 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Position Bias: Shifting Context Compression from Position-Driven to Semantic-Driven
May 10, 2026Large Language Models (LLMs) have demonstrated exceptional performance across diverse tasks. However, their deployment in long-context scenarios faces high computational overhead and information redundancy. While soft prompt compression has emerged as a promising way to mitigate these costs by compressing sequences into compact embeddings, existing paradigms remain fundamentally constrained by position bias: they primarily rely on learnable tokens insertion at fixed positions or group tokens according to their physical token layout, thereby inducing performance instability and semantic fragmentation. To overcome this bottleneck, we propose Semantic Consistency Context Compression (SeCo), a method that shifts context compression from position-driven to semantic-driven. Rather than constraint by physical token layout, SeCo dynamically anchors compression directly in the semantic space by selecting query-relevant tokens as semantic centers and aggregating remaining tokens via consistency-weighted merging. This design inherently preserves semantic consistency while eliminating position bias. Extensive experiments on 14 benchmarks across two backbone models demonstrate that SeCo consistently shows superiority in downstream tasks, inference latency, and out-of-domain robustness. The code is available at https://anonymous.4open.science/r/seco-EE5E.
SAKE: Self-aware Knowledge Exploitation-Exploration for Grounded Multimodal Named Entity Recognition
Apr 22, 2026Grounded Multimodal Named Entity Recognition (GMNER) aims to extract named entities and localize their visual regions within image-text pairs, serving as a pivotal capability for various downstream applications. In open-world social media platforms, GMNER remains challenging due to the prevalence of long-tailed, rapidly evolving, and unseen entities. To tackle this, existing approaches typically rely on either external knowledge exploration through heuristic retrieval or internal knowledge exploitation via iterative refinement in Multimodal Large Language Models (MLLMs). However, heuristic retrieval often introduces noisy or conflicting evidence that degrades precision on known entities, while solely internal exploitation is constrained by the knowledge boundaries of MLLMs and prone to hallucinations. To address this, we propose SAKE, an end-to-end agentic framework that harmonizes internal knowledge exploitation and external knowledge exploration via self-aware reasoning and adaptive search tool invocation. We implement this via a two-stage training paradigm. First, we propose Difficulty-aware Search Tag Generation, which quantifies the model's entity-level uncertainty through multiple forward samplings to produce explicit knowledge-gap signals. Based on these signals, we construct SAKE-SeCoT, a high-quality Chain-of-Thought dataset that equips the model with basic self-awareness and tool-use capabilities through supervised fine-tuning. Second, we employ agentic reinforcement learning with a hybrid reward function that penalizes unnecessary retrieval, enabling the model to evolve from rigid search imitation to genuine self-aware decision-making about when retrieval is truly necessary. Extensive experiments on two widely used social media benchmarks demonstrate SAKE's effectiveness.
An Iteration-Free Fixed-Point Estimator for Diffusion Inversion
Dec 09, 2025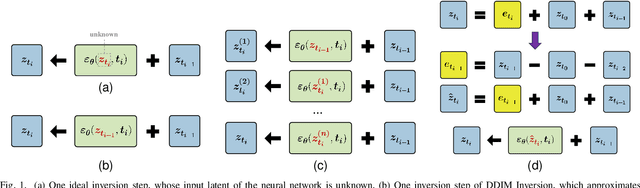



Diffusion inversion aims to recover the initial noise corresponding to a given image such that this noise can reconstruct the original image through the denoising diffusion process. The key component of diffusion inversion is to minimize errors at each inversion step, thereby mitigating cumulative inaccuracies. Recently, fixed-point iteration has emerged as a widely adopted approach to minimize reconstruction errors at each inversion step. However, it suffers from high computational costs due to its iterative nature and the complexity of hyperparameter selection. To address these issues, we propose an iteration-free fixed-point estimator for diffusion inversion. First, we derive an explicit expression of the fixed point from an ideal inversion step. Unfortunately, it inherently contains an unknown data prediction error. Building upon this, we introduce the error approximation, which uses the calculable error from the previous inversion step to approximate the unknown error at the current inversion step. This yields a calculable, approximate expression for the fixed point, which is an unbiased estimator characterized by low variance, as shown by our theoretical analysis. We evaluate reconstruction performance on two text-image datasets, NOCAPS and MS-COCO. Compared to DDIM inversion and other inversion methods based on the fixed-point iteration, our method achieves consistent and superior performance in reconstruction tasks without additional iterations or training.
