 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASH: Collaborative Large-Small Hierarchical Framework for Continuous Vision-and-Language Navigation
Dec 11, 2025Vision-and-Language Navigation (VLN) requires robots to follow natural language instructions and navigate complex environments without prior maps. While recent vision-language large models demonstrate strong reasoning abilities, they often underperform task-specific panoramic small models in VLN tasks. To address this, we propose CLASH (Collaborative Large-Small Hierarchy), a VLN-CE framework that integrates a reactive small-model planner (RSMP) with a reflective large-model reasoner (RLMR). RSMP adopts a causal-learning-based dual-branch architecture to enhance generalization, while RLMR leverages panoramic visual prompting with chain-of-thought reasoning to support interpretable spatial understanding and navigation. We further introduce an uncertainty-aware collaboration mechanism (UCM) that adaptively fuses decisions from both models. For obstacle avoidance, in simulation, we replace the rule-based controller with a fully learnable point-goal policy, and in real-world deployment, we design a LiDAR-based clustering module for generating navigable waypoints and pair it with an online SLAM-based local controller. CLASH achieves state-of-the-art (SoTA) results (ranking 1-st) on the VLN-CE leaderboard, significantly improving SR and SPL on the test-unseen set over the previous SoTA methods. Real-world experiments demonstrate CLASH's strong robustness, validating its effectiveness in both simulation and deployment scenarios.
MAGIC: Meta-Ability Guided Interactive Chain-of-Distillation for Effective-and-Efficient Vision-and-Language Navigation
Jun 25, 2024Despite the remarkable developments of recent large models in Embodied Artificial Intelligence (E-AI), their integration into robotics is hampered by their excessive parameter sizes and computational demands. Towards the Vision-and-Language Navigation (VLN) task, a core task in E-AI, this paper reveals the great potential of using knowledge distillation for obtaining lightweight student models by proposing a Meta-Ability Guided Interactive Chain-of-distillation (MAGIC) method. Specifically, a Meta-Ability Knowledge Distillation (MAKD) framework is proposed for decoupling and refining the necessary meta-abilities of VLN agents. A Meta-Knowledge Randomization Weighting (MKRW) and a Meta-Knowledge Transferable Determination (MKTD) module are incorporated to dynamically adjust aggregation weights at the meta-ability and sample levels, respectively. Move beyond the traditional one-step unidirectional distillation, an Interactive Chain-of-Distillation (ICoD) learning strategy is proposed to allow students to give feedback to teachers, forming a new multi-step teacher-student co-evolution pipeline. Remarkably, on the R2R test unseen public leaderboard, our smallest model, MAGIC-S, with only 5% (11M) of the teacher's size, outperforms all previous methods under the same training data. Additionally, our largest model, MAGIC-L, surpasses the previous state-of-the-art by 5.84% in SPL and 3.18% in SR. Furthermore, a new dataset was collected and annotated from our living environments, where MAGIC-S demonstrated superior performance and real-time efficiency. Our code is publicly available on https://github.com/CrystalSixone/VLN-MAGIC.
Vision-and-Language Navigation via Causal Learning
Apr 16, 2024In the pursuit of robust and generalizable environment perception and language understanding, the ubiquitous challenge of dataset bias continues to plague vision-and-language navigation (VLN) agents, hindering their performance in unseen environments. This paper introduces the generalized cross-modal causal transformer (GOAT), a pioneering solution rooted in the paradigm of causal inference. By delving into both observable and unobservable confounders within vision, language, and history, we propose the back-door and front-door adjustment causal learning (BACL and FACL) modules to promote unbiased learning by comprehensively mitigating potential spurious correlations. Additionally, to capture global confounder features, we propose a cross-modal feature pooling (CFP) module supervised by contrastive learning, which is also shown to be effective in improving cross-modal representations during pre-training. Extensive experiments across multiple VLN datasets (R2R, REVERIE, RxR, and SOON) underscore the superiority of our proposed method over previous state-of-the-art approaches. Code is available at https://github.com/CrystalSixone/VLN-GOAT.
Causality-based Cross-Modal Representation Learning for Vision-and-Language Navigation
Mar 06, 2024Vision-and-Language Navigation (VLN) has gained significant research interest in recent years due to its potential applications in real-world scenarios. However, existing VLN methods struggle with the issue of spurious associations, resulting in poor generalization with a significant performance gap between seen and unseen environments. In this paper, we tackle this challenge by proposing a unified framework CausalVLN based on the causal learning paradigm to train a robust navigator capable of learning unbiased feature representations. Specifically, we establish reasonable assumptions about confounders for vision and language in VLN using the structured causal model (SCM). Building upon this, we propose an iterative backdoor-based representation learning (IBRL) method that allows for the adaptive and effective intervention on confounders. Furthermore, we introduce the visual and linguistic backdoor causal encoders to enable unbiased feature expression for multi-modalities during training and validation, enhancing the agent's capability to generalize across different environments. Experiments on three VLN datasets (R2R, RxR, and REVERIE) showcase the superiority of our proposed method over previous state-of-the-art approaches. Moreover, detailed visualization analysis demonstrates the effectiveness of CausalVLN in significantly narrowing down the performance gap between seen and unseen environments, underscoring its strong generalization capability.
