 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCUDiff: Latent Capacity Upgrade Diffusion for Faithful Human Body Restoration
Feb 04, 2026Existing methods for restoring degraded human-centric images often struggle with insufficient fidelity, particularly in human body restoration (HBR). Recent diffusion-based restoration methods commonly adapt pre-trained text-to-image diffusion models, where the variational autoencoder (VAE) can significantly bottleneck restoration fidelity. We propose LCUDiff, a stable one-step framework that upgrades a pre-trained latent diffusion model from the 4-channel latent space to the 16-channel latent space. For VAE fine-tuning, channel splitting distillation (CSD) is used to keep the first four channels aligned with pre-trained priors while allocating the additional channels to effectively encode high-frequency details. We further design prior-preserving adaptation (PPA) to smoothly bridge the mismatch between 4-channel diffusion backbones and the higher-dimensional 16-channel latent. In addition, we propose a decoder router (DeR) for per-sample decoder routing using restoration-quality score annotations, which improves visual quality across diverse conditions. Experiments on synthetic and real-world datasets show competitive results with higher fidelity and fewer artifacts under mild degradations, while preserving one-step efficiency. The code and model will be at https://github.com/gobunu/LCUDiff.
Light Up Your Face: A Physically Consistent Dataset and Diffusion Model for Face Fill-Light Enhancement
Feb 04, 2026Face fill-light enhancement (FFE) brightens underexposed faces by adding virtual fill light while keeping the original scene illumination and background unchanged. Most face relighting methods aim to reshape overall lighting, which can suppress the input illumination or modify the entire scene, leading to foreground-background inconsistency and mismatching practical FFE needs. To support scalable learning, we introduce LightYourFace-160K (LYF-160K), a large-scale paired dataset built with a physically consistent renderer that injects a disk-shaped area fill light controlled by six disentangled factors, producing 160K before-and-after pairs. We first pretrain a physics-aware lighting prompt (PALP) that embeds the 6D parameters into conditioning tokens, using an auxiliary planar-light reconstruction objective. Building on a pretrained diffusion backbone, we then train a fill-light diffusion (FiLitDiff), an efficient one-step model conditioned on physically grounded lighting codes, enabling controllable and high-fidelity fill lighting at low computational cost. Experiments on held-out paired sets demonstrate strong perceptual quality and competitive full-reference metrics, while better preserving background illumination. The dataset and model will be at https://github.com/gobunu/Light-Up-Your-Face.
SODiff: Semantic-Oriented Diffusion Model for JPEG Compression Artifacts Removal
Aug 10, 2025JPEG, as a widely used image compression standard, often introduces severe visual artifacts when achieving high compression ratios. Although existing deep learning-based restoration methods have made considerable progress, they often struggle to recover complex texture details, resulting in over-smoothed outputs. To overcome these limitations, we propose SODiff, a novel and efficient semantic-oriented one-step diffusion model for JPEG artifacts removal. Our core idea is that effective restoration hinges on providing semantic-oriented guidance to the pre-trained diffusion model, thereby fully leveraging its powerful generative prior. To this end, SODiff incorporates a semantic-aligned image prompt extractor (SAIPE). SAIPE extracts rich features from low-quality (LQ) images and projects them into an embedding space semantically aligned with that of the text encoder. Simultaneously, it preserves crucial information for faithful reconstruction. Furthermore, we propose a quality factor-aware time predictor that implicitly learns the compression quality factor (QF) of the LQ image and adaptively selects the optimal denoising start timestep for the diffusion process. Extensive experimental results show that our SODiff outperforms recent leading methods in both visual quality and quantitative metrics. Code is available at: https://github.com/frakenation/SODiff
HAODiff: Human-Aware One-Step Diffusion via Dual-Prompt Guidance
May 26, 2025Human-centered images often suffer from severe generic degradation during transmission and are prone to human motion blur (HMB), making restoration challenging. Existing research lacks sufficient focus on these issues, as both problems often coexist in practice. To address this, we design a degradation pipeline that simulates the coexistence of HMB and generic noise, generating synthetic degraded data to train our proposed HAODiff, a human-aware one-step diffusion. Specifically, we propose a triple-branch dual-prompt guidance (DPG), which leverages high-quality images, residual noise (LQ minus HQ), and HMB segmentation masks as training targets. It produces a positive-negative prompt pair for classifier-free guidance (CFG) in a single diffusion step. The resulting adaptive dual prompts let HAODiff exploit CFG more effectively, boosting robustness against diverse degradations. For fair evaluation, we introduce MPII-Test, a benchmark rich in combined noise and HMB cases. Extensive experiments show that our HAODiff surpasses existing state-of-the-art (SOTA) methods in terms of both quantitative metrics and visual quality on synthetic and real-world datasets, including our introduced MPII-Test. Code is available at: https://github.com/gobunu/HAODiff.
HonestFace: Towards Honest Face Restoration with One-Step Diffusion Model
May 24, 2025Face restoration has achieved remarkable advancements through the years of development. However, ensuring that restored facial images exhibit high fidelity, preserve authentic features, and avoid introducing artifacts or biases remains a significant challenge. This highlights the need for models that are more "honest" in their reconstruction from low-quality inputs, accurately reflecting original characteristics. In this work, we propose HonestFace, a novel approach designed to restore faces with a strong emphasis on such honesty, particularly concerning identity consistency and texture realism. To achieve this, HonestFace incorporates several key components. First, we propose an identity embedder to effectively capture and preserve crucial identity features from both the low-quality input and multiple reference faces. Second, a masked face alignment method is presented to enhance fine-grained details and textural authenticity, thereby preventing the generation of patterned or overly synthetic textures and improving overall clarity. Furthermore, we present a new landmark-based evaluation metric. Based on affine transformation principles, this metric improves the accuracy compared to conventional L2 distance calculations for facial feature alignment. Leveraging these contributions within a one-step diffusion model framework, HonestFace delivers exceptional restoration results in terms of facial fidelity and realism. Extensive experiments demonstrate that our approach surpasses existing state-of-the-art methods, achieving superior performance in both visual quality and quantitative assessments. The code and pre-trained models will be made publicly available at https://github.com/jkwang28/HonestFace .
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
Human Body Restoration with One-Step Diffusion Model and A New Benchmark
Feb 03, 2025



