 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulVul: Retrieval-augmented Multi-Agent Code Vulnerability Detection via Cross-Model Prompt Evolution
Jan 26, 2026Large Language Models (LLMs) struggle to automate real-world vulnerability detection due to two key limitations: the heterogeneity of vulnerability patterns undermines the effectiveness of a single unified model, and manual prompt engineering for massive weakness categories is unscalable. To address these challenges, we propose \textbf{MulVul}, a retrieval-augmented multi-agent framework designed for precise and broad-coverage vulnerability detection. MulVul adopts a coarse-to-fine strategy: a \emph{Router} agent first predicts the top-$k$ coarse categories and then forwards the input to specialized \emph{Detector} agents, which identify the exact vulnerability types. Both agents are equipped with retrieval tools to actively source evidence from vulnerability knowledge bases to mitigate hallucinations. Crucially, to automate the generation of specialized prompts, we design \emph{Cross-Model Prompt Evolution}, a prompt optimization mechanism where a generator LLM iteratively refines candidate prompts while a distinct executor LLM validates their effectiveness. This decoupling mitigates the self-correction bias inherent in single-model optimization. Evaluated on 130 CWE types, MulVul achieves 34.79\% Macro-F1, outperforming the best baseline by 41.5\%. Ablation studies validate cross-model prompt evolution, which boosts performance by 51.6\% over manual prompts by effectively handling diverse vulnerability patterns.
3D Software Synthesis Guided by Constraint-Expressive Intermediate Representation
Jul 24, 2025Graphical user interface (UI) software has undergone a fundamental transformation from traditional two-dimensional (2D) desktop/web/mobile interfaces to spatial three-dimensional (3D) environments. While existing work has made remarkable success in automated 2D software generation, such as HTML/CSS and mobile app interface code synthesis, the generation of 3D software still remains under-explored. Current methods for 3D software generation usually generate the 3D environments as a whole and cannot modify or control specific elements in the software. Furthermore, these methods struggle to handle the complex spatial and semantic constraints inherent in the real world. To address the challenges, we present Scenethesis, a novel requirement-sensitive 3D software synthesis approach that maintains formal traceability between user specifications and generated 3D software. Scenethesis is built upon ScenethesisLang, a domain-specific language that serves as a granular constraint-aware intermediate representation (IR) to bridge natural language requirements and executable 3D software. It serves both as a comprehensive scene description language enabling fine-grained modification of 3D software elements and as a formal constraint-expressive specification language capable of expressing complex spatial constraints. By decomposing 3D software synthesis into stages operating on ScenethesisLang, Scenethesis enables independent verification, targeted modification, and systematic constraint satisfaction. Our evaluation demonstrates that Scenethesis accurately captures over 80% of user requirements and satisfies more than 90% of hard constraints while handling over 100 constraints simultaneously. Furthermore, Scenethesis achieves a 42.8% improvement in BLIP-2 visual evaluation scores compared to the state-of-the-art method.
CleanPose: Category-Level Object Pose Estimation via Causal Learning and Knowledge Distillation
Feb 03, 2025



Category-level object pose estimation aims to recover the rotation, translation and size of unseen instances within predefined categories. In this task, deep neural network-based methods have demonstrated remarkable performance. However, previous studies show they suffer from spurious correlations raised by "unclean" confounders in models, hindering their performance on novel instances with significant variations. To address this issue, we propose CleanPose, a novel approach integrating causal learning and knowledge distillation to enhance category-level pose estimation. To mitigate the negative effect of unobserved confounders, we develop a causal inference module based on front-door adjustment, which promotes unbiased estimation by reducing potential spurious correlations. Additionally, to further improve generalization ability, we devise a residual-based knowledge distillation method that has proven effective in providing comprehensive category information guidance. Extensive experiments across multiple benchmarks (REAL275, CAMERA25 and HouseCat6D) hightlight the superiority of proposed CleanPose over state-of-the-art methods. Code will be released.
Distillation Learning Guided by Image Reconstruction for One-Shot Medical Image Segmentation
Aug 07, 2024



Traditional one-shot medical image segmentation (MIS) methods use registration networks to propagate labels from a reference atlas or rely on comprehensive sampling strategies to generate synthetic labeled data for training. However, these methods often struggle with registration errors and low-quality synthetic images, leading to poor performance and generalization. To overcome this, we introduce a novel one-shot MIS framework based on knowledge distillation, which allows the network to directly 'see' real images through a distillation process guided by image reconstruction. It focuses on anatomical structures in a single labeled image and a few unlabeled ones. A registration-based data augmentation network creates realistic, labeled samples, while a feature distillation module helps the student network learn segmentation from these samples, guided by the teacher network. During inference, the streamlined student network accurately segments new images. Evaluations on three public datasets (OASIS for T1 brain MRI, BCV for abdomen CT, and VerSe for vertebrae CT) show superior segmentation performance and generalization across different medical image datasets and modalities compared to leading methods. Our code is available at https://github.com/NoviceFodder/OS-MedSeg.
