 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Probabilistic Question Answering Over Tabular Data
Jun 25, 2025Current approaches for question answering (QA) over tabular data, such as NL2SQL systems, perform well for factual questions where answers are directly retrieved from tables. However, they fall short on probabilistic questions requiring reasoning under uncertainty. In this paper, we introduce a new benchmark LUCARIO and a framework for probabilistic QA over large tabular data. Our method induces Bayesian Networks from tables, translates natural language queries into probabilistic queries, and uses large language models (LLMs) to generate final answers. Empirical results demonstrate significant improvements over baselines, highlighting the benefits of hybrid symbolic-neural reasoning.
Effectiveness of Prompt Optimization in NL2SQL Systems
May 26, 2025NL2SQL approaches have greatly benefited from the impressive capabilities of large language models (LLMs). In particular, bootstrapping an NL2SQL system for a specific domain can be as simple as instructing an LLM with sufficient contextual information, such as schema details and translation demonstrations. However, building an accurate system still requires the rigorous task of selecting the right context for each query-including identifying relevant schema elements, cell values, and suitable exemplars that help the LLM understand domain-specific nuances. Retrieval-based methods have become the go-to approach for identifying such context. While effective, these methods introduce additional inference-time costs due to the retrieval process. In this paper, we argue that production scenarios demand high-precision, high-performance NL2SQL systems, rather than simply high-quality SQL generation, which is the focus of most current NL2SQL approaches. In such scenarios, the careful selection of a static set of exemplars-capturing the intricacies of the query log, target database, SQL constructs, and execution latencies-plays a more crucial role than exemplar selection based solely on similarity. The key challenge, however, lies in identifying a representative set of exemplars for a given production setting. To this end, we propose a prompt optimization framework that not only addresses the high-precision requirement but also optimizes the performance of the generated SQL through multi-objective optimization. Preliminary empirical analysis demonstrates the effectiveness of the proposed framework.
CypherBench: Towards Precise Retrieval over Full-scale Modern Knowledge Graphs in the LLM Era
Dec 24, 2024Retrieval from graph data is crucial for augmenting large language models (LLM) with both open-domain knowledge and private enterprise data, and it is also a key component in the recent GraphRAG system (edge et al., 2024). Despite decades of research on knowledge graphs and knowledge base question answering, leading LLM frameworks (e.g. Langchain and LlamaIndex) have only minimal support for retrieval from modern encyclopedic knowledge graphs like Wikidata. In this paper, we analyze the root cause and suggest that modern RDF knowledge graphs (e.g. Wikidata, Freebase) are less efficient for LLMs due to overly large schemas that far exceed the typical LLM context window, use of resource identifiers, overlapping relation types and lack of normalization. As a solution, we propose property graph views on top of the underlying RDF graph that can be efficiently queried by LLMs using Cypher. We instantiated this idea on Wikidata and introduced CypherBench, the first benchmark with 11 large-scale, multi-domain property graphs with 7.8 million entities and over 10,000 questions. To achieve this, we tackled several key challenges, including developing an RDF-to-property graph conversion engine, creating a systematic pipeline for text-to-Cypher task generation, and designing new evaluation metrics.
FactLens: Benchmarking Fine-Grained Fact Verification
Nov 08, 2024



Large Language Models (LLMs) have shown impressive capability in language generation and understanding, but their tendency to hallucinate and produce factually incorrect information remains a key limitation. To verify LLM-generated contents and claims from other sources, traditional verification approaches often rely on holistic models that assign a single factuality label to complex claims, potentially obscuring nuanced errors. In this paper, we advocate for a shift toward fine-grained verification, where complex claims are broken down into smaller sub-claims for individual verification, allowing for more precise identification of inaccuracies, improved transparency, and reduced ambiguity in evidence retrieval. However, generating sub-claims poses challenges, such as maintaining context and ensuring semantic equivalence with respect to the original claim. We introduce FactLens, a benchmark for evaluating fine-grained fact verification, with metrics and automated evaluators of sub-claim quality. The benchmark data is manually curated to ensure high-quality ground truth. Our results show alignment between automated FactLens evaluators and human judgments, and we discuss the impact of sub-claim characteristics on the overall verification performance.
