 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Stability of KL Divergence under Gaussian Perturbations
Apr 13, 2026We study the problem of characterizing the stability of Kullback-Leibler (KL) divergence under Gaussian perturbations beyond Gaussian families. Existing relaxed triangle inequalities for KL divergence critically rely on the assumption that all involved distributions are Gaussian, which limits their applicability in modern applications such as out-of-distribution (OOD) detection with flow-based generative models. In this paper, we remove this restriction by establishing a sharp stability bound between an arbitrary distribution and Gaussian families under mild moment conditions. Specifically, let $P$ be a distribution with finite second moment, and let $\mathcal{N}_1$ and $\mathcal{N}_2$ be multivariate Gaussian distributions. We show that if $KL(P||\mathcal{N}_1)$ is large and $KL(\mathcal{N}_1||\mathcal{N}_2)$ is at most $ε$, then $KL(P||\mathcal{N}_2) \ge KL(P||\mathcal{N}_1) - O(\sqrtε)$. Moreover, we prove that this $\sqrtε$ rate is optimal in general, even within the Gaussian family. This result reveals an intrinsic stability property of KL divergence under Gaussian perturbations, extending classical Gaussian-only relaxed triangle inequalities to general distributions. The result is non-trivial due to the asymmetry of KL divergence and the absence of a triangle inequality in general probability spaces. As an application, we provide a rigorous foundation for KL-based OOD analysis in flow-based models, removing strong Gaussian assumptions used in prior work. More broadly, our result enables KL-based reasoning in non-Gaussian settings arising in deep learning and reinforcement learning.
Cooperative-Competitive Team Play of Real-World Craft Robots
Feb 24, 2026Multi-agent deep Reinforcement Learning (RL) has made significant progress in developing intelligent game-playing agents in recent years. However, the efficient training of collective robots using multi-agent RL and the transfer of learned policies to real-world applications remain open research questions. In this work, we first develop a comprehensive robotic system, including simulation, distributed learning framework, and physical robot components. We then propose and evaluate reinforcement learning techniques designed for efficient training of cooperative and competitive policies on this platform. To address the challenges of multi-agent sim-to-real transfer, we introduce Out of Distribution State Initialization (OODSI) to mitigate the impact of the sim-to-real gap. In the experiments, OODSI improves the Sim2Real performance by 20%. We demonstrate the effectiveness of our approach through experiments with a multi-robot car competitive game and a cooperative task in real-world settings.
Relaxed Triangle Inequality for Kullback-Leibler Divergence Between Multivariate Gaussian Distributions
Jan 31, 2026The Kullback-Leibler (KL) divergence is not a proper distance metric and does not satisfy the triangle inequality, posing theoretical challenges in certain practical applications. Existing work has demonstrated that KL divergence between multivariate Gaussian distributions follows a relaxed triangle inequality. Given any three multivariate Gaussian distributions $\mathcal{N}_1, \mathcal{N}_2$, and $\mathcal{N}_3$, if $KL(\mathcal{N}_1, \mathcal{N}_2)\leq ε_1$ and $KL(\mathcal{N}_2, \mathcal{N}_3)\leq ε_2$, then $KL(\mathcal{N}_1, \mathcal{N}_3)< 3ε_1+3ε_2+2\sqrt{ε_1ε_2}+o(ε_1)+o(ε_2)$. However, the supremum of $KL(\mathcal{N}_1, \mathcal{N}_3)$ is still unknown. In this paper, we investigate the relaxed triangle inequality for the KL divergence between multivariate Gaussian distributions and give the supremum of $KL(\mathcal{N}_1, \mathcal{N}_3)$ as well as the conditions when the supremum can be attained. When $ε_1$ and $ε_2$ are small, the supremum is $ε_1+ε_2+\sqrt{ε_1ε_2}+o(ε_1)+o(ε_2)$. Finally, we demonstrate several applications of our results in out-of-distribution detection with flow-based generative models and safe reinforcement learning.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
MCOP: Multi-UAV Collaborative Occupancy Prediction
Oct 14, 2025Unmanned Aerial Vehicle (UAV) swarm systems necessitate efficient collaborative perception mechanisms for diverse operational scenarios. Current Bird's Eye View (BEV)-based approaches exhibit two main limitations: bounding-box representations fail to capture complete semantic and geometric information of the scene, and their performance significantly degrades when encountering undefined or occluded objects. To address these limitations, we propose a novel multi-UAV collaborative occupancy prediction framework. Our framework effectively preserves 3D spatial structures and semantics through integrating a Spatial-Aware Feature Encoder and Cross-Agent Feature Integration. To enhance efficiency, we further introduce Altitude-Aware Feature Reduction to compactly represent scene information, along with a Dual-Mask Perceptual Guidance mechanism to adaptively select features and reduce communication overhead. Due to the absence of suitable benchmark datasets, we extend three datasets for evaluation: two virtual datasets (Air-to-Pred-Occ and UAV3D-Occ) and one real-world dataset (GauUScene-Occ). Experiments results demonstrate that our method achieves state-of-the-art accuracy, significantly outperforming existing collaborative methods while reducing communication overhead to only a fraction of previous approaches.