SAM-LAD: Segment Anything Model Meets Zero-Shot Logic Anomaly Detection
Jun 02, 2024Visual anomaly detection is vital in real-world applications, such as industrial defect detection and medical diagnosis. However, most existing methods focus on local structural anomalies and fail to detect higher-level functional anomalies under logical conditions. Although recent studies have explored logical anomaly detection, they can only address simple anomalies like missing or addition and show poor generalizability due to being heavily data-driven. To fill this gap, we propose SAM-LAD, a zero-shot, plug-and-play framework for logical anomaly detection in any scene. First, we obtain a query image's feature map using a pre-trained backbone. Simultaneously, we retrieve the reference images and their corresponding feature maps via the nearest neighbor search of the query image. Then, we introduce the Segment Anything Model (SAM) to obtain object masks of the query and reference images. Each object mask is multiplied with the entire image's feature map to obtain object feature maps. Next, an Object Matching Model (OMM) is proposed to match objects in the query and reference images. To facilitate object matching, we further propose a Dynamic Channel Graph Attention (DCGA) module, treating each object as a keypoint and converting its feature maps into feature vectors. Finally, based on the object matching relations, an Anomaly Measurement Model (AMM) is proposed to detect objects with logical anomalies. Structural anomalies in the objects can also be detected. We validate our proposed SAM-LAD using various benchmarks, including industrial datasets (MVTec Loco AD, MVTec AD), and the logical dataset (DigitAnatomy). Extensive experimental results demonstrate that SAM-LAD outperforms existing SoTA methods, particularly in detecting logical anomalies.
Enhancing LLM-Based Coding Tools through Native Integration of IDE-Derived Static Context
Feb 06, 2024


Large Language Models (LLMs) have achieved remarkable success in code completion, as evidenced by their essential roles in developing code assistant services such as Copilot. Being trained on in-file contexts, current LLMs are quite effective in completing code for single source files. However, it is challenging for them to conduct repository-level code completion for large software projects that require cross-file information. Existing research on LLM-based repository-level code completion identifies and integrates cross-file contexts, but it suffers from low accuracy and limited context length of LLMs. In this paper, we argue that Integrated Development Environments (IDEs) can provide direct, accurate and real-time cross-file information for repository-level code completion. We propose IDECoder, a practical framework that leverages IDE native static contexts for cross-context construction and diagnosis results for self-refinement. IDECoder utilizes the rich cross-context information available in IDEs to enhance the capabilities of LLMs of repository-level code completion. We conducted preliminary experiments to validate the performance of IDECoder and observed that this synergy represents a promising trend for future exploration.
ChatGraph: Chat with Your Graphs
Jan 23, 2024



Graph analysis is fundamental in real-world applications. Traditional approaches rely on SPARQL-like languages or clicking-and-dragging interfaces to interact with graph data. However, these methods either require users to possess high programming skills or support only a limited range of graph analysis functionalities. To address the limitations, we propose a large language model (LLM)-based framework called ChatGraph. With ChatGraph, users can interact with graphs through natural language, making it easier to use and more flexible than traditional approaches. The core of ChatGraph lies in generating chains of graph analysis APIs based on the understanding of the texts and graphs inputted in the user prompts. To achieve this, ChatGraph consists of three main modules: an API retrieval module that searches for relevant APIs, a graph-aware LLM module that enables the LLM to comprehend graphs, and an API chain-oriented finetuning module that guides the LLM in generating API chains.
VLUCI: Variational Learning of Unobserved Confounders for Counterfactual Inference
Aug 02, 2023



Causal inference plays a vital role in diverse domains like epidemiology, healthcare, and economics. De-confounding and counterfactual prediction in observational data has emerged as a prominent concern in causal inference research. While existing models tackle observed confounders, the presence of unobserved confounders remains a significant challenge, distorting causal inference and impacting counterfactual outcome accuracy. To address this, we propose a novel variational learning model of unobserved confounders for counterfactual inference (VLUCI), which generates the posterior distribution of unobserved confounders. VLUCI relaxes the unconfoundedness assumption often overlooked by most causal inference methods. By disentangling observed and unobserved confounders, VLUCI constructs a doubly variational inference model to approximate the distribution of unobserved confounders, which are used for inferring more accurate counterfactual outcomes. Extensive experiments on synthetic and semi-synthetic datasets demonstrate VLUCI's superior performance in inferring unobserved confounders. It is compatible with state-of-the-art counterfactual inference models, significantly improving inference accuracy at both group and individual levels. Additionally, VLUCI provides confidence intervals for counterfactual outcomes, aiding decision-making in risk-sensitive domains. We further clarify the considerations when applying VLUCI to cases where unobserved confounders don't strictly conform to our model assumptions using the public IHDP dataset as an example, highlighting the practical advantages of VLUCI.