CoS: Towards Optimal Event Scheduling via Chain-of-Scheduling
Nov 17, 2025Recommending event schedules is a key issue in Event-based Social Networks (EBSNs) in order to maintain user activity. An effective recommendation is required to maximize the user's preference, subjecting to both time and geographical constraints. Existing methods face an inherent trade-off among efficiency, effectiveness, and generalization, due to the NP-hard nature of the problem. This paper proposes the Chain-of-Scheduling (CoS) framework, which activates the event scheduling capability of Large Language Models (LLMs) through a guided, efficient scheduling process. CoS enhances LLM by formulating the schedule task into three atomic stages, i.e., exploration, verification and integration. Then we enable the LLMs to generate CoS autonomously via Knowledge Distillation (KD). Experimental results show that CoS achieves near-theoretical optimal effectiveness with high efficiency on three real-world datasets in a interpretable manner. Moreover, it demonstrates strong zero-shot learning ability on out-of-domain data.
AlignSurvey: A Comprehensive Benchmark for Human Preferences Alignment in Social Surveys
Nov 13, 2025Understanding human attitudes, preferences, and behaviors through social surveys is essential for academic research and policymaking. Yet traditional surveys face persistent challenges, including fixed-question formats, high costs, limited adaptability, and difficulties ensuring cross-cultural equivalence. While recent studies explore large language models (LLMs) to simulate survey responses, most are limited to structured questions, overlook the entire survey process, and risks under-representing marginalized groups due to training data biases. We introduce AlignSurvey, the first benchmark that systematically replicates and evaluates the full social survey pipeline using LLMs. It defines four tasks aligned with key survey stages: social role modeling, semi-structured interview modeling, attitude stance modeling and survey response modeling. It also provides task-specific evaluation metrics to assess alignment fidelity, consistency, and fairness at both individual and group levels, with a focus on demographic diversity. To support AlignSurvey, we construct a multi-tiered dataset architecture: (i) the Social Foundation Corpus, a cross-national resource with 44K+ interview dialogues and 400K+ structured survey records; and (ii) a suite of Entire-Pipeline Survey Datasets, including the expert-annotated AlignSurvey-Expert (ASE) and two nationally representative surveys for cross-cultural evaluation. We release the SurveyLM family, obtained through two-stage fine-tuning of open-source LLMs, and offer reference models for evaluating domain-specific alignment. All datasets, models, and tools are available at github and huggingface to support transparent and socially responsible research.
Functional Consistency of LLM Code Embeddings: A Self-Evolving Data Synthesis Framework for Benchmarking
Aug 27, 2025Embedding models have demonstrated strong performance in tasks like clustering, retrieval, and feature extraction while offering computational advantages over generative models and cross-encoders. Benchmarks such as MTEB have shown that text embeddings from large language models (LLMs) capture rich semantic information, but their ability to reflect code-level functional semantics remains unclear. Existing studies largely focus on code clone detection, which emphasizes syntactic similarity and overlooks functional understanding. In this paper, we focus on the functional consistency of LLM code embeddings, which determines if two code snippets perform the same function regardless of syntactic differences. We propose a novel data synthesis framework called Functionality-Oriented Code Self-Evolution to construct diverse and challenging benchmarks. Specifically, we define code examples across four semantic and syntactic categories and find that existing datasets predominantly capture syntactic properties. Our framework generates four unique variations from a single code instance, providing a broader spectrum of code examples that better reflect functional differences. Extensive experiments on three downstream tasks-code clone detection, code functional consistency identification, and code retrieval-demonstrate that embedding models significantly improve their performance when trained on our evolved datasets. These results highlight the effectiveness and generalization of our data synthesis framework, advancing the functional understanding of code.
Detecting Emotional Incongruity of Sarcasm by Commonsense Reasoning
Dec 17, 2024This paper focuses on sarcasm detection, which aims to identify whether given statements convey criticism, mockery, or other negative sentiment opposite to the literal meaning. To detect sarcasm, humans often require a comprehensive understanding of the semantics in the statement and even resort to external commonsense to infer the fine-grained incongruity. However, existing methods lack commonsense inferential ability when they face complex real-world scenarios, leading to unsatisfactory performance. To address this problem, we propose a novel framework for sarcasm detection, which conducts incongruity reasoning based on commonsense augmentation, called EICR. Concretely, we first employ retrieval-augmented large language models to supplement the missing but indispensable commonsense background knowledge. To capture complex contextual associations, we construct a dependency graph and obtain the optimized topology via graph refinement. We further introduce an adaptive reasoning skeleton that integrates prior rules to extract sentiment-inconsistent subgraphs explicitly. To eliminate the possible spurious relations between words and labels, we employ adversarial contrastive learning to enhance the robustness of the detector. Experiments conducted on five datasets demonstrate the effectiveness of EICR.