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Jun 02, 2024Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
A Blueprint Architecture of Compound AI Systems for Enterprise
Jun 02, 2024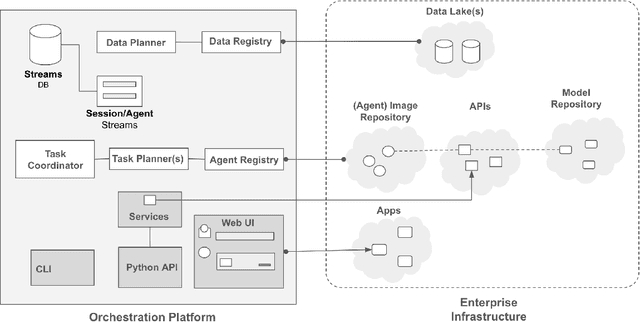
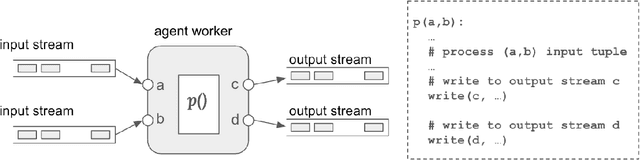
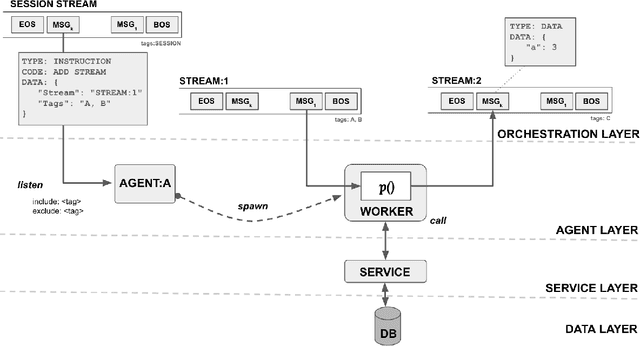
Large Language Models (LLMs) have showcased remarkable capabilities surpassing conventional NLP challenges, creating opportunities for use in production use cases. Towards this goal, there is a notable shift to building compound AI systems, wherein LLMs are integrated into an expansive software infrastructure with many components like models, retrievers, databases and tools. In this paper, we introduce a blueprint architecture for compound AI systems to operate in enterprise settings cost-effectively and feasibly. Our proposed architecture aims for seamless integration with existing compute and data infrastructure, with ``stream'' serving as the key orchestration concept to coordinate data and instructions among agents and other components. Task and data planners, respectively, break down, map, and optimize tasks and data to available agents and data sources defined in respective registries, given production constraints such as accuracy and latency.
MEGAnno+: A Human-LLM Collaborative Annotation System
Feb 28, 2024
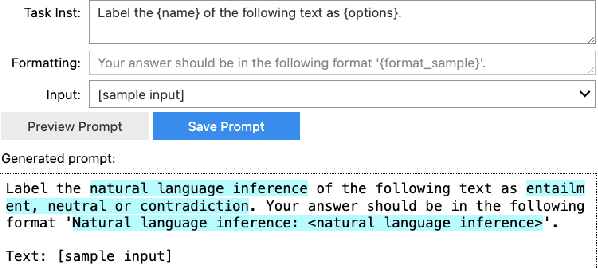

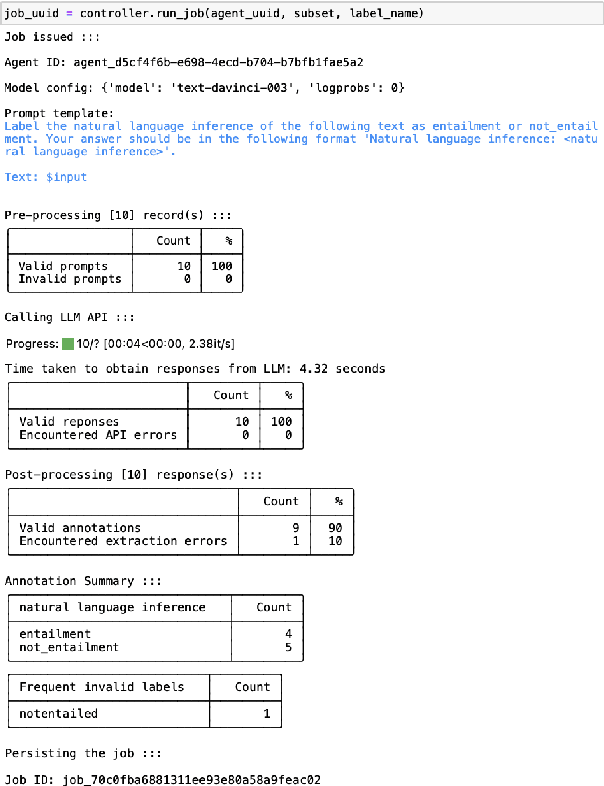
Large language models (LLMs) can label data faster and cheaper than humans for various NLP tasks. Despite their prowess, LLMs may fall short in understanding of complex, sociocultural, or domain-specific context, potentially leading to incorrect annotations. Therefore, we advocate a collaborative approach where humans and LLMs work together to produce reliable and high-quality labels. We present MEGAnno+, a human-LLM collaborative annotation system that offers effective LLM agent and annotation management, convenient and robust LLM annotation, and exploratory verification of LLM labels by humans.
Reasoning Capacity in Multi-Agent Systems: Limitations, Challenges and Human-Centered Solutions
Feb 02, 2024Remarkable performance of large language models (LLMs) in a variety of tasks brings forth many opportunities as well as challenges of utilizing them in production settings. Towards practical adoption of LLMs, multi-agent systems hold great promise to augment, integrate, and orchestrate LLMs in the larger context of enterprise platforms that use existing proprietary data and models to tackle complex real-world tasks. Despite the tremendous success of these systems, current approaches rely