No More Fine-Tuning? An Experimental Evaluation of Prompt Tuning in Code Intelligence
Jul 24, 2022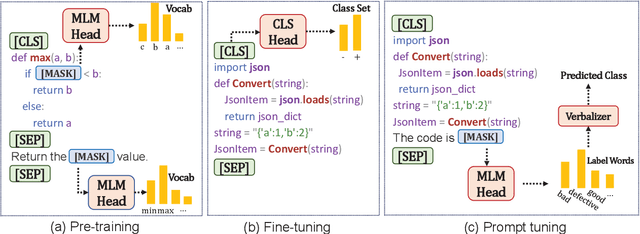
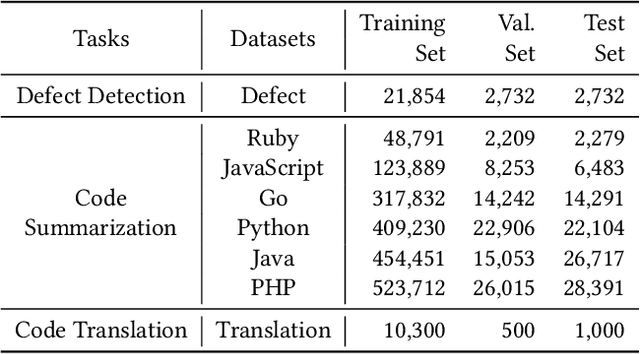
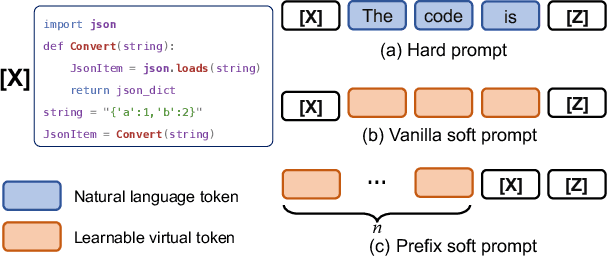
Pre-trained models have been shown effective in many code intelligence tasks. These models are pre-trained on large-scale unlabeled corpus and then fine-tuned in downstream tasks. However, as the inputs to pre-training and downstream tasks are in different forms, it is hard to fully explore the knowledge of pre-trained models. Besides, the performance of fine-tuning strongly relies on the amount of downstream data, while in practice, the scenarios with scarce data are common. Recent studies in the natural language processing (NLP) field show that prompt tuning, a new paradigm for tuning, alleviates the above issues and achieves promising results in various NLP tasks. In prompt tuning, the prompts inserted during tuning provide task-specific knowledge, which is especially beneficial for tasks with relatively scarce data. In this paper, we empirically evaluate the usage and effect of prompt tuning in code intelligence tasks. We conduct prompt tuning on popular pre-trained models CodeBERT and CodeT5 and experiment with three code intelligence tasks including defect prediction, code summarization, and code translation. Our experimental results show that prompt tuning consistently outperforms fine-tuning in all three tasks. In addition, prompt tuning shows great potential in low-resource scenarios, e.g., improving the BLEU scores of fine-tuning by more than 26\% on average for code summarization. Our results suggest that instead of fine-tuning, we could adapt prompt tuning for code intelligence tasks to achieve better performance, especially when lacking task-specific data.
