 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERUPT: Efficient Rendering with Unposed Patch Transformer
Mar 31, 2025This work addresses the problem of novel view synthesis in diverse scenes from small collections of RGB images. We propose ERUPT (Efficient Rendering with Unposed Patch Transformer) a state-of-the-art scene reconstruction model capable of efficient scene rendering using unposed imagery. We introduce patch-based querying, in contrast to existing pixel-based queries, to reduce the compute required to render a target view. This makes our model highly efficient both during training and at inference, capable of rendering at 600 fps on commercial hardware. Notably, our model is designed to use a learned latent camera pose which allows for training using unposed targets in datasets with sparse or inaccurate ground truth camera pose. We show that our approach can generalize on large real-world data and introduce a new benchmark dataset (MSVS-1M) for latent view synthesis using street-view imagery collected from Mapillary. In contrast to NeRF and Gaussian Splatting, which require dense imagery and precise metadata, ERUPT can render novel views of arbitrary scenes with as few as five unposed input images. ERUPT achieves better rendered image quality than current state-of-the-art methods for unposed image synthesis tasks, reduces labeled data requirements by ~95\% and decreases computational requirements by an order of magnitude, providing efficient novel view synthesis for diverse real-world scenes.
Oogway: Designing, Implementing, and Testing an AUV for RoboSub 2023
Oct 13, 2024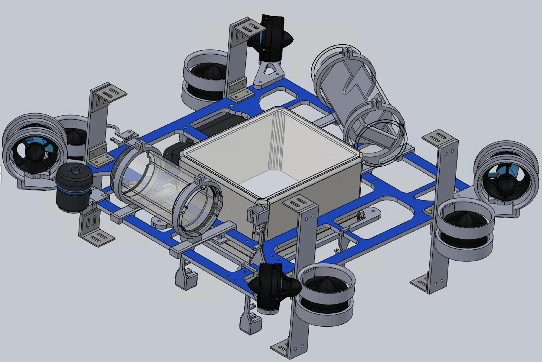


The Duke Robotics Club is proud to present our robot for the 2023 RoboSub Competition: Oogway. Oogway marks one of the largest design overhauls in club history. Beyond a revamped formfactor, some of Oogway's notable features include all-new computer vision software, advanced sonar integration, novel acoustics hardware processing, and upgraded stereoscopic cameras. Oogway was built on the principle of independent, well-integrated, and reliable subsystems. Individual components and subsystems were tested and designed separately. Oogway's most advanced capabilities are a result of the tight integration between these subsystems. Such examples include sonar-assisted computer vision algorithms and robot-agnostic controls configured in part through the robot's 3D model. The success of constructing and testing Oogway in under 2 year's time can be attributed to 20+ contributing club members, supporters within Duke's Pratt School of Engineering, and outside sponsors.
Technical Design Review of Duke Robotics Club's Oogway: An AUV for RoboSub 2024
Oct 13, 2024



The Duke Robotics Club is proud to present our robot for the 2024 RoboSub Competition: Oogway. Now in its second year, Oogway has been dramatically upgraded in both its capabilities and reliability. Oogway was built on the principle of independent, well-integrated, and reliable subsystems. Individual components and subsystems were tested and designed separately. Oogway's most advanced capabilities are a result of the tight integration between these subsystems. Such examples include a re-envisioned controls system, an entirely new electrical stack, advanced sonar integration, additional cameras and system monitoring, a new marker dropper, and a watertight capsule mechanism. These additions enabled Oogway to prequalify for Robosub 2024.
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Jun 02, 2024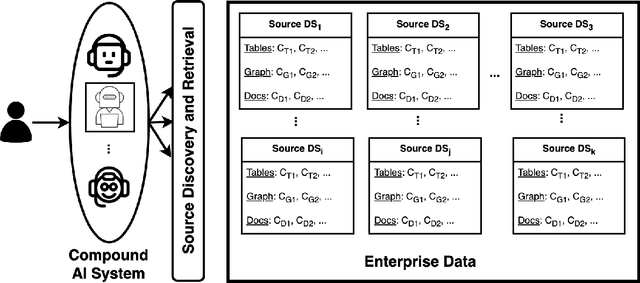

