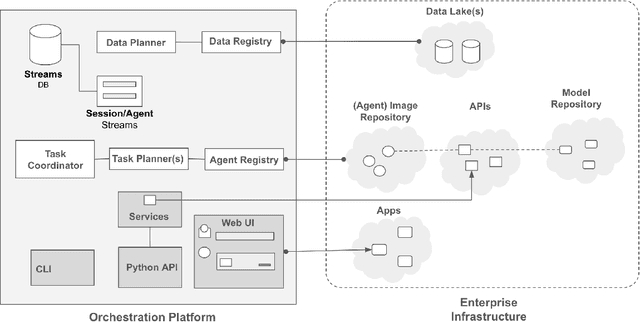
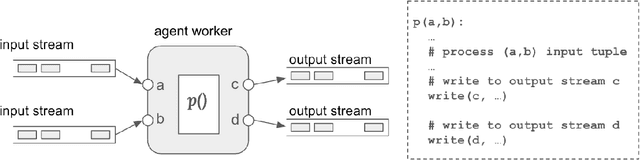
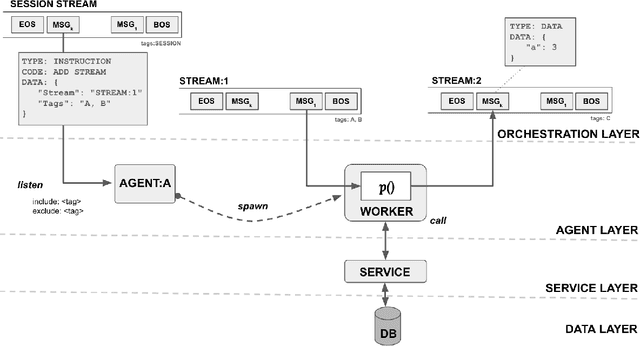
Large Language Models (LLMs) have showcased remarkable capabilities surpassing conventional NLP challenges, creating opportunities for use in production use cases. Towards this goal, there is a notable shift to building compound AI systems, wherein LLMs are integrated into an expansive software infrastructure with many components like models, retrievers, databases and tools. In this paper, we introduce a blueprint architecture for compound AI systems to operate in enterprise settings cost-effectively and feasibly. Our proposed architecture aims for seamless integration with existing compute and data infrastructure, with ``stream'' serving as the key orchestration concept to coordinate data and instructions among agents and other components. Task and data planners, respectively, break down, map, and optimize tasks and data to available agents and data sources defined in respective registries, given production constraints such as accuracy and latency.
AmbigNLG: Addressing Task Ambiguity in Instruction for NLG
Feb 27, 2024



In this study, we introduce AmbigNLG, a new task designed to tackle the challenge of task ambiguity in instructions for Natural Language Generation (NLG) tasks. Despite the impressive capabilities of Large Language Models (LLMs) in understanding and executing a wide range of tasks through natural language interaction, their performance is significantly hindered by the ambiguity present in real-world instructions. To address this, AmbigNLG seeks to identify and mitigate such ambiguities, aiming to refine instructions to match user expectations better. We introduce a dataset, AmbigSNI-NLG, consisting of 2,500 instances, and develop an ambiguity taxonomy for categorizing and annotating instruction ambiguities. Our approach demonstrates substantial improvements in text generation quality, highlighting the critical role of clear and specific instructions in enhancing LLM performance in NLG tasks.
Retrieval Helps or Hurts? A Deeper Dive into the Efficacy of Retrieval Augmentation to Language Models
Feb 21, 2024While large language models (LMs) demonstrate remarkable performance, they encounter challenges in providing accurate responses when queried for information beyond their pre-trained memorization. Although augmenting them with relevant external information can mitigate these issues, failure to consider the necessity of retrieval may adversely affect overall performance. Previous research has primarily focused on examining how entities influence retrieval models and knowledge recall in LMs, leaving other aspects relatively unexplored. In this work, our goal is to offer a more detailed, fact-centric analysis by exploring the effects of combinations of entities and relations. To facilitate this, we construct a new question answering (QA) dataset called WiTQA (Wikipedia Triple Question Answers). This dataset includes questions about entities and relations of various popularity levels, each accompanied by a supporting passage. Our extensive experiments with diverse LMs and retrievers reveal when retrieval does not consistently enhance LMs from the viewpoints of fact-centric popularity.Confirming earlier findings, we observe that larger LMs excel in recalling popular facts. However, they notably encounter difficulty with infrequent entity-relation pairs compared to retrievers. Interestingly, they can effectively retain popular relations of less common entities. We demonstrate the efficacy of our finer-grained metric and insights through an adaptive retrieval system that selectively employs retrieval and recall based on the frequencies of entities and relations in the question.
Distilling Large Language Models using Skill-Occupation Graph Context for HR-Related Tasks
Nov 10, 2023