Source Code Summarization with Structural Relative Position Guided Transformer
Feb 14, 2022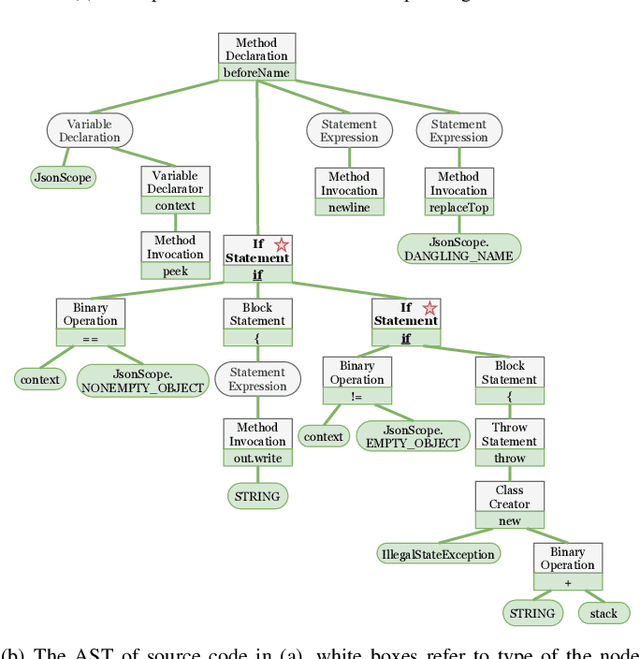
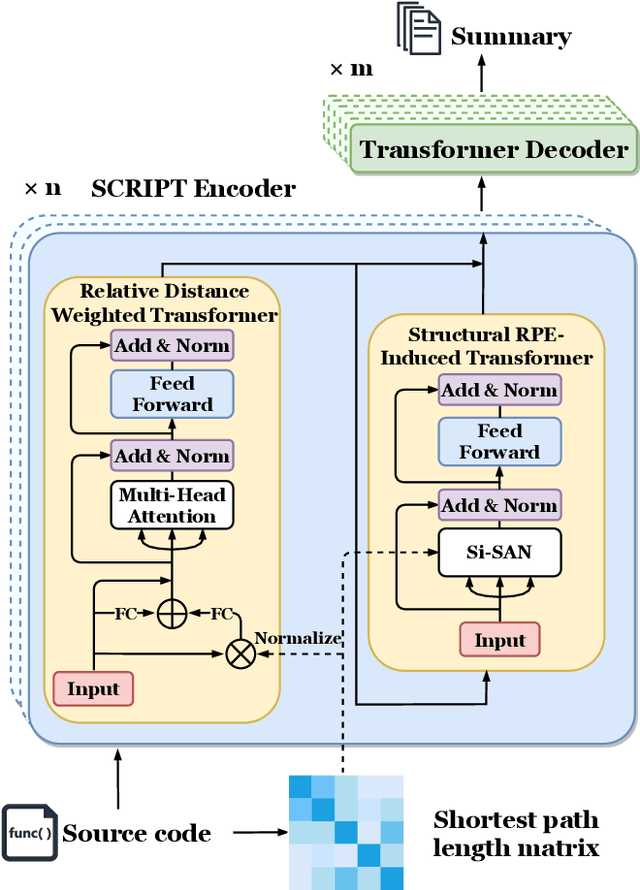
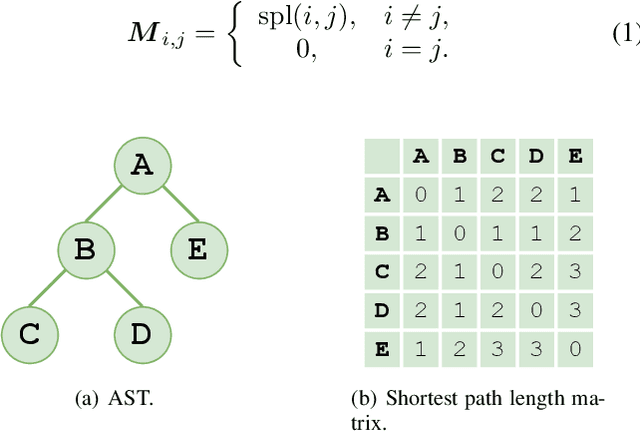
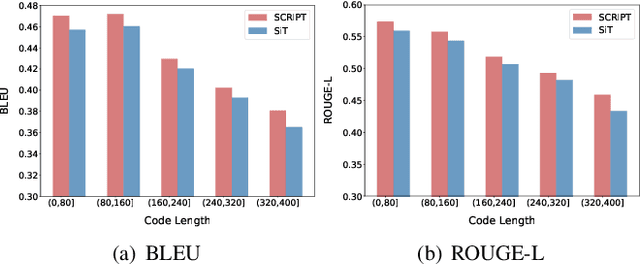
Source code summarization aims at generating concise and clear natural language descriptions for programming languages. Well-written code summaries are beneficial for programmers to participate in the software development and maintenance process. To learn the semantic representations of source code, recent efforts focus on incorporating the syntax structure of code into neural networks such as Transformer. Such Transformer-based approaches can better capture the long-range dependencies than other neural networks including Recurrent Neural Networks (RNNs), however, most of them do not consider the structural relative correlations between tokens, e.g., relative positions in Abstract Syntax Trees (ASTs), which is beneficial for code semantics learning. To model the structural dependency, we propose a Structural Relative Position guided Transformer, named SCRIPT. SCRIPT first obtains the structural relative positions between tokens via parsing the ASTs of source code, and then passes them into two types of Transformer encoders. One Transformer directly adjusts the input according to the structural relative distance; and the other Transformer encodes the structural relative positions during computing the self-attention scores. Finally, we stack these two types of Transformer encoders to learn representations of source code. Experimental results show that the proposed SCRIPT outperforms the state-of-the-art methods by at least 1.6%, 1.4% and 2.8% with respect to BLEU, ROUGE-L and METEOR on benchmark datasets, respectively. We further show that how the proposed SCRIPT captures the structural relative dependencies.