ABC: Adaptive BayesNet Structure Learning for Computational Scalable Multi-task Image Compression
Jun 18, 2025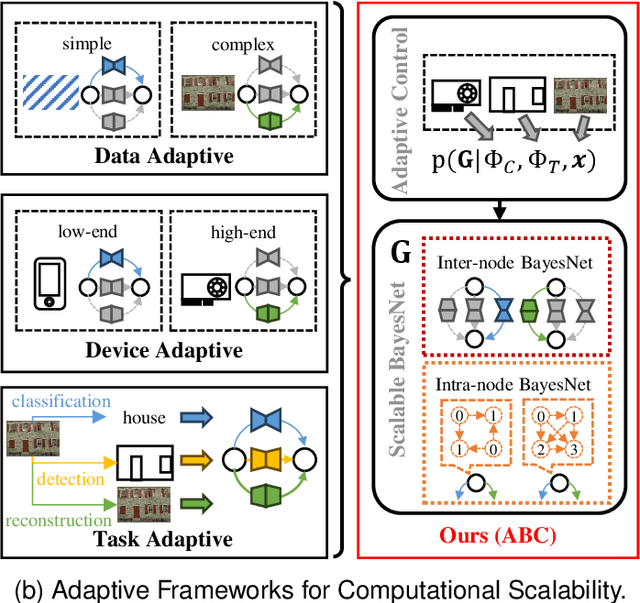

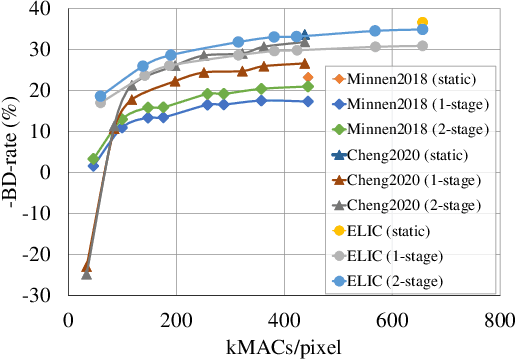
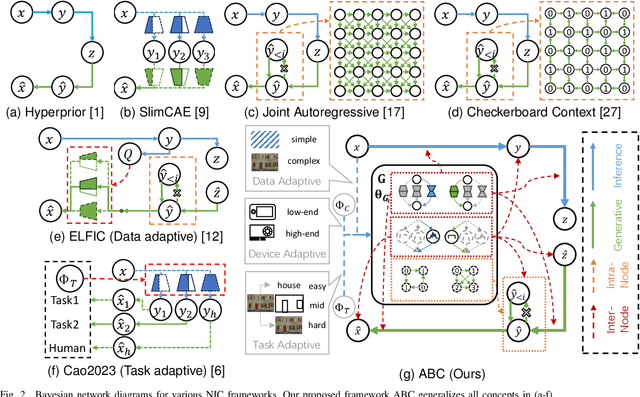
Neural Image Compression (NIC) has revolutionized image compression with its superior rate-distortion performance and multi-task capabilities, supporting both human visual perception and machine vision tasks. However, its widespread adoption is hindered by substantial computational demands. While existing approaches attempt to address this challenge through module-specific optimizations or pre-defined complexity levels, they lack comprehensive control over computational complexity. We present ABC (Adaptive BayesNet structure learning for computational scalable multi-task image Compression), a novel, comprehensive framework that achieves computational scalability across all NIC components through Bayesian network (BayesNet) structure learning. ABC introduces three key innovations: (i) a heterogeneous bipartite BayesNet (inter-node structure) for managing neural backbone computations; (ii) a homogeneous multipartite BayesNet (intra-node structure) for optimizing autoregressive unit processing; and (iii) an adaptive control module that dynamically adjusts the BayesNet structure based on device capabilities, input data complexity, and downstream task requirements. Experiments demonstrate that ABC enables full computational scalability with better complexity adaptivity and broader complexity control span, while maintaining competitive compression performance. Furthermore, the framework's versatility allows integration with various NIC architectures that employ BayesNet representations, making it a robust solution for ensuring computational scalability in NIC applications. Code is available in https://github.com/worldlife123/cbench_BaSIC.
