 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
GriDiT: Factorized Grid-Based Diffusion for Efficient Long Image Sequence Generation
Dec 24, 2025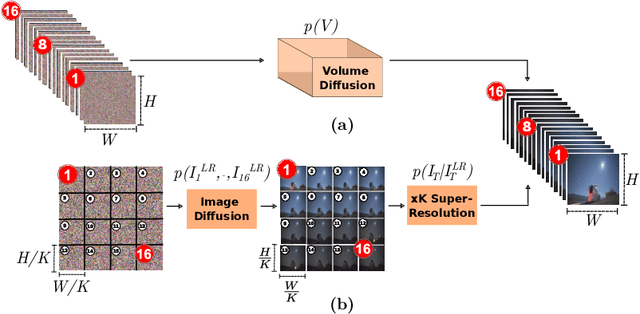
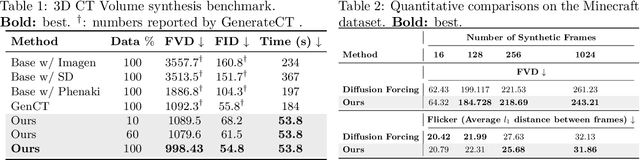
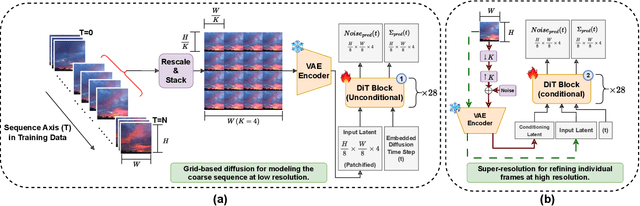
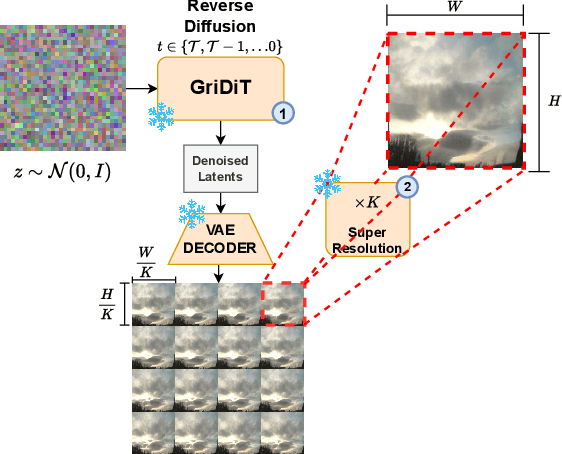
Modern deep learning methods typically treat image sequences as large tensors of sequentially stacked frames. However, is this straightforward representation ideal given the current state-of-the-art (SoTA)? In this work, we address this question in the context of generative models and aim to devise a more effective way of modeling image sequence data. Observing the inefficiencies and bottlenecks of current SoTA image sequence generation methods, we showcase that rather than working with large tensors, we can improve the generation process by factorizing it into first generating the coarse sequence at low resolution and then refining the individual frames at high resolution. We train a generative model solely on grid images comprising subsampled frames. Yet, we learn to generate image sequences, using the strong self-attention mechanism of the Diffusion Transformer (DiT) to capture correlations between frames. In effect, our formulation extends a 2D image generator to operate as a low-resolution 3D image-sequence generator without introducing any architectural modifications. Subsequently, we super-resolve each frame individually to add the sequence-independent high-resolution details. This approach offers several advantages and can overcome key limitations of the SoTA in this domain. Compared to existing image sequence generation models, our method achieves superior synthesis quality and improved coherence across sequences. It also delivers high-fidelity generation of arbitrary-length sequences and increased efficiency in inference time and training data usage. Furthermore, our straightforward formulation enables our method to generalize effectively across diverse data domains, which typically require additional priors and supervision to model in a generative context. Our method consistently outperforms SoTA in quality and inference speed (at least twice-as-fast) across datasets.
Smart Starts: Accelerating Convergence through Uncommon Region Exploration
May 08, 2025Initialization profoundly affects evolutionary algorithm (EA) efficacy by dictating search trajectories and convergence. This study introduces a hybrid initialization strategy combining empty-space search algorithm (ESA) and opposition-based learning (OBL). OBL initially generates a diverse population, subsequently augmented by ESA, which identifies under-explored regions. This synergy enhances population diversity, accelerates convergence, and improves EA performance on complex, high-dimensional optimization problems. Benchmark results demonstrate the proposed method's superiority in solution quality and convergence speed compared to conventional initialization techniques.
