 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIFDNS: An Iterative Feedback-Driven Neuro-Symbolic Method for Faithful Logical Reasoning
Jan 12, 2026Large language models (LLMs) have demonstrated impressive capabilities across a wide range of reasoning tasks, including logical and mathematical problem-solving. While prompt-based methods like Chain-of-Thought (CoT) can enhance LLM reasoning abilities to some extent, they often suffer from a lack of faithfulness, where the derived conclusions may not align with the generated reasoning chain. To address this issue, researchers have explored neuro-symbolic approaches to bolster LLM logical reasoning capabilities. However, existing neuro-symbolic methods still face challenges with information loss during the process. To overcome these limitations, we introduce Iterative Feedback-Driven Neuro-Symbolic (IFDNS), a novel prompt-based method that employs a multi-round feedback mechanism to address LLM limitations in handling complex logical relationships. IFDNS utilizes iterative feedback during the logic extraction phase to accurately extract causal relationship statements and translate them into propositional and logical implication expressions, effectively mitigating information loss issues. Furthermore, IFDNS is orthogonal to existing prompt methods, allowing for seamless integration with various prompting approaches. Empirical evaluations across six datasets demonstrate the effectiveness of IFDNS in significantly improving the performance of CoT and Chain-of-Thought with Self-Consistency (CoT-SC). Specifically, IFDNS achieves a +9.40% accuracy boost for CoT on the LogiQA dataset and a +11.70% improvement for CoT-SC on the PrOntoQA dataset.
Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions
Oct 09, 2024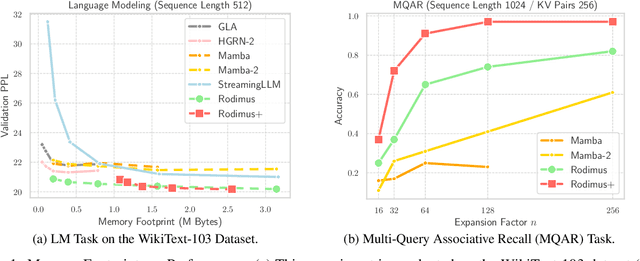
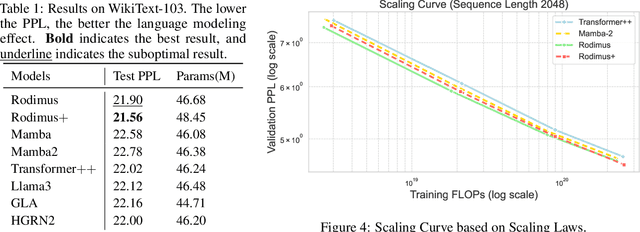
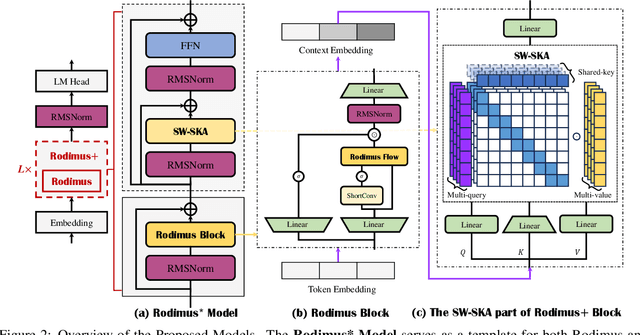
