 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCUDiff: Latent Capacity Upgrade Diffusion for Faithful Human Body Restoration
Feb 04, 2026Existing methods for restoring degraded human-centric images often struggle with insufficient fidelity, particularly in human body restoration (HBR). Recent diffusion-based restoration methods commonly adapt pre-trained text-to-image diffusion models, where the variational autoencoder (VAE) can significantly bottleneck restoration fidelity. We propose LCUDiff, a stable one-step framework that upgrades a pre-trained latent diffusion model from the 4-channel latent space to the 16-channel latent space. For VAE fine-tuning, channel splitting distillation (CSD) is used to keep the first four channels aligned with pre-trained priors while allocating the additional channels to effectively encode high-frequency details. We further design prior-preserving adaptation (PPA) to smoothly bridge the mismatch between 4-channel diffusion backbones and the higher-dimensional 16-channel latent. In addition, we propose a decoder router (DeR) for per-sample decoder routing using restoration-quality score annotations, which improves visual quality across diverse conditions. Experiments on synthetic and real-world datasets show competitive results with higher fidelity and fewer artifacts under mild degradations, while preserving one-step efficiency. The code and model will be at https://github.com/gobunu/LCUDiff.
EveNet: A Foundation Model for Particle Collision Data Analysis
Jan 23, 2026While deep learning is transforming data analysis in high-energy physics, computational challenges limit its potential. We address these challenges in the context of collider physics by introducing EveNet, an event-level foundation model pretrained on 500 million simulated collision events using a hybrid objective of self-supervised learning and physics-informed supervision. By leveraging a shared particle-cloud representation, EveNet outperforms state-of-the-art baselines across diverse tasks, including searches for heavy resonances and exotic Higgs decays, and demonstrates exceptional data efficiency in low-statistics regimes. Crucially, we validate the transferability of the model to experimental data by rediscovering the $Υ$ meson in CMS Open Data and show its capacity for precision physics through the robust extraction of quantum correlation observables stable against systematic uncertainties. These results indicate that EveNet can successfully encode the fundamental physical structure of particle interactions, which offers a unified and resource-efficient framework to accelerate discovery at current and future colliders.
Steel-LLM:From Scratch to Open Source -- A Personal Journey in Building a Chinese-Centric LLM
Feb 10, 2025Steel-LLM is a Chinese-centric language model developed from scratch with the goal of creating a high-quality, open-source model despite limited computational resources. Launched in March 2024, the project aimed to train a 1-billion-parameter model on a large-scale dataset, prioritizing transparency and the sharing of practical insights to assist others in the community. The training process primarily focused on Chinese data, with a small proportion of English data included, addressing gaps in existing open-source LLMs by providing a more detailed and practical account of the model-building journey. Steel-LLM has demonstrated competitive performance on benchmarks such as CEVAL and CMMLU, outperforming early models from larger institutions. This paper provides a comprehensive summary of the project's key contributions, including data collection, model design, training methodologies, and the challenges encountered along the way, offering a valuable resource for researchers and practitioners looking to develop their own LLMs. The model checkpoints and training script are available at https://github.com/zhanshijinwat/Steel-LLM.