Human body restoration, as a specific application of image restoration, is widely applied in practice and plays a vital role across diverse fields. However, thorough research remains difficult, particularly due to the lack of benchmark datasets. In this study, we propose a high-quality dataset automated cropping and filtering (HQ-ACF) pipeline. This pipeline leverages existing object detection datasets and other unlabeled images to automatically crop and filter high-quality human images. Using this pipeline, we constructed a person-based restoration with sophisticated objects and natural activities (\emph{PERSONA}) dataset, which includes training, validation, and test sets. The dataset significantly surpasses other human-related datasets in both quality and content richness. Finally, we propose \emph{OSDHuman}, a novel one-step diffusion model for human body restoration. Specifically, we propose a high-fidelity image embedder (HFIE) as the prompt generator to better guide the model with low-quality human image information, effectively avoiding misleading prompts. Experimental results show that OSDHuman outperforms existing methods in both visual quality and quantitative metrics. The dataset and code will at https://github.com/gobunu/OSDHuman.
OSDFace: One-Step Diffusion Model for Face Restoration
Nov 26, 2024

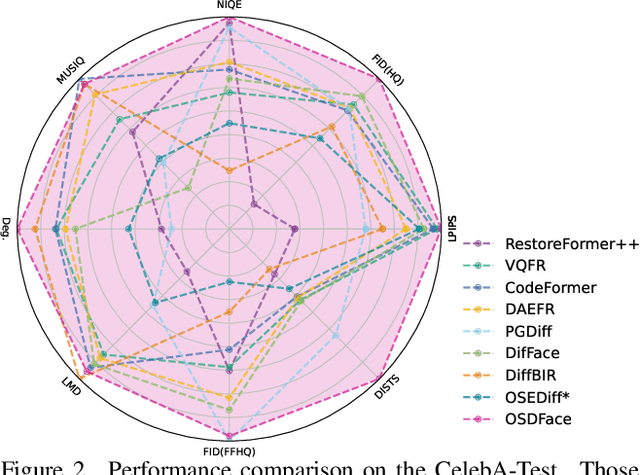

Diffusion models have demonstrated impressive performance in face restoration. Yet, their multi-step inference process remains computationally intensive, limiting their applicability in real-world scenarios. Moreover, existing methods often struggle to generate face images that are harmonious, realistic, and consistent with the subject's identity. In this work, we propose OSDFace, a novel one-step diffusion model for face restoration. Specifically, we propose a visual representation embedder (VRE) to better capture prior information and understand the input face. In VRE, low-quality faces are processed by a visual tokenizer and subsequently embedded with a vector-quantized dictionary to generate visual prompts. Additionally, we incorporate a facial identity loss derived from face recognition to further ensure identity consistency. We further employ a generative adversarial network (GAN) as a guidance model to encourage distribution alignment between the restored face and the ground truth. Experimental results demonstrate that OSDFace surpasses current state-of-the-art (SOTA) methods in both visual quality and quantitative metrics, generating high-fidelity, natural face images with high identity consistency. The code and model will be released at https://github.com/jkwang28/OSDFace.