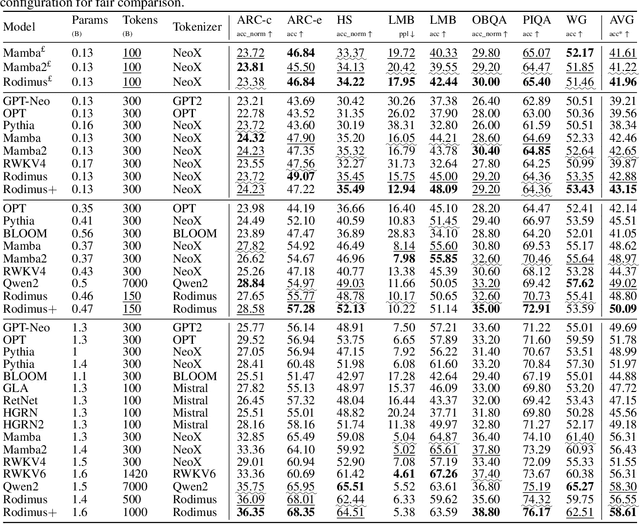
Recent advancements in Transformer-based large language models (LLMs) have set new standards in natural language processing. However, the classical softmax attention incurs significant computational costs, leading to a $O(T)$ complexity for per-token generation, where $T$ represents the context length. This work explores reducing LLMs' complexity while maintaining performance by introducing Rodimus and its enhanced version, Rodimus$+$. Rodimus employs an innovative data-dependent tempered selection (DDTS) mechanism within a linear attention-based, purely recurrent framework, achieving significant accuracy while drastically reducing the memory usage typically associated with recurrent models. This method exemplifies semantic compression by maintaining essential input information with fixed-size hidden states. Building on this, Rodimus$+$ combines Rodimus with the innovative Sliding Window Shared-Key Attention (SW-SKA) in a hybrid approach, effectively leveraging the complementary semantic, token, and head compression techniques. Our experiments demonstrate that Rodimus$+$-1.6B, trained on 1 trillion tokens, achieves superior downstream performance against models trained on more tokens, including Qwen2-1.5B and RWKV6-1.6B, underscoring its potential to redefine the accuracy-efficiency balance in LLMs. Model code and pre-trained checkpoints will be available soon.
CoBa: Convergence Balancer for Multitask Finetuning of Large Language Models
Oct 09, 2024



Multi-task learning (MTL) benefits the fine-tuning of large language models (LLMs) by providing a single model with improved performance and generalization ability across tasks, presenting a resource-efficient alternative to developing separate models for each task. Yet, existing MTL strategies for LLMs often fall short by either being computationally intensive or failing to ensure simultaneous task convergence. This