PASTS: Progress-Aware Spatio-Temporal Transformer Speaker For Vision-and-Language Navigation
May 19, 2023



Vision-and-language navigation (VLN) is a crucial but challenging cross-modal navigation task. One powerful technique to enhance the generalization performance in VLN is the use of an independent speaker model to provide pseudo instructions for data augmentation. However, current speaker models based on Long-Short Term Memory (LSTM) lack the ability to attend to features relevant at different locations and time steps. To address this, we propose a novel progress-aware spatio-temporal transformer speaker (PASTS) model that uses the transformer as the core of the network. PASTS uses a spatio-temporal encoder to fuse panoramic representations and encode intermediate connections through steps. Besides, to avoid the misalignment problem that could result in incorrect supervision, a speaker progress monitor (SPM) is proposed to enable the model to estimate the progress of instruction generation and facilitate more fine-grained caption results. Additionally, a multifeature dropout (MFD) strategy is introduced to alleviate overfitting. The proposed PASTS is flexible to be combined with existing VLN models. The experimental results demonstrate that PASTS outperforms all existing speaker models and successfully improves the performance of previous VLN models, achieving state-of-the-art performance on the standard Room-to-Room (R2R) dataset.
A Dual Semantic-Aware Recurrent Global-Adaptive Network For Vision-and-Language Navigation
May 05, 2023



Vision-and-Language Navigation (VLN) is a realistic but challenging task that requires an agent to locate the target region using verbal and visual cues. While significant advancements have been achieved recently, there are still two broad limitations: (1) The explicit information mining for significant guiding semantics concealed in both vision and language is still under-explored; (2) The previously structured map method provides the average historical appearance of visited nodes, while it ignores distinctive contributions of various images and potent information retention in the reasoning process. This work proposes a dual semantic-aware recurrent global-adaptive network (DSRG) to address the above problems. First, DSRG proposes an instruction-guidance linguistic module (IGL) and an appearance-semantics visual module (ASV) for boosting vision and language semantic learning respectively. For the memory mechanism, a global adaptive aggregation module (GAA) is devised for explicit panoramic observation fusion, and a recurrent memory fusion module (RMF) is introduced to supply implicit temporal hidden states. Extensive experimental results on the R2R and REVERIE datasets demonstrate that our method achieves better performance than existing methods.
MLANet: Multi-Level Attention Network with Sub-instruction for Continuous Vision-and-Language Navigation
Mar 02, 2023Vision-and-Language Navigation (VLN) aims to develop intelligent agents to navigate in unseen environments only through language and vision supervision. In the recently proposed continuous settings (continuous VLN), the agent must act in a free 3D space and faces tougher challenges like real-time execution, complex instruction understanding, and long action sequence prediction. For a better performance in continuous VLN, we design a multi-level instruction understanding procedure and propose a novel model, Multi-Level Attention Network (MLANet). The first step of MLANet is to generate sub-instructions efficiently. We design a Fast Sub-instruction Algorithm (FSA) to segment the raw instruction into sub-instructions and generate a new sub-instruction dataset named ``FSASub". FSA is annotation-free and faster than the current method by 70 times, thus fitting the real-time requirement in continuous VLN. To solve the complex instruction understanding problem, MLANet needs a global perception of the instruction and observations. We propose a Multi-Level Attention (MLA) module to fuse vision, low-level semantics, and high-level semantics, which produce features containing a dynamic and global comprehension of the task. MLA also mitigates the adverse effects of noise words, thus ensuring a robust understanding of the instruction. To correctly predict actions in long trajectories, MLANet needs to focus on what sub-instruction is being executed every step. We propose a Peak Attention Loss (PAL) to improve the flexible and adaptive selection of the current sub-instruction. PAL benefits the navigation agent by concentrating its attention on the local information, thus helping the agent predict the most appropriate actions. We train and test MLANet in the standard benchmark. Experiment results show MLANet outperforms baselines by a significant margin.
Multiple Thinking Achieving Meta-Ability Decoupling for Object Navigation
Feb 03, 2023We propose a meta-ability decoupling (MAD) paradigm, which brings together various object navigation methods in an architecture system, allowing them to mutually enhance each other and evolve together. Based on the MAD paradigm, we design a multiple thinking (MT) model that leverages distinct thinking to abstract various meta-abilities. Our method decouples meta-abilities from three aspects: input, encoding, and reward while employing the multiple thinking collaboration (MTC) module to promote mutual cooperation between thinking. MAD introduces a novel qualitative and quantitative interpretability system for object navigation. Through extensive experiments on AI2-Thor and RoboTHOR, we demonstrate that our method outperforms state-of-the-art (SOTA) methods on both typical and zero-shot object navigation tasks.
