 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiEdit: Advancing Instruction-based Image Editing on Diverse and Challenging Tasks
Sep 18, 2025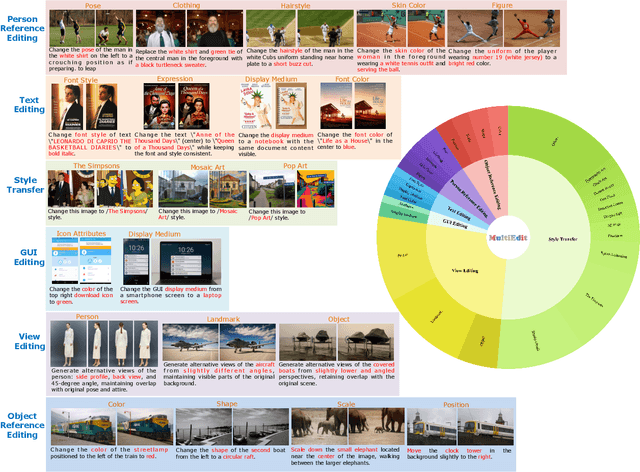
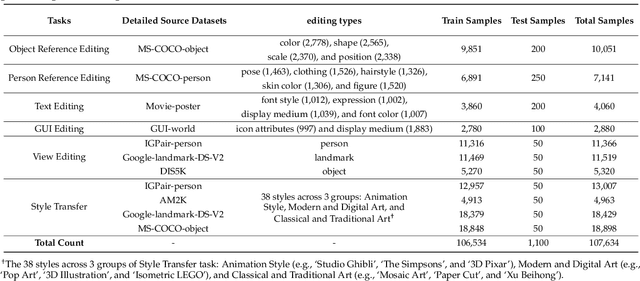
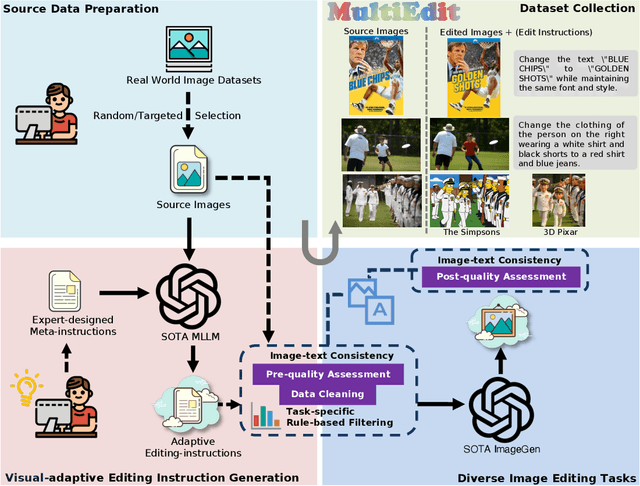
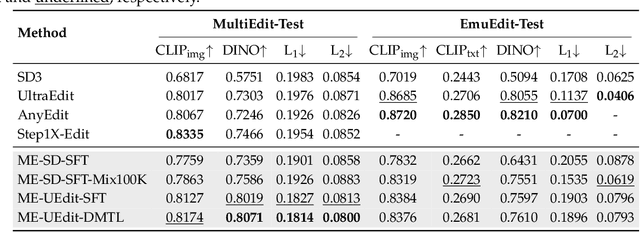
Current instruction-based image editing (IBIE) methods struggle with challenging editing tasks, as both editing types and sample counts of existing datasets are limited. Moreover, traditional dataset construction often contains noisy image-caption pairs, which may introduce biases and limit model capabilities in complex editing scenarios. To address these limitations, we introduce MultiEdit, a comprehensive dataset featuring over 107K high-quality image editing samples. It encompasses 6 challenging editing tasks through a diverse collection of 18 non-style-transfer editing types and 38 style transfer operations, covering a spectrum from sophisticated style transfer to complex semantic operations like person reference editing and in-image text editing. We employ a novel dataset construction pipeline that utilizes two multi-modal large language models (MLLMs) to generate visual-adaptive editing instructions and produce high-fidelity edited images, respectively. Extensive experiments demonstrate that fine-tuning foundational open-source models with our MultiEdit-Train set substantially improves models' performance on sophisticated editing tasks in our proposed MultiEdit-Test benchmark, while effectively preserving their capabilities on the standard editing benchmark. We believe MultiEdit provides a valuable resource for advancing research into more diverse and challenging IBIE capabilities. Our dataset is available at https://huggingface.co/datasets/inclusionAI/MultiEdit.