paper presents CoBa, a new MTL approach designed to effectively manage task convergence balance with minimal computational overhead. Utilizing Relative Convergence Scores (RCS), Absolute Convergence Scores (ACS), and a Divergence Factor (DF), CoBa dynamically adjusts task weights during the training process, ensuring that the validation loss of all tasks progress towards convergence at an even pace while mitigating the issue of individual task divergence. The results of our experiments involving three disparate datasets underscore that this approach not only fosters equilibrium in task improvement but enhances the LLMs' performance by up to 13% relative to the second-best baselines. Code is open-sourced at https://github.com/codefuse-ai/MFTCoder.
A Survey on Language Models for Code
Nov 19, 2023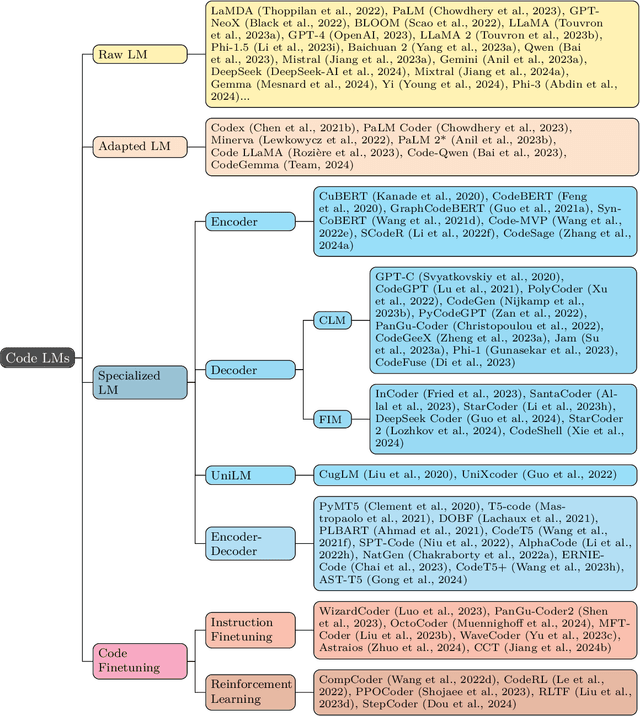
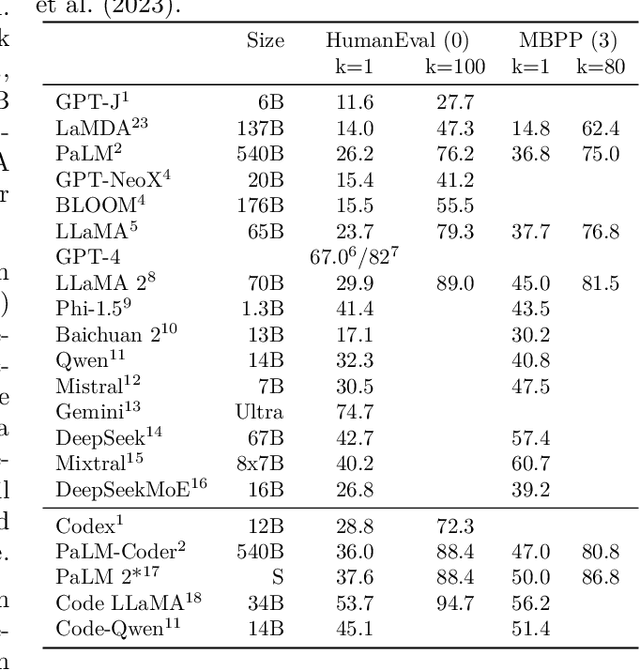
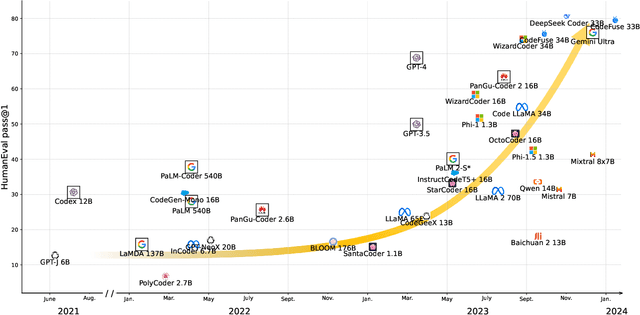
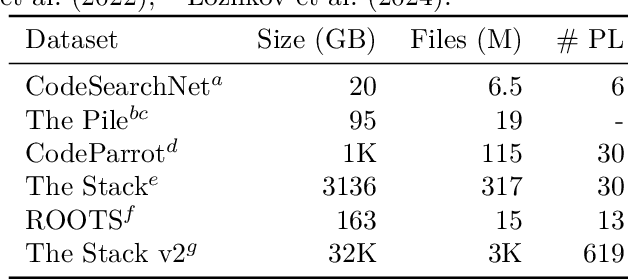
In this work we systematically review the recent advancements in code processing with language models, covering 50+ models, 30+ evaluation tasks, 150+ datasets, and 550 related works. We break down code processing models into general language models represented by the GPT family and specialized models that are specifically pretrained on code, often with tailored objectives. We discuss the relations and differences between these models, and highlight the historical transition of code modeling from statistical models and RNNs to pretrained Transformers and LLMs, which is exactly the same course that had been taken by NLP. We also discuss code-specific features such as AST, CFG, and unit tests, along with their application in training code language models, and identify key challenges and potential future directions in this domain. We keep the survey open and updated on GitHub repository at https://github.com/codefuse-ai/Awesome-Code-LLM.
MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning
Nov 04, 2023Code LLMs have emerged as a specialized research field, with remarkable studies dedicated to enhancing model's coding capabilities through fine-tuning on pre-trained models. Previous fine-tuning approaches were typically tailored to specific downstream tasks or scenarios, which meant separate fine-tuning for each task, requiring extensive training resources and posing challenges in terms of deployment and maintenance. Furthermore, these approaches failed to leverage the inherent interconnectedness among different code-related tasks. To overcome these limitations, we present a multi-task fine-tuning framework, MFTcoder, that enables simultaneous and parallel fine-tuning on multiple tasks. By incorporating various loss functions, we effectively address common challenges in multi-task learning, such as data imbalance, varying difficulty levels, and inconsistent convergence speeds. Extensive experiments have conclusively demonstrated that our multi-task fine-tuning approach outperforms both individual fine-tuning on single tasks and fine-tuning on a mixed ensemble of tasks. Moreover, MFTcoder offers efficient training capabilities, including efficient data tokenization modes and PEFT fine-tuning, resulting in significantly improved speed compared to traditional fine-tuning methods. MFTcoder seamlessly integrates with several mainstream open-source LLMs, such as CodeLLama and Qwen. Leveraging the CodeLLama foundation, our MFTcoder fine-tuned model, \textsc{CodeFuse-CodeLLama-34B}, achieves an impressive pass@1 score of 74.4\% on the HumaneEval benchmark, surpassing GPT-4 performance (67\%, zero-shot). MFTCoder is open-sourced at \url{https://github.com/codefuse-ai/MFTCOder}
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
Oct 10, 2023Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.
MultiCoder: Multi-Programming-Lingual Pre-Training for Low-Resource Code Completion
Dec 19, 2022Code completion is a valuable topic in both academia and industry. Recently, large-scale mono-programming-lingual (MonoPL) pre-training models have been proposed to boost the performance of code completion. However, the code completion on low-resource programming languages (PL) is difficult for the data-driven paradigm, while there are plenty of developers using low-resource PLs. On the other hand, there are few studies exploring the effects of multi-programming-lingual (MultiPL) pre-training for the code completion, especially the impact on low-resource programming