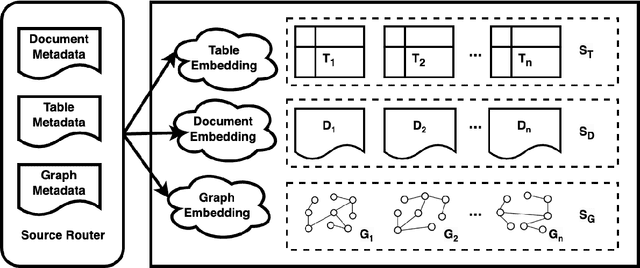
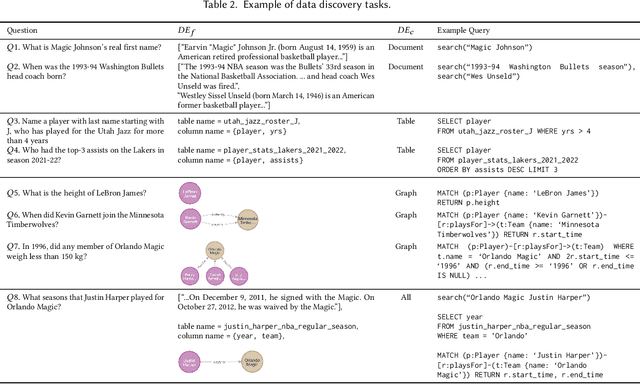
Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
Resource Aware Person Re-identification across Multiple Resolutions
Oct 02, 2018
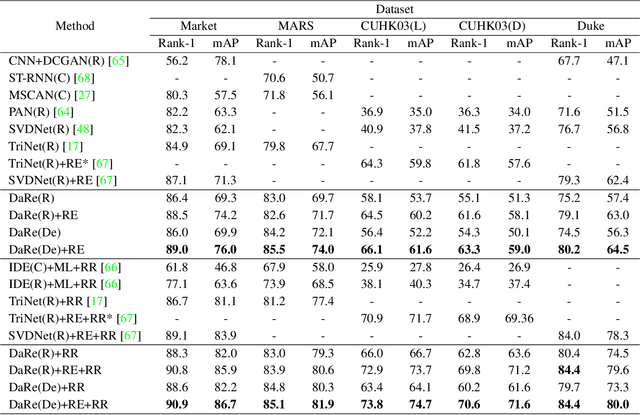
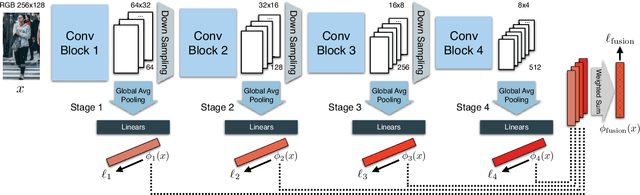
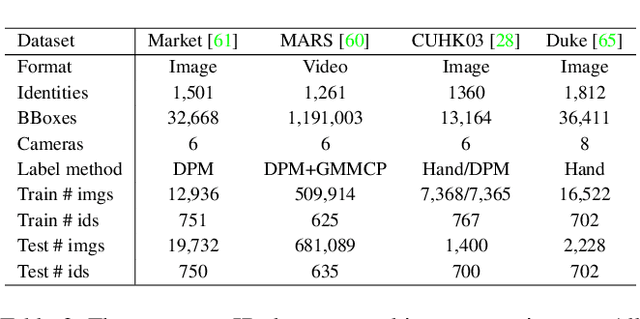
Not all people are equally easy to identify: color statistics might be enough for some cases while others might require careful reasoning about high- and low-level details. However, prevailing person re-identification(re-ID) methods use one-size-fits-all high-level embeddings from deep convolutional networks for all cases. This might limit their accuracy on difficult examples or makes them needlessly expensive for the easy ones. To remedy this, we present a new person re-ID model that combines effective embeddings built on multiple convolutional network layers, trained with deep-supervision. On traditional re-ID benchmarks, our method improves substantially over the previous state-of-the-art results on all five datasets that we evaluate on. We then propose two new formulations of the person re-ID problem under resource-constraints, and show how our model can be used to effectively trade off accuracy and computation in the presence of resource constraints. Code and pre-trained models are available at https://github.com/mileyan/DARENet.
Minibatch Gibbs Sampling on Large Graphical Models
Jun 15, 2018

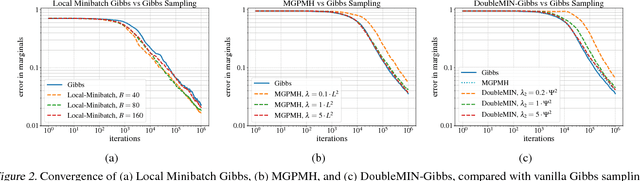
Gibbs sampling is the de facto Markov chain Monte Carlo method used for inference and learning on large scale graphical models. For complicated factor graphs with lots of factors, the performance of Gibbs sampling can be limited by the computational cost of executing a single update step of the Markov chain. This cost is proportional to the degree of the graph, the number of factors adjacent to each variable. In this paper, we show how this cost can be reduced by using minibatching: subsampling the factors to form an estimate of their sum. We introduce several minibatched variants of Gibbs, show that they can be made unbiased, prove bounds on their convergence rates, and show that under some conditions they can result in asymptotic single-update-run-time speedups over plain Gibbs sampling.