ABC: Adaptive BayesNet Structure Learning for Computational Scalable Multi-task Image Compression
Jun 18, 2025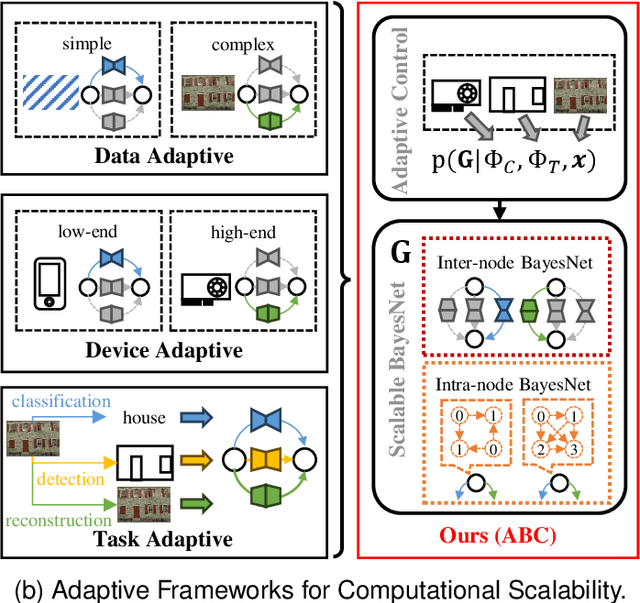

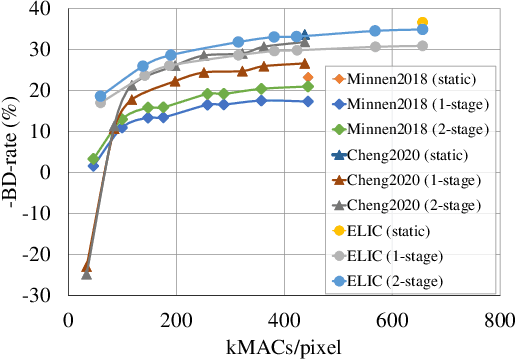
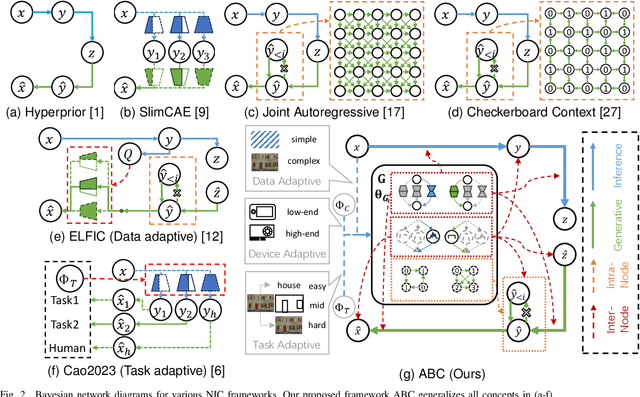
Neural Image Compression (NIC) has revolutionized image compression with its superior rate-distortion performance and multi-task capabilities, supporting both human visual perception and machine vision tasks. However, its widespread adoption is hindered by substantial computational demands. While existing approaches attempt to address this challenge through module-specific optimizations or pre-defined complexity levels, they lack comprehensive control over computational complexity. We present ABC (Adaptive BayesNet structure learning for computational scalable multi-task image Compression), a novel, comprehensive framework that achieves computational scalability across all NIC components through Bayesian network (BayesNet) structure learning. ABC introduces three key innovations: (i) a heterogeneous bipartite BayesNet (inter-node structure) for managing neural backbone computations; (ii) a homogeneous multipartite BayesNet (intra-node structure) for optimizing autoregressive unit processing; and (iii) an adaptive control module that dynamically adjusts the BayesNet structure based on device capabilities, input data complexity, and downstream task requirements. Experiments demonstrate that ABC enables full computational scalability with better complexity adaptivity and broader complexity control span, while maintaining competitive compression performance. Furthermore, the framework's versatility allows integration with various NIC architectures that employ BayesNet representations, making it a robust solution for ensuring computational scalability in NIC applications. Code is available in https://github.com/worldlife123/cbench_BaSIC.