BUZZ: Beehive-structured Sparse KV Cache with Segmented Heavy Hitters for Efficient LLM Inference
Oct 30, 2024



Large language models (LLMs) are essential in natural language processing but often struggle with inference speed and computational efficiency, limiting real-time deployment. The key-value (KV) cache mechanism reduces computational overhead in transformer models, but challenges in maintaining contextual understanding remain. In this paper, we propose BUZZ, a novel KV caching algorithm that leverages structured contextual information to minimize cache memory usage while enhancing inference speed. BUZZ employs a beehive-structured sparse cache, incorporating a sliding window to capture recent information and dynamically segmenting historical tokens into chunks to prioritize important tokens in local neighborhoods. We evaluate BUZZ on four real-world datasets: CNN/Daily Mail, XSUM, Wikitext, and 10-QA. Our results demonstrate that BUZZ (1) reduces cache memory usage by $\textbf{2.5}\times$ in LLM inference while maintaining over 99% accuracy in long-text summarization, and (2) surpasses state-of-the-art performance in multi-document question answering by $\textbf{7.69%}$ under the same memory limit, where full cache methods encounter out-of-memory issues. Additionally, BUZZ achieves significant inference speedup with a $\log{n}$ time complexity. The code is available at https://github.com/JunqiZhao888/buzz-llm.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024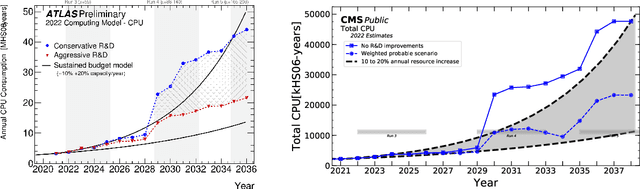
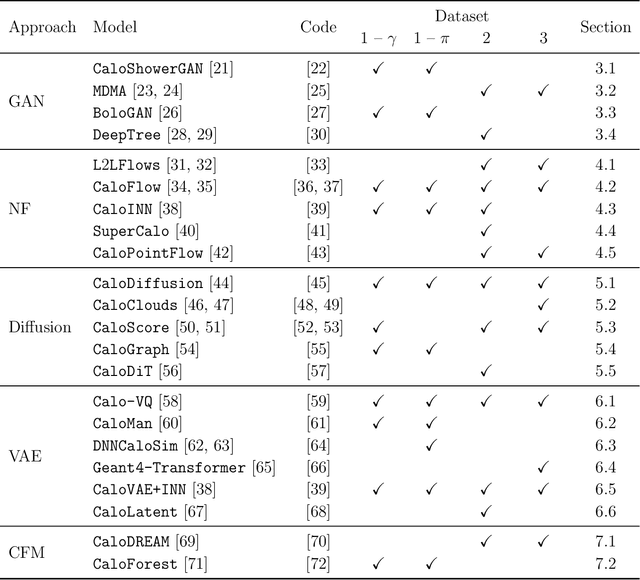
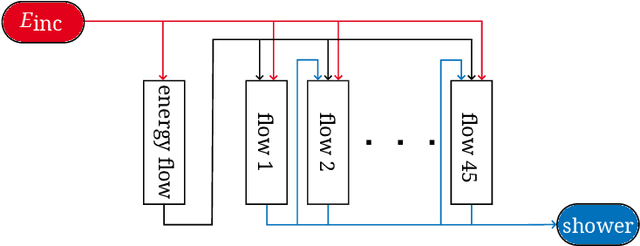
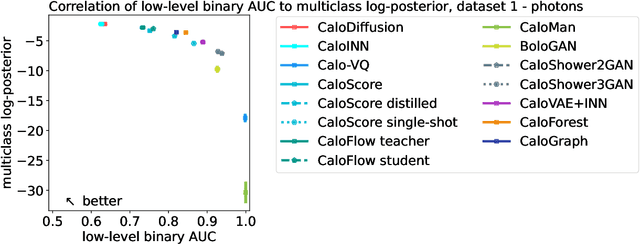
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Calo-VQ: Vector-Quantized Two-Stage Generative Model in Calorimeter Simulation
May 10, 2024We introduce a novel machine learning method developed for the fast simulation of calorimeter detector response, adapting vector-quantized variational autoencoder (VQ-VAE). Our model adopts a two-stage generation strategy: initially compressing geometry-aware calorimeter data into a discrete latent space, followed by the application of a sequence model to learn and generate the latent tokens. Extensive experimentation on the Calo-challenge dataset underscores the efficiency of our approach, showcasing a remarkable improvement in the generation speed compared with conventional method by a factor of 2000. Remarkably, our model achieves the generation of calorimeter showers within milliseconds. Furthermore, comprehensive quantitative evaluations across various metrics are performed to validate physics performance of generation.