Numerous HR applications are centered around resumes and job descriptions. While they can benefit from advancements in NLP, particularly large language models, their real-world adoption faces challenges due to absence of comprehensive benchmarks for various HR tasks, and lack of smaller models with competitive capabilities. In this paper, we aim to bridge this gap by introducing the Resume-Job Description Benchmark (RJDB). We meticulously craft this benchmark to cater to a wide array of HR tasks, including matching and explaining resumes to job descriptions, extracting skills and experiences from resumes, and editing resumes. To create this benchmark, we propose to distill domain-specific knowledge from a large language model (LLM). We rely on a curated skill-occupation graph to ensure diversity and provide context for LLMs generation. Our benchmark includes over 50 thousand triples of job descriptions, matched resumes and unmatched resumes. Using RJDB, we train multiple smaller student models. Our experiments reveal that the student models achieve near/better performance than the teacher model (GPT-4), affirming the effectiveness of the benchmark. Additionally, we explore the utility of RJDB on out-of-distribution data for skill extraction and resume-job description matching, in zero-shot and weak supervision manner. We release our datasets and code to foster further research and industry applications.
XATU: A Fine-grained Instruction-based Benchmark for Explainable Text Updates
Sep 20, 2023



Text editing is a crucial task that involves modifying text to better align with user intents. However, existing text editing benchmark datasets have limitations in providing only coarse-grained instructions. Consequently, although the edited output may seem reasonable, it often deviates from the intended changes outlined in the gold reference, resulting in low evaluation scores. To comprehensively investigate the text editing capabilities of large language models, this paper introduces XATU, the first benchmark specifically designed for fine-grained instruction-based explainable text editing. XATU covers a wide range of topics and text types, incorporating lexical, syntactic, semantic, and knowledge-intensive edits. To enhance interpretability, we leverage high-quality data sources and human annotation, resulting in a benchmark that includes fine-grained instructions and gold-standard edit explanations. By evaluating existing open and closed large language models against our benchmark, we demonstrate the effectiveness of instruction tuning and the impact of underlying architecture across various editing tasks. Furthermore, extensive experimentation reveals the significant role of explanations in fine-tuning language models for text editing tasks. The benchmark will be open-sourced to support reproduction and facilitate future research.
Less is More for Long Document Summary Evaluation by LLMs
Sep 14, 2023Large Language Models (LLMs) have shown promising performance in summary evaluation tasks, yet they face challenges such as high computational costs and the Lost-in-the-Middle problem where important information in the middle of long documents is often overlooked. To address these issues, this paper introduces a novel approach, Extract-then-Evaluate, which involves extracting key sentences from a long source document and then evaluating the summary by prompting LLMs. The results reveal that the proposed method not only significantly reduces evaluation costs but also exhibits a higher correlation with human evaluations. Furthermore, we provide practical recommendations for optimal document length and sentence extraction methods, contributing to the development of cost-effective yet more accurate methods for LLM-based text generation evaluation.