 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Moments are Surprisingly Effective for Plug-and-Play Diffusion Sampling
Mar 17, 2026Guided diffusion sampling relies on approximating often intractable likelihood scores, which introduces significant noise into the sampling dynamics. We propose using adaptive moment estimation to stabilize these noisy likelihood scores during sampling. Despite its simplicity, our approach achieves state-of-the-art results on image restoration and class-conditional generation tasks, outperforming more complicated methods, which are often computationally more expensive. We provide empirical analysis of our method on both synthetic and real data, demonstrating that mitigating gradient noise through adaptive moments offers an effective way to improve alignment.
Learning from Synthetic Data Improves Multi-hop Reasoning
Mar 02, 2026Reinforcement Learning (RL) has been shown to significantly boost reasoning capabilities of large language models (LLMs) in math, coding, and multi-hop reasoning tasks. However, RL fine-tuning requires abundant high-quality verifiable data, often sourced from human annotations, generated from frontier LLMs, or scored by LLM-based verifiers. All three have considerable limitations: human-annotated datasets are small and expensive to curate, LLM-generated data is hallucination-prone and costly, and LLM-based verifiers are inaccurate and slow. In this work, we investigate a cheaper alternative: RL fine-tuning on rule-generated synthetic data for multi-hop reasoning tasks. We discover that LLMs fine-tuned on synthetic data perform significantly better on popular real-world question-answering benchmarks, despite the synthetic data containing only fictional knowledge. On stratifying performance by question difficulty, we find that synthetic data teaches LLMs to compose knowledge -- a fundamental and generalizable reasoning skill. Our work highlights rule-generated synthetic reasoning data as a free and scalable resource to improve LLM reasoning capabilities.
Stop-Think-AutoRegress: Language Modeling with Latent Diffusion Planning
Feb 24, 2026The Stop-Think-AutoRegress Language Diffusion Model (STAR-LDM) integrates latent diffusion planning with autoregressive generation. Unlike conventional autoregressive language models limited to token-by-token decisions, STAR-LDM incorporates a "thinking" phase that pauses generation to refine a semantic plan through diffusion before continuing. This enables global planning in continuous space prior to committing to discrete tokens. Evaluations show STAR-LDM significantly outperforms similar-sized models on language understanding benchmarks and achieves $>70\%$ win rates in LLM-as-judge comparisons for narrative coherence and commonsense reasoning. The architecture also allows straightforward control through lightweight classifiers, enabling fine-grained steering of attributes without model retraining while maintaining better fluency-control trade-offs than specialized approaches.
Improving Multislice Electron Ptychography with a Generative Prior
Jul 23, 2025Multislice electron ptychography (MEP) is an inverse imaging technique that computationally reconstructs the highest-resolution images of atomic crystal structures from diffraction patterns. Available algorithms often solve this inverse problem iteratively but are both time consuming and produce suboptimal solutions due to their ill-posed nature. We develop MEP-Diffusion, a diffusion model trained on a large database of crystal structures specifically for MEP to augment existing iterative solvers. MEP-Diffusion is easily integrated as a generative prior into existing reconstruction methods via Diffusion Posterior Sampling (DPS). We find that this hybrid approach greatly enhances the quality of the reconstructed 3D volumes, achieving a 90.50% improvement in SSIM over existing methods.
Memento: Note-Taking for Your Future Self
Jun 25, 2025Large language models (LLMs) excel at reasoning-only tasks, but struggle when reasoning must be tightly coupled with retrieval, as in multi-hop question answering. To overcome these limitations, we introduce a prompting strategy that first decomposes a complex question into smaller steps, then dynamically constructs a database of facts using LLMs, and finally pieces these facts together to solve the question. We show how this three-stage strategy, which we call Memento, can boost the performance of existing prompting strategies across diverse settings. On the 9-step PhantomWiki benchmark, Memento doubles the performance of chain-of-thought (CoT) when all information is provided in context. On the open-domain version of 2WikiMultiHopQA, CoT-RAG with Memento improves over vanilla CoT-RAG by more than 20 F1 percentage points and over the multi-hop RAG baseline, IRCoT, by more than 13 F1 percentage points. On the challenging MuSiQue dataset, Memento improves ReAct by more than 3 F1 percentage points, demonstrating its utility in agentic settings.
Pre-training Large Memory Language Models with Internal and External Knowledge
May 21, 2025Neural language models are black-boxes -- both linguistic patterns and factual knowledge are distributed across billions of opaque parameters. This entangled encoding makes it difficult to reliably inspect, verify, or update specific facts. We propose a new class of language models, Large Memory Language Models (LMLM) with a pre-training recipe that stores factual knowledge in both internal weights and an external database. Our approach strategically masks externally retrieved factual values from the training loss, thereby teaching the model to perform targeted lookups rather than relying on memorization in model weights. Our experiments demonstrate that LMLMs achieve competitive performance compared to significantly larger, knowledge-dense LLMs on standard benchmarks, while offering the advantages of explicit, editable, and verifiable knowledge bases. This work represents a fundamental shift in how language models interact with and manage factual knowledge.
INPROVF: Leveraging Large Language Models to Repair High-level Robot Controllers from Assumption Violations
Mar 17, 2025



