 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemento: Note-Taking for Your Future Self
Jun 25, 2025Large language models (LLMs) excel at reasoning-only tasks, but struggle when reasoning must be tightly coupled with retrieval, as in multi-hop question answering. To overcome these limitations, we introduce a prompting strategy that first decomposes a complex question into smaller steps, then dynamically constructs a database of facts using LLMs, and finally pieces these facts together to solve the question. We show how this three-stage strategy, which we call Memento, can boost the performance of existing prompting strategies across diverse settings. On the 9-step PhantomWiki benchmark, Memento doubles the performance of chain-of-thought (CoT) when all information is provided in context. On the open-domain version of 2WikiMultiHopQA, CoT-RAG with Memento improves over vanilla CoT-RAG by more than 20 F1 percentage points and over the multi-hop RAG baseline, IRCoT, by more than 13 F1 percentage points. On the challenging MuSiQue dataset, Memento improves ReAct by more than 3 F1 percentage points, demonstrating its utility in agentic settings.
Cascaded Debiasing : Studying the Cumulative Effect of Multiple Fairness-Enhancing Interventions
Feb 08, 2022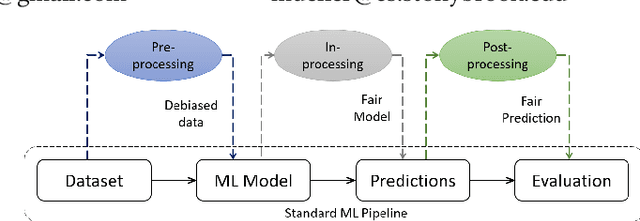


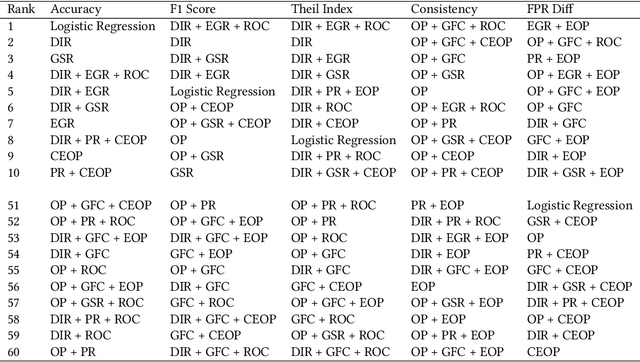
Understanding the cumulative effect of multiple fairness enhancing interventions at different stages of the machine learning (ML) pipeline is a critical and underexplored facet of the fairness literature. Such knowledge can be valuable to data scientists/ML practitioners in designing fair ML pipelines. This paper takes the first step in exploring this area by undertaking an extensive empirical study comprising 60 combinations of interventions, 9 fairness metrics, 2 utility metrics (Accuracy and F1 Score) across 4 benchmark datasets. We quantitatively analyze the experimental data to measure the impact of multiple interventions on fairness, utility and population groups. We found that applying multiple interventions results in better fairness and lower utility than individual interventions on aggregate. However, adding more interventions do no always result in better fairness or worse utility. The likelihood of achieving high performance (F1 Score) along with high fairness increases with larger number of interventions. On the downside, we found that fairness-enhancing interventions can negatively impact different population groups, especially the privileged group. This study highlights the need for new fairness metrics that account for the impact on different population groups apart from just the disparity between groups. Lastly, we offer a list of combinations of interventions that perform best for different fairness and utility metrics to aid the design of fair ML pipelines.