languages. To this end, we propose the MultiCoder to enhance the low-resource code completion via MultiPL pre-training and MultiPL Mixture-of-Experts (MoE) layers. We further propose a novel PL-level MoE routing strategy (PL-MoE) for improving the code completion on all PLs. Experimental results on CodeXGLUE and MultiCC demonstrate that 1) the proposed MultiCoder significantly outperforms the MonoPL baselines on low-resource programming languages, and 2) the PL-MoE module further boosts the performance on six programming languages. In addition, we analyze the effects of the proposed method in details and explore the effectiveness of our method in a variety of scenarios.
Source Code Summarization with Structural Relative Position Guided Transformer
Feb 14, 2022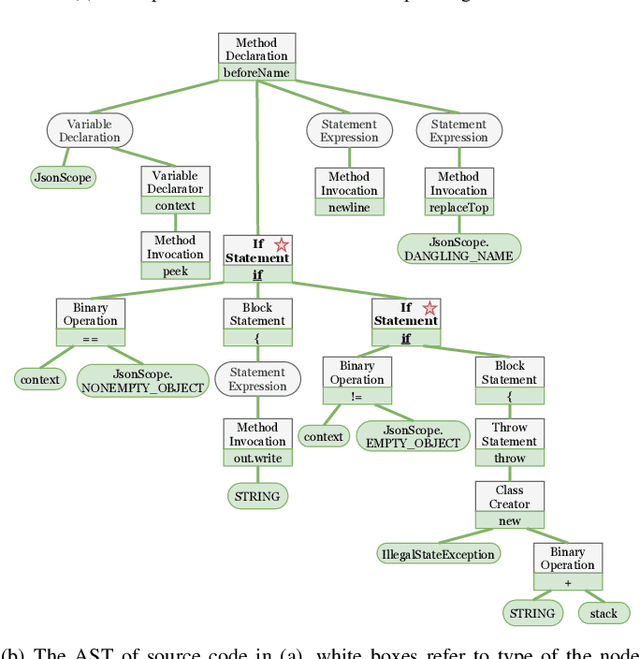
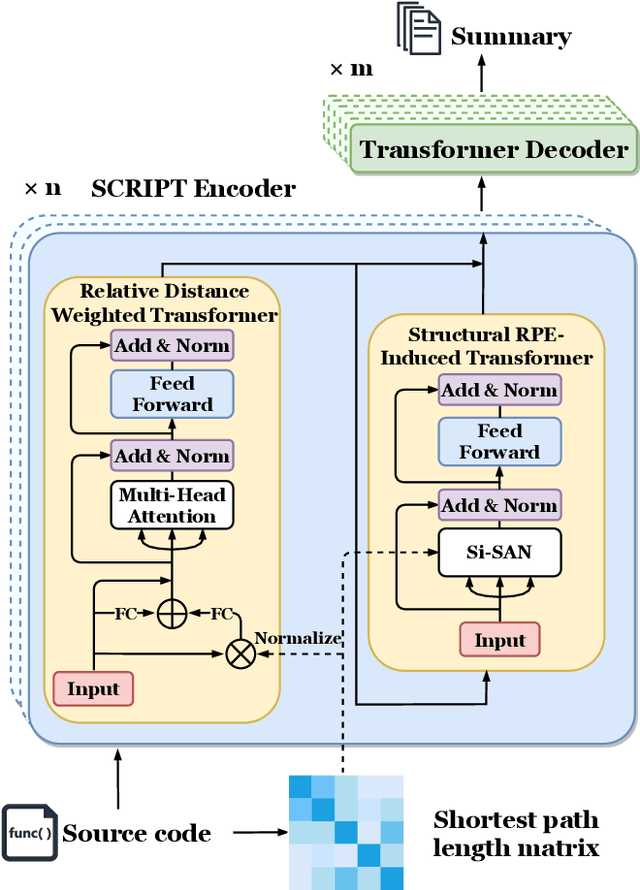
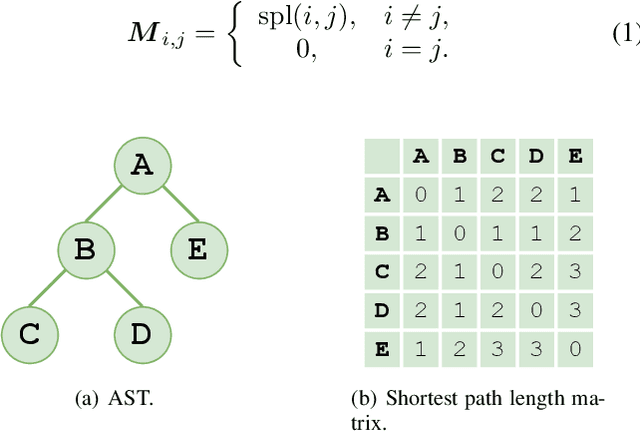
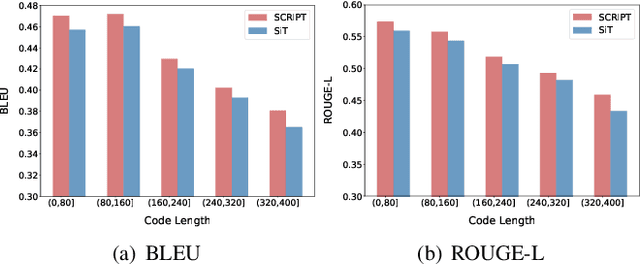
Source code summarization aims at generating concise and clear natural language descriptions for programming languages. Well-written code summaries are beneficial for programmers to participate in the software development and maintenance process. To learn the semantic representations of source code, recent efforts focus on incorporating the syntax structure of code into neural networks such as Transformer. Such Transformer-based approaches can better capture the long-range dependencies than other neural networks including Recurrent Neural Networks (RNNs), however, most of them do not consider the structural relative correlations between tokens, e.g., relative positions in Abstract Syntax Trees (ASTs), which is beneficial for code semantics learning. To model the structural dependency, we propose a Structural Relative Position guided Transformer, named SCRIPT. SCRIPT first obtains the structural relative positions between tokens via parsing the ASTs of source code, and then passes them into two types of Transformer encoders. One Transformer directly adjusts the input according to the structural relative distance; and the other Transformer encodes the structural relative positions during computing the self-attention scores. Finally, we stack these two types of Transformer encoders to learn representations of source code. Experimental results show that the proposed SCRIPT outperforms the state-of-the-art methods by at least 1.6%, 1.4% and 2.8% with respect to BLEU, ROUGE-L and METEOR on benchmark datasets, respectively. We further show that how the proposed SCRIPT captures the structural relative dependencies.