FairPlay: A Collaborative Approach to Mitigate Bias in Datasets for Improved AI Fairness
Apr 22, 2025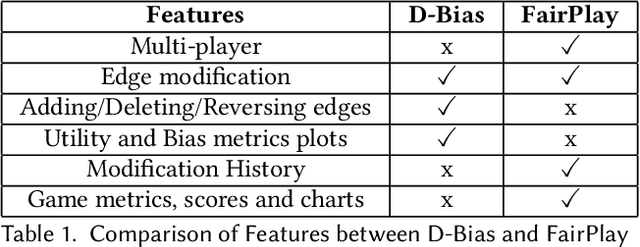
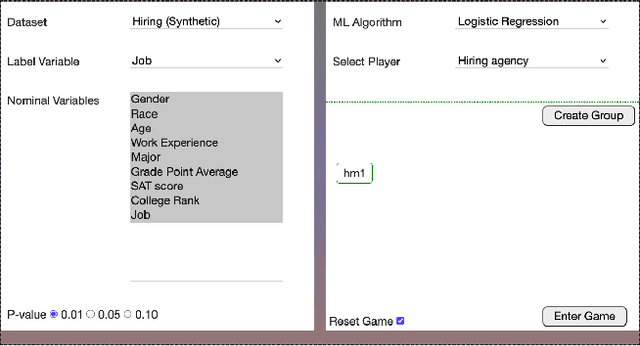
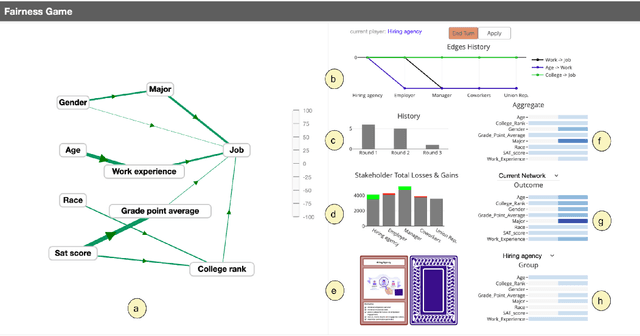
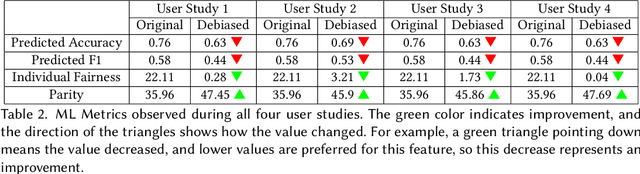
The issue of fairness in decision-making is a critical one, especially given the variety of stakeholder demands for differing and mutually incompatible versions of fairness. Adopting a strategic interaction of perspectives provides an alternative to enforcing a singular standard of fairness. We present a web-based software application, FairPlay, that enables multiple stakeholders to debias datasets collaboratively. With FairPlay, users can negotiate and arrive at a mutually acceptable outcome without a universally agreed-upon theory of fairness. In the absence of such a tool, reaching a consensus would be highly challenging due to the lack of a systematic negotiation process and the inability to modify and observe changes. We have conducted user studies that demonstrate the success of FairPlay, as users could reach a consensus within about five rounds of gameplay, illustrating the application's potential for enhancing fairness in AI systems.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
Into the Void: Mapping the Unseen Gaps in High Dimensional Data
Jan 25, 2025We present a comprehensive pipeline, augmented by a visual analytics system named ``GapMiner'', that is aimed at exploring and exploiting untapped opportunities within the empty areas of high-dimensional datasets. Our approach begins with an initial dataset and then uses a novel Empty Space Search Algorithm (ESA) to identify the center points of these uncharted voids, which are regarded as reservoirs containing potentially valuable novel configurations. Initially, this process is guided by user interactions facilitated by GapMiner. GapMiner visualizes the Empty Space Configurations (ESC) identified by the search within the context of the data, enabling domain experts to explore and adjust ESCs using a linked parallel-coordinate display. These interactions enhance the dataset and contribute to the iterative training of a connected deep neural network (DNN). As the DNN trains, it gradually assumes the task of identifying high-potential ESCs, diminishing the need for direct user involvement. Ultimately, once the DNN achieves adequate accuracy, it autonomously guides the exploration of optimal configurations by predicting performance and refining configurations, using a combination of gradient ascent and improved empty-space searches. Domain users were actively engaged throughout the development of our system. Our findings demonstrate that our methodology consistently produces substantially superior novel configurations compared to conventional randomization-based methods. We illustrate the effectiveness of our method through several case studies addressing various objectives, including parameter optimization, adversarial learning, and reinforcement learning.