Detecting Emotional Incongruity of Sarcasm by Commonsense Reasoning
Dec 17, 2024This paper focuses on sarcasm detection, which aims to identify whether given statements convey criticism, mockery, or other negative sentiment opposite to the literal meaning. To detect sarcasm, humans often require a comprehensive understanding of the semantics in the statement and even resort to external commonsense to infer the fine-grained incongruity. However, existing methods lack commonsense inferential ability when they face complex real-world scenarios, leading to unsatisfactory performance. To address this problem, we propose a novel framework for sarcasm detection, which conducts incongruity reasoning based on commonsense augmentation, called EICR. Concretely, we first employ retrieval-augmented large language models to supplement the missing but indispensable commonsense background knowledge. To capture complex contextual associations, we construct a dependency graph and obtain the optimized topology via graph refinement. We further introduce an adaptive reasoning skeleton that integrates prior rules to extract sentiment-inconsistent subgraphs explicitly. To eliminate the possible spurious relations between words and labels, we employ adversarial contrastive learning to enhance the robustness of the detector. Experiments conducted on five datasets demonstrate the effectiveness of EICR.
Seed-CTS: Unleashing the Power of Tree Search for Superior Performance in Competitive Coding Tasks
Dec 17, 2024Competition-level code generation tasks pose significant challenges for current state-of-the-art large language models (LLMs). For example, on the LiveCodeBench-Hard dataset, models such as O1-Mini and O1-Preview achieve pass@1 rates of only 0.366 and 0.143, respectively. While tree search techniques have proven effective in domains like mathematics and general coding, their potential in competition-level code generation remains under-explored. In this work, we propose a novel token-level tree search method specifically designed for code generation. Leveraging Qwen2.5-Coder-32B-Instruct, our approach achieves a pass rate of 0.305 on LiveCodeBench-Hard, surpassing the pass@100 performance of GPT4o-0513 (0.245). Furthermore, by integrating Chain-of-Thought (CoT) prompting, we improve our method's performance to 0.351, approaching O1-Mini's pass@1 rate. To ensure reproducibility, we report the average number of generations required per problem by our tree search method on the test set. Our findings underscore the potential of tree search to significantly enhance performance on competition-level code generation tasks. This opens up new possibilities for large-scale synthesis of challenging code problems supervised fine-tuning (SFT) data, advancing competition-level code generation tasks.
Reward-Augmented Data Enhances Direct Preference Alignment of LLMs
Oct 10, 2024



Preference alignment in Large Language Models (LLMs) has significantly improved their ability to adhere to human instructions and intentions. However, existing direct alignment algorithms primarily focus on relative preferences and often overlook the qualitative aspects of responses. Striving to maximize the implicit reward gap between the chosen and the slightly inferior rejected responses can cause overfitting and unnecessary unlearning of the high-quality rejected responses. The unawareness of the reward scores also drives the LLM to indiscriminately favor the low-quality chosen responses and fail to generalize to responses with the highest rewards, which are sparse in data. To overcome these shortcomings, our study introduces reward-conditioned LLM policies that discern and learn from the entire spectrum of response quality within the dataset, helping extrapolate to more optimal regions. We propose an effective yet simple data relabeling method that conditions the preference pairs on quality scores to construct a reward-augmented dataset. This dataset is easily integrated with existing direct alignment algorithms and is applicable to any preference dataset. The experimental results across instruction-following benchmarks including AlpacaEval, MT-Bench, and Arena-Hard-Auto demonstrate that our approach consistently boosts the performance of DPO by a considerable margin across diverse models. Additionally, our method improves the average accuracy on various academic benchmarks. When applying our method to on-policy data, the resulting DPO model achieves SOTA results on AlpacaEval. Through ablation studies, we demonstrate that our method not only maximizes the utility of preference data but also mitigates the issue of unlearning, demonstrating its broad effectiveness beyond mere dataset expansion. Our code is available at https://github.com/shenao-zhang/reward-augmented-preference.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.