Search for or Navigate to? Dual Adaptive Thinking for Object Navigation
Aug 13, 2022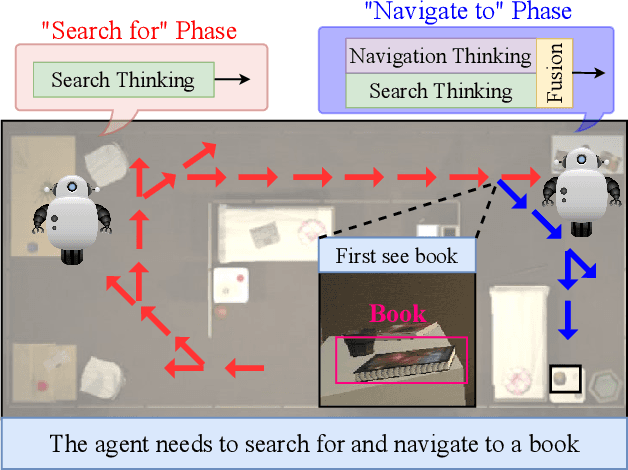
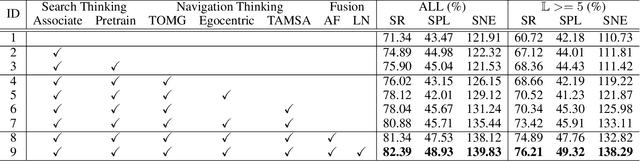
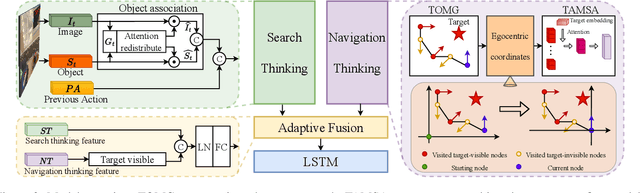
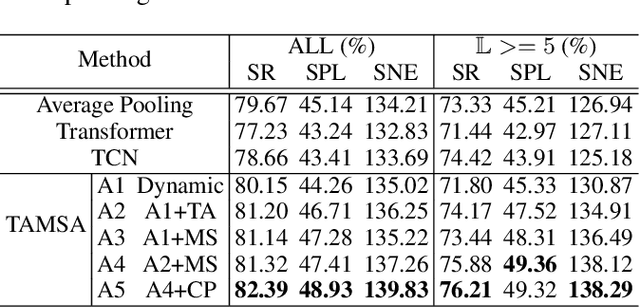
"Search for" or "Navigate to"? When finding an object, the two choices always come up in our subconscious mind. Before seeing the target, we search for the target based on experience. After seeing the target, we remember the target location and navigate to. However, recently methods in object navigation field almost only consider using object association to enhance "search for" phase while neglect the importance of "navigate to" phase. Therefore, this paper proposes the dual adaptive thinking (DAT) method to flexibly adjust the different thinking strategies at different navigation stages. Dual thinking includes search thinking with the object association ability and navigation thinking with the target location ability. To make the navigation thinking more effective, we design the target-oriented memory graph (TOMG) to store historical target information and the target-aware multi-scale aggregator (TAMSA) to encode the relative target position. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 10.8%, 21.5% and 15.7% increase in success rate (SR), success weighted by path length (SPL) and success weighted by navigation efficiency (SNE), respectively.
Unbiased Directed Object Attention Graph for Object Navigation
Apr 09, 2022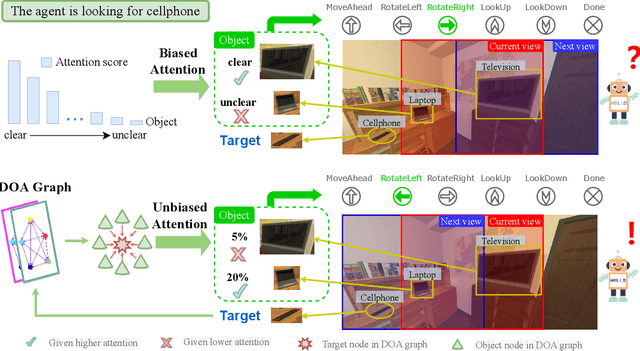

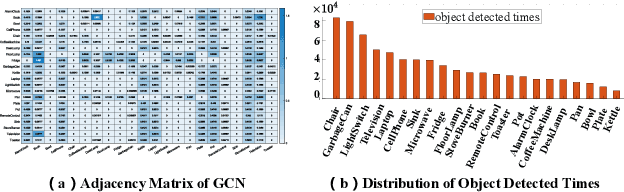

Object navigation tasks require agents to locate specific objects in unknown environments based on visual information. Previously, graph convolutions were used to implicitly explore the relationships between objects. However, due to differences in visibility among objects, it is easy to generate biases in object attention. Thus, in this paper, we propose a directed object attention (DOA) graph to guide the agent in explicitly learning the attention relationships between objects, thereby reducing the object attention bias. In particular, we use the DOA graph to perform unbiased adaptive object attention (UAOA) on the object features and unbiased adaptive image attention (UAIA) on the raw images, respectively. To distinguish features in different branches, a concise adaptive branch energy distribution (ABED) method is proposed. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 7.4%, 8.1% and 17.6% increase in success rate (SR), success weighted by path length (SPL) and success weighted by action efficiency (SAE), respectively.