Explainable XR: Understanding User Behaviors of XR Environments using LLM-assisted Analytics Framework
Jan 23, 2025



We present Explainable XR, an end-to-end framework for analyzing user behavior in diverse eXtended Reality (XR) environments by leveraging Large Language Models (LLMs) for data interpretation assistance. Existing XR user analytics frameworks face challenges in handling cross-virtuality - AR, VR, MR - transitions, multi-user collaborative application scenarios, and the complexity of multimodal data. Explainable XR addresses these challenges by providing a virtuality-agnostic solution for the collection, analysis, and visualization of immersive sessions. We propose three main components in our framework: (1) A novel user data recording schema, called User Action Descriptor (UAD), that can capture the users' multimodal actions, along with their intents and the contexts; (2) a platform-agnostic XR session recorder, and (3) a visual analytics interface that offers LLM-assisted insights tailored to the analysts' perspectives, facilitating the exploration and analysis of the recorded XR session data. We demonstrate the versatility of Explainable XR by demonstrating five use-case scenarios, in both individual and collaborative XR applications across virtualities. Our technical evaluation and user studies show that Explainable XR provides a highly usable analytics solution for understanding user actions and delivering multifaceted, actionable insights into user behaviors in immersive environments.
A Novel Approach to Eliminating Hallucinations in Large Language Model-Assisted Causal Discovery
Nov 16, 2024



The increasing use of large language models (LLMs) in causal discovery as a substitute for human domain experts highlights the need for optimal model selection. This paper presents the first hallucination survey of popular LLMs for causal discovery. We show that hallucinations exist when using LLMs in causal discovery so the choice of LLM is important. We propose using Retrieval Augmented Generation (RAG) to reduce hallucinations when quality data is available. Additionally, we introduce a novel method employing multiple LLMs with an arbiter in a debate to audit edges in causal graphs, achieving a comparable reduction in hallucinations to RAG.
CausalChat: Interactive Causal Model Development and Refinement Using Large Language Models
Oct 18, 2024



Causal networks are widely used in many fields to model the complex relationships between variables. A recent approach has sought to construct causal networks by leveraging the wisdom of crowds through the collective participation of humans. While this can yield detailed causal networks that model the underlying phenomena quite well, it requires a large number of individuals with domain understanding. We adopt a different approach: leveraging the causal knowledge that large language models, such as OpenAI's GPT-4, have learned by ingesting massive amounts of literature. Within a dedicated visual analytics interface, called CausalChat, users explore single variables or variable pairs recursively to identify causal relations, latent variables, confounders, and mediators, constructing detailed causal networks through conversation. Each probing interaction is translated into a tailored GPT-4 prompt and the response is conveyed through visual representations which are linked to the generated text for explanations. We demonstrate the functionality of CausalChat across diverse data contexts and conduct user studies involving both domain experts and laypersons.
Multi-Conditioned Denoising Diffusion Probabilistic Model (mDDPM) for Medical Image Synthesis
Sep 07, 2024



Medical imaging applications are highly specialized in terms of human anatomy, pathology, and imaging domains. Therefore, annotated training datasets for training deep learning applications in medical imaging not only need to be highly accurate but also diverse and large enough to encompass almost all plausible examples with respect to those specifications. We argue that achieving this goal can be facilitated through a controlled generation framework for synthetic images with annotations, requiring multiple conditional specifications as input to provide control. We employ a Denoising Diffusion Probabilistic Model (DDPM) to train a large-scale generative model in the lung CT domain and expand upon a classifier-free sampling strategy to showcase one such generation framework. We show that our approach can produce annotated lung CT images that can faithfully represent anatomy, convincingly fooling experts into perceiving them as real. Our experiments demonstrate that controlled generative frameworks of this nature can surpass nearly every state-of-the-art image generative model in achieving anatomical consistency in generated medical images when trained on comparable large medical datasets.