ACCORD: Alleviating Concept Coupling through Dependence Regularization for Text-to-Image Diffusion Personalization
Mar 03, 2025Image personalization has garnered attention for its ability to customize Text-to-Image generation using only a few reference images. However, a key challenge in image personalization is the issue of conceptual coupling, where the limited number of reference images leads the model to form unwanted associations between the personalization target and other concepts. Current methods attempt to tackle this issue indirectly, leading to a suboptimal balance between text control and personalization fidelity. In this paper, we take a direct approach to the concept coupling problem through statistical analysis, revealing that it stems from two distinct sources of dependence discrepancies. We therefore propose two complementary plug-and-play loss functions: Denoising Decouple Loss and Prior Decouple loss, each designed to minimize one type of dependence discrepancy. Extensive experiments demonstrate that our approach achieves a superior trade-off between text control and personalization fidelity.
Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions
Oct 09, 2024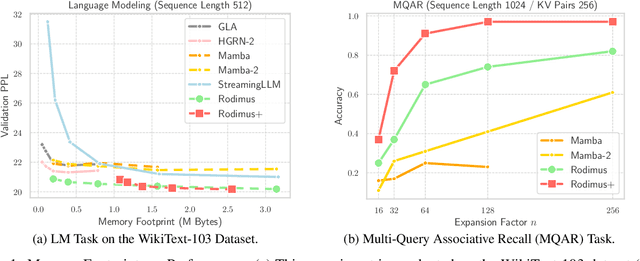
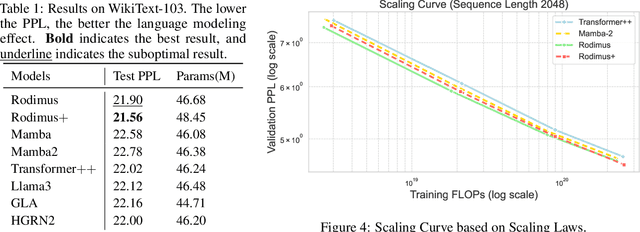
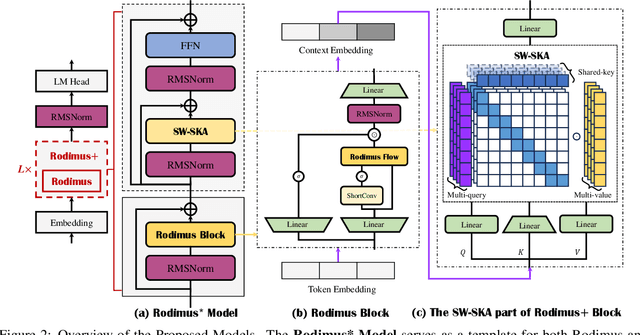
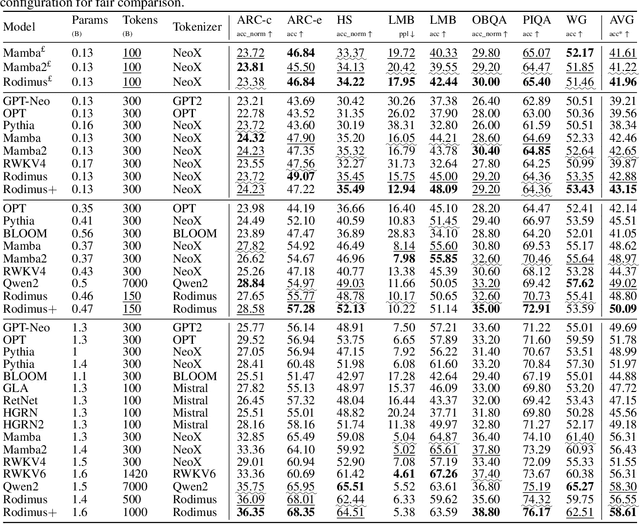
Recent advancements in Transformer-based large language models (LLMs) have set new standards in natural language processing. However, the classical softmax attention incurs significant computational costs, leading to a $O(T)$ complexity for per-token generation, where $T$ represents the context length. This work explores reducing LLMs' complexity while maintaining performance by introducing Rodimus and its enhanced version, Rodimus$+$. Rodimus employs an innovative data-dependent tempered selection (DDTS) mechanism within a linear attention-based, purely recurrent framework, achieving significant accuracy while drastically reducing the memory usage typically associated with recurrent models. This method exemplifies semantic compression by maintaining essential input information with fixed-size hidden states. Building on this, Rodimus$+$ combines Rodimus with the innovative Sliding Window Shared-Key Attention (SW-SKA) in a