Boosting Fine-Grained Visual Anomaly Detection with Coarse-Knowledge-Aware Adversarial Learning
Dec 17, 2024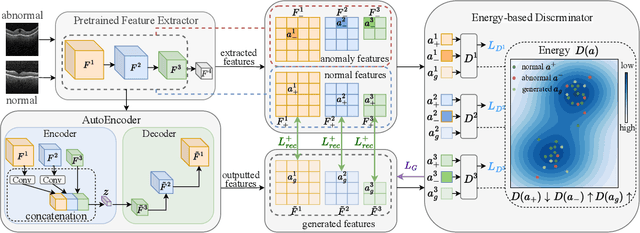
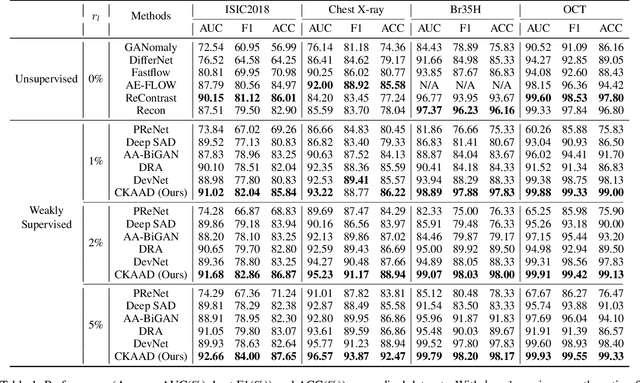
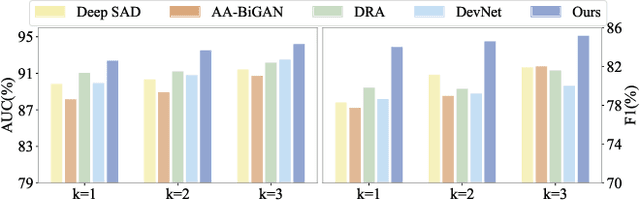

Many unsupervised visual anomaly detection methods train an auto-encoder to reconstruct normal samples and then leverage the reconstruction error map to detect and localize the anomalies. However, due to the powerful modeling and generalization ability of neural networks, some anomalies can also be well reconstructed, resulting in unsatisfactory detection and localization accuracy. In this paper, a small coarsely-labeled anomaly dataset is first collected. Then, a coarse-knowledge-aware adversarial learning method is developed to align the distribution of reconstructed features with that of normal features. The alignment can effectively suppress the auto-encoder's reconstruction ability on anomalies and thus improve the detection accuracy. Considering that anomalies often only occupy very small areas in anomalous images, a patch-level adversarial learning strategy is further developed. Although no patch-level anomalous information is available, we rigorously prove that by simply viewing any patch features from anomalous images as anomalies, the proposed knowledge-aware method can also align the distribution of reconstructed patch features with the normal ones. Experimental results on four medical datasets and two industrial datasets demonstrate the effectiveness of our method in improving the detection and localization performance.
Multimodal Clickbait Detection by De-confounding Biases Using Causal Representation Inference
Oct 10, 2024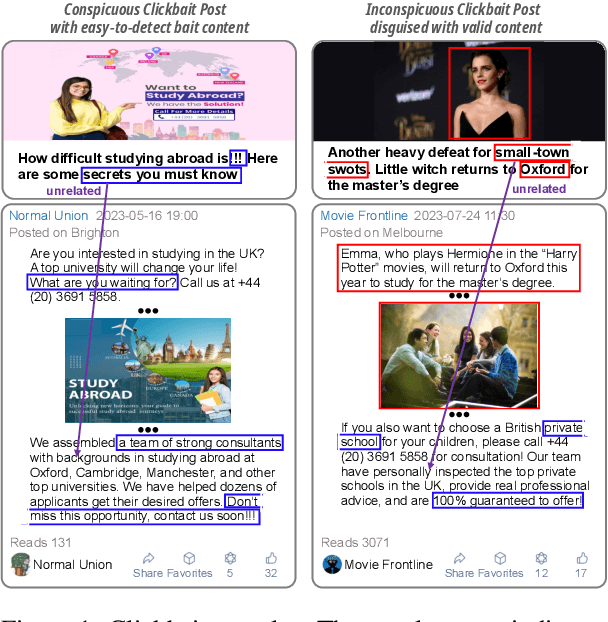
