 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleanPose: Category-Level Object Pose Estimation via Causal Learning and Knowledge Distillation
Feb 03, 2025



Category-level object pose estimation aims to recover the rotation, translation and size of unseen instances within predefined categories. In this task, deep neural network-based methods have demonstrated remarkable performance. However, previous studies show they suffer from spurious correlations raised by "unclean" confounders in models, hindering their performance on novel instances with significant variations. To address this issue, we propose CleanPose, a novel approach integrating causal learning and knowledge distillation to enhance category-level pose estimation. To mitigate the negative effect of unobserved confounders, we develop a causal inference module based on front-door adjustment, which promotes unbiased estimation by reducing potential spurious correlations. Additionally, to further improve generalization ability, we devise a residual-based knowledge distillation method that has proven effective in providing comprehensive category information guidance. Extensive experiments across multiple benchmarks (REAL275, CAMERA25 and HouseCat6D) hightlight the superiority of proposed CleanPose over state-of-the-art methods. Code will be released.
MAGIC: Meta-Ability Guided Interactive Chain-of-Distillation for Effective-and-Efficient Vision-and-Language Navigation
Jun 25, 2024Despite the remarkable developments of recent large models in Embodied Artificial Intelligence (E-AI), their integration into robotics is hampered by their excessive parameter sizes and computational demands. Towards the Vision-and-Language Navigation (VLN) task, a core task in E-AI, this paper reveals the great potential of using knowledge distillation for obtaining lightweight student models by proposing a Meta-Ability Guided Interactive Chain-of-distillation (MAGIC) method. Specifically, a Meta-Ability Knowledge Distillation (MAKD) framework is proposed for decoupling and refining the necessary meta-abilities of VLN agents. A Meta-Knowledge Randomization Weighting (MKRW) and a Meta-Knowledge Transferable Determination (MKTD) module are incorporated to dynamically adjust aggregation weights at the meta-ability and sample levels, respectively. Move beyond the traditional one-step unidirectional distillation, an Interactive Chain-of-Distillation (ICoD) learning strategy is proposed to allow students to give feedback to teachers, forming a new multi-step teacher-student co-evolution pipeline. Remarkably, on the R2R test unseen public leaderboard, our smallest model, MAGIC-S, with only 5% (11M) of the teacher's size, outperforms all previous methods under the same training data. Additionally, our largest model, MAGIC-L, surpasses the previous state-of-the-art by 5.84% in SPL and 3.18% in SR. Furthermore, a new dataset was collected and annotated from our living environments, where MAGIC-S demonstrated superior performance and real-time efficiency. Our code is publicly available on https://github.com/CrystalSixone/VLN-MAGIC.
Three-Filters-to-Normal+: Revisiting Discontinuity Discrimination in Depth-to-Normal Translation
Dec 13, 2023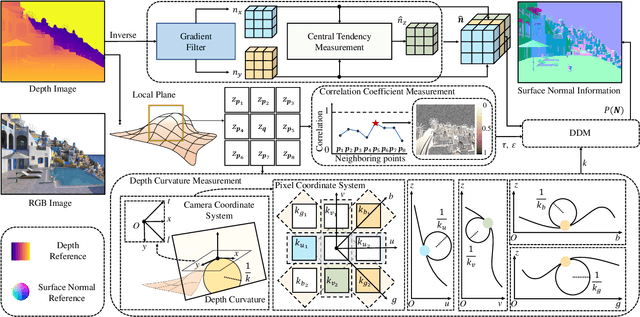
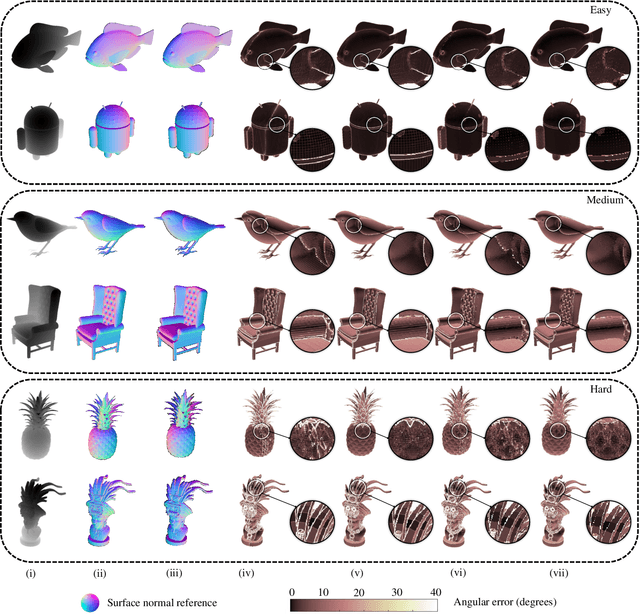
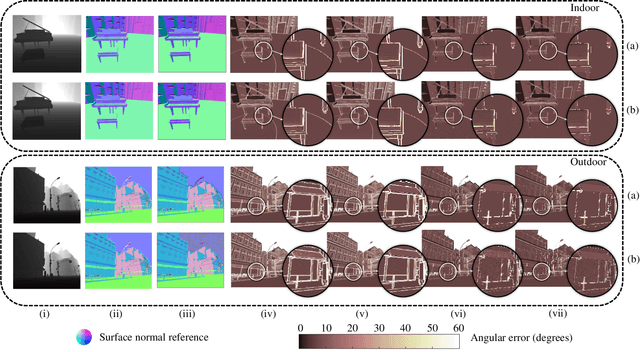
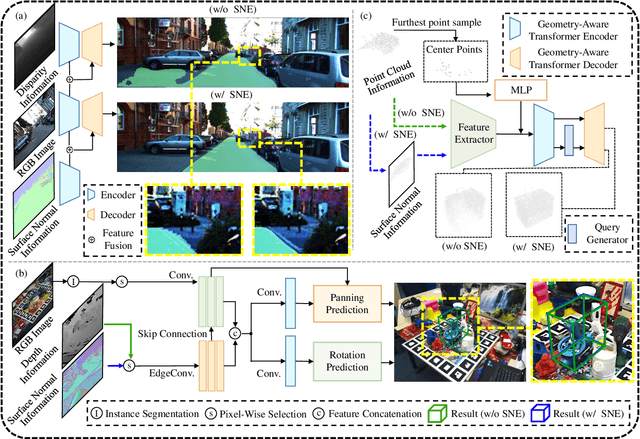
This article introduces three-filters-to-normal+ (3F2N+), an extension of our previous work three-filters-to-normal (3F2N), with a specific focus on incorporating discontinuity discrimination capability into surface normal estimators (SNEs). 3F2N+ achieves this capability by utilizing a novel discontinuity discrimination module (DDM), which combines depth curvature minimization and correlation coefficient maximization through conditional random fields (CRFs). To evaluate the robustness of SNEs on noisy data, we create a large-scale synthetic surface normal (SSN) dataset containing 20 scenarios (ten indoor scenarios and ten outdoor scenarios with and without random Gaussian noise added to depth images). Extensive experiments demonstrate that 3F2N+ achieves greater performance than all other geometry-based surface normal estimators, with average angular errors of 7.85$^\circ$, 8.95$^\circ$, 9.25$^\circ$, and 11.98$^\circ$ on the clean-indoor, clean-outdoor, noisy-indoor, and noisy-outdoor datasets, respectively. We conduct three additional experiments to demonstrate the effectiveness of incorporating our proposed 3F2N+ into downstream robot perception tasks, including freespace detection, 6D object pose estimation, and point cloud completion. Our source code and datasets are publicly available at https://mias.group/3F2Nplus.