Efficient Text-driven Motion Generation via Latent Consistency Training
May 05, 2024Motion diffusion models have recently proven successful for text-driven human motion generation. Despite their excellent generation performance, they are challenging to infer in real time due to the multi-step sampling mechanism that involves tens or hundreds of repeat function evaluation iterations. To this end, we investigate a motion latent consistency Training (MLCT) for motion generation to alleviate the computation and time consumption during iteration inference. It applies diffusion pipelines to low-dimensional motion latent spaces to mitigate the computational burden of each function evaluation. Explaining the diffusion process with probabilistic flow ordinary differential equation (PF-ODE) theory, the MLCT allows extremely few steps infer between the prior distribution to the motion latent representation distribution via maintaining consistency of the outputs over the trajectory of PF-ODE. Especially, we introduce a quantization constraint to optimize motion latent representations that are bounded, regular, and well-reconstructed compared to traditional variational constraints. Furthermore, we propose a conditional PF-ODE trajectory simulation method, which improves the conditional generation performance with minimal additional training costs. Extensive experiments on two human motion generation benchmarks show that the proposed model achieves state-of-the-art performance with less than 10\% time cost.
Few-Shot Scenario Testing for Autonomous Vehicles Based on Neighborhood Coverage and Similarity
Feb 02, 2024Testing and evaluating the safety performance of autonomous vehicles (AVs) is essential before the large-scale deployment. Practically, the acceptable cost of testing specific AV model can be restricted within an extremely small limit because of testing cost or time. With existing testing methods, the limitations imposed by strictly restricted testing numbers often result in significant uncertainties or challenges in quantifying testing results. In this paper, we formulate this problem for the first time the "few-shot testing" (FST) problem and propose a systematic FST framework to address this challenge. To alleviate the considerable uncertainty inherent in a small testing scenario set and optimize scenario utilization, we frame the FST problem as an optimization problem and search for a small scenario set based on neighborhood coverage and similarity. By leveraging the prior information on surrogate models (SMs), we dynamically adjust the testing scenario set and the contribution of each scenario to the testing result under the guidance of better generalization ability on AVs. With certain hypotheses on SMs, a theoretical upper bound of testing error is established to verify the sufficiency of testing accuracy within given limited number of tests. The experiments of the cut-in scenario using FST method demonstrate a notable reduction in testing error and variance compared to conventional testing methods, especially for situations with a strict limitation on the number of scenarios.
Polynomial Width is Sufficient for Set Representation with High-dimensional Features
Jul 19, 2023Set representation has become ubiquitous in deep learning for modeling the inductive bias of neural networks that are insensitive to the input order. DeepSets is the most widely used neural network architecture for set representation. It involves embedding each set element into a latent space with dimension $L$, followed by a sum pooling to obtain a whole-set embedding, and finally mapping the whole-set embedding to the output. In this work, we investigate the impact of the dimension $L$ on the expressive power of DeepSets. Previous analyses either oversimplified high-dimensional features to be one-dimensional features or were limited to analytic activations, thereby diverging from practical use or resulting in $L$ that grows exponentially with the set size $N$ and feature dimension $D$. To investigate the minimal value of $L$ that achieves sufficient expressive power, we present two set-element embedding layers: (a) linear + power activation (LP) and (b) linear + exponential activations (LE). We demonstrate that $L$ being poly$(N, D)$ is sufficient for set representation using both embedding layers. We also provide a lower bound of $L$ for the LP embedding layer. Furthermore, we extend our results to permutation-equivariant set functions and the complex field.
PASTS: Progress-Aware Spatio-Temporal Transformer Speaker For Vision-and-Language Navigation
May 19, 2023



Vision-and-language navigation (VLN) is a crucial but challenging cross-modal navigation task. One powerful technique to enhance the generalization performance in VLN is the use of an independent speaker model to provide pseudo instructions for data augmentation. However, current speaker models based on Long-Short Term Memory (LSTM) lack the ability to attend to features relevant at different locations and time steps. To address this, we propose a novel progress-aware spatio-temporal transformer speaker (PASTS) model that uses the transformer as the core of the network. PASTS uses a spatio-temporal encoder to fuse panoramic representations and encode intermediate connections through steps. Besides, to avoid the misalignment problem that could result in incorrect supervision, a speaker progress monitor (SPM) is proposed to enable the model to estimate the progress of instruction generation and facilitate more fine-grained caption results. Additionally, a multifeature dropout (MFD) strategy is introduced to alleviate overfitting. The proposed PASTS is flexible to be combined with existing VLN models. The experimental results demonstrate that PASTS outperforms all existing speaker models and successfully improves the performance of previous VLN models, achieving state-of-the-art performance on the standard Room-to-Room (R2R) dataset.