This paper presents INPROVF, an automatic framework that combines large language models (LLMs) and formal methods to speed up the repair process of high-level robot controllers. Previous approaches based solely on formal methods are computationally expensive and cannot scale to large state spaces. In contrast, INPROVF uses LLMs to generate repair candidates, and formal methods to verify their correctness. To improve the quality of these candidates, our framework first translates the symbolic representations of the environment and controllers into natural language descriptions. If a candidate fails the verification, INPROVF provides feedback on potential unsafe behaviors or unsatisfied tasks, and iteratively prompts LLMs to generate improved solutions. We demonstrate the effectiveness of INPROVF through 12 violations with various workspaces, tasks, and state space sizes.
$Q\sharp$: Provably Optimal Distributional RL for LLM Post-Training
Feb 27, 2025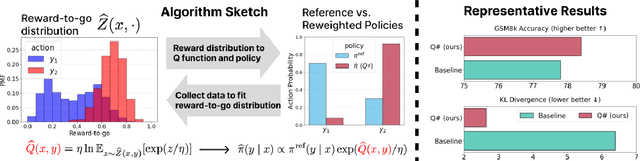



Reinforcement learning (RL) post-training is crucial for LLM alignment and reasoning, but existing policy-based methods, such as PPO and DPO, can fall short of fixing shortcuts inherited from pre-training. In this work, we introduce $Q\sharp$, a value-based algorithm for KL-regularized RL that guides the reference policy using the optimal regularized $Q$ function. We propose to learn the optimal $Q$ function using distributional RL on an aggregated online dataset. Unlike prior value-based baselines that guide the model using unregularized $Q$-values, our method is theoretically principled and provably learns the optimal policy for the KL-regularized RL problem. Empirically, $Q\sharp$ outperforms prior baselines in math reasoning benchmarks while maintaining a smaller KL divergence to the reference policy. Theoretically, we establish a reduction from KL-regularized RL to no-regret online learning, providing the first bounds for deterministic MDPs under only realizability. Thanks to distributional RL, our bounds are also variance-dependent and converge faster when the reference policy has small variance. In sum, our results highlight $Q\sharp$ as an effective approach for post-training LLMs, offering both improved performance and theoretical guarantees. The code can be found at https://github.com/jinpz/q_sharp.
PhantomWiki: On-Demand Datasets for Reasoning and Retrieval Evaluation
Feb 27, 2025High-quality benchmarks are essential for evaluating reasoning and retrieval capabilities of large language models (LLMs). However, curating datasets for this purpose is not a permanent solution as they are prone to data leakage and inflated performance results. To address these challenges, we propose PhantomWiki: a pipeline to generate unique, factually consistent document corpora with diverse question-answer pairs. Unlike prior work, PhantomWiki is neither a fixed dataset, nor is it based on any existing data. Instead, a new PhantomWiki instance is generated on demand for each evaluation. We vary the question difficulty and corpus size to disentangle reasoning and retrieval capabilities respectively, and find that PhantomWiki datasets are surprisingly challenging for frontier LLMs. Thus, we contribute a scalable and data leakage-resistant framework for disentangled evaluation of reasoning, retrieval, and tool-use abilities. Our code is available at https://github.com/kilian-group/phantom-wiki.
Rethinking LLM Unlearning Objectives: A Gradient Perspective and Go Beyond
Feb 26, 2025



Large language models (LLMs) should undergo rigorous audits to identify potential risks, such as copyright and privacy infringements. Once these risks emerge, timely updates are crucial to remove undesirable responses, ensuring legal and safe model usage. It has spurred recent research into LLM unlearning, focusing on erasing targeted undesirable knowledge without compromising the integrity of other, non-targeted responses. Existing studies have introduced various unlearning objectives to pursue LLM unlearning without necessitating complete retraining. However, each of these objectives has unique properties, and no unified framework is currently available to comprehend them thoroughly. To fill the gap, we propose a toolkit of the gradient effect (G-effect), quantifying the impacts of unlearning objectives on model performance from a gradient perspective. A notable advantage is its broad ability to detail the unlearning impacts from various aspects across instances, updating steps, and LLM layers. Accordingly, the G-effect offers new insights into identifying drawbacks of existing unlearning objectives, further motivating us to explore a series of new solutions for their mitigation and improvements. Finally, we outline promising directions that merit further studies, aiming at contributing to the community to advance this important field.