hybrid approach, effectively leveraging the complementary semantic, token, and head compression techniques. Our experiments demonstrate that Rodimus$+$-1.6B, trained on 1 trillion tokens, achieves superior downstream performance against models trained on more tokens, including Qwen2-1.5B and RWKV6-1.6B, underscoring its potential to redefine the accuracy-efficiency balance in LLMs. Model code and pre-trained checkpoints will be available soon.
Density Matters: Improved Core-set for Active Domain Adaptive Segmentation
Dec 15, 2023



Active domain adaptation has emerged as a solution to balance the expensive annotation cost and the performance of trained models in semantic segmentation. However, existing works usually ignore the correlation between selected samples and its local context in feature space, which leads to inferior usage of annotation budgets. In this work, we revisit the theoretical bound of the classical Core-set method and identify that the performance is closely related to the local sample distribution around selected samples. To estimate the density of local samples efficiently, we introduce a local proxy estimator with Dynamic Masked Convolution and develop a Density-aware Greedy algorithm to optimize the bound. Extensive experiments demonstrate the superiority of our approach. Moreover, with very few labels, our scheme achieves comparable performance to the fully supervised counterpart.
BasisFormer: Attention-based Time Series Forecasting with Learnable and Interpretable Basis
Oct 31, 2023



Bases have become an integral part of modern deep learning-based models for time series forecasting due to their ability to act as feature extractors or future references. To be effective, a basis must be tailored to the specific set of time series data and exhibit distinct correlation with each time series within the set. However, current state-of-the-art methods are limited in their ability to satisfy both of these requirements simultaneously. To address this challenge, we propose BasisFormer, an end-to-end time series forecasting architecture that leverages learnable and interpretable bases. This architecture comprises three components: First, we acquire bases through adaptive self-supervised learning, which treats the historical and future sections of