on narrow, single-focus objectives for optimization and evaluation, often overlooking potential constraints in real-world scenarios, including restricted budgets, resources and time. Furthermore, interpreting, analyzing, and debugging these systems requires different components to be evaluated in relation to one another. This demand is currently not feasible with existing methodologies. In this postion paper, we introduce the concept of reasoning capacity as a unifying criterion to enable integration of constraints during optimization and establish connections among different components within the system, which also enable a more holistic and comprehensive approach to evaluation. We present a formal definition of reasoning capacity and illustrate its utility in identifying limitations within each component of the system. We then argue how these limitations can be addressed with a self-reflective process wherein human-feedback is used to alleviate shortcomings in reasoning and enhance overall consistency of the system.
Characterizing Large Language Models as Rationalizers of Knowledge-intensive Tasks
Nov 09, 2023



Large language models (LLMs) are proficient at generating fluent text with minimal task-specific supervision. Yet, their ability to provide well-grounded rationalizations for knowledge-intensive tasks remains under-explored. Such tasks, like commonsense multiple-choice questions, require rationales based on world knowledge to support predictions and refute alternate options. We consider the task of generating knowledge-guided rationalization in natural language by using expert-written examples in a few-shot manner. Surprisingly, crowd-workers preferred knowledge-grounded rationales over crowdsourced rationalizations, citing their factuality, sufficiency, and comprehensive refutations. Although LLMs-generated rationales were preferable, further improvements in conciseness and novelty are required. In another study, we show how rationalization of incorrect model predictions erodes humans' trust in LLM-generated rationales. Motivated by these observations, we create a two-stage pipeline to review task predictions and eliminate potential incorrect decisions before rationalization, enabling trustworthy rationale generation.
Towards Multifaceted Human-Centered AI
Jan 09, 2023Human-centered AI workflows involve stakeholders with multiple roles interacting with each other and automated agents to accomplish diverse tasks. In this paper, we call for a holistic view when designing support mechanisms, such as interaction paradigms, interfaces, and systems, for these multifaceted workflows.