the time series as two distinct views and employs contrastive learning. Next, we design a Coef module that calculates the similarity coefficients between the time series and bases in the historical view via bidirectional cross-attention. Finally, we present a Forecast module that selects and consolidates the bases in the future view based on the similarity coefficients, resulting in accurate future predictions. Through extensive experiments on six datasets, we demonstrate that BasisFormer outperforms previous state-of-the-art methods by 11.04\% and 15.78\% respectively for univariate and multivariate forecasting tasks. Code is available at: \url{https://github.com/nzl5116190/Basisformer}
Human in Events: A Large-Scale Benchmark for Human-centric Video Analysis in Complex Events
May 19, 2020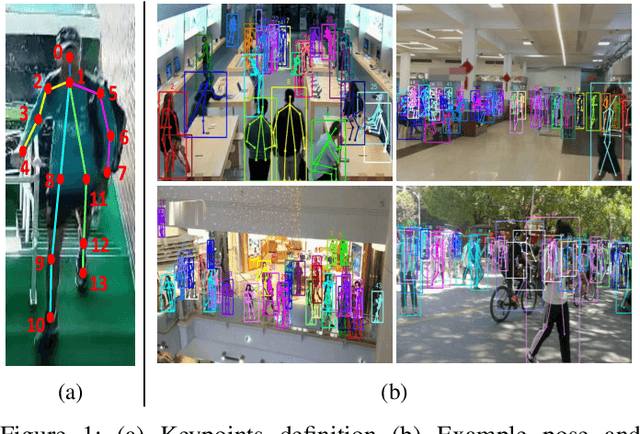
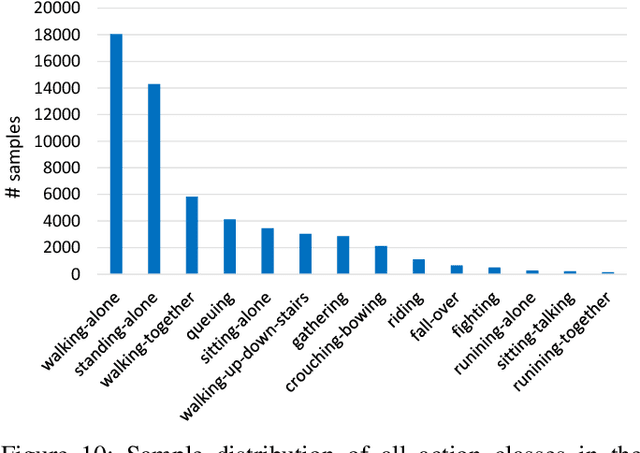
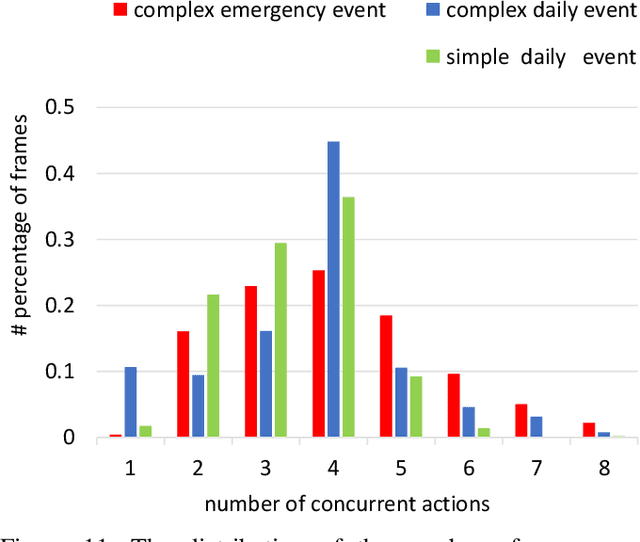
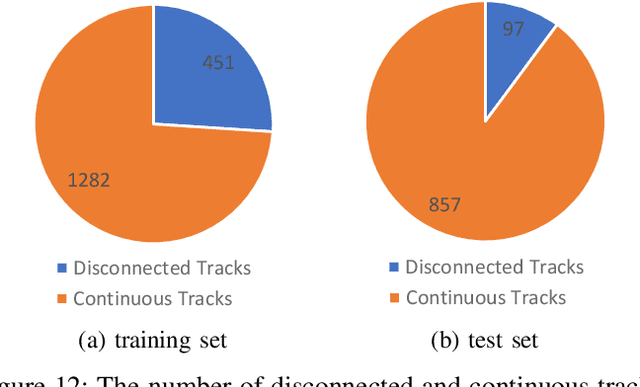
Along with the development of the modern smart city, human-centric video analysis is encountering the challenge of diverse and complex events in real scenes. A complex event relates to dense crowds, anomalous individual, or collective behavior. However, limited by the scale of available surveillance video datasets, few existing human analysis approaches report their performances on such complex events. To this end, we present a new large-scale dataset, named Human-in-Events or HiEve (human-centric video analysis in complex events), for understanding human motions, poses, and actions in a variety of realistic events, especially crowd & complex events. It contains a record number of poses (>1M), the largest number of action labels (>56k) for complex events, and one of the largest number of trajectories lasting for long terms (with average trajectory length >480). Besides, an online evaluation server is built for researchers to evaluate their approaches. Furthermore, we conduct extensive experiments on recent video analysis approaches, demonstrating that the HiEve is a challenging dataset for human-centric video analysis. We expect that the dataset will advance the development of cutting-edge techniques in human-centric analysis and the understanding of complex events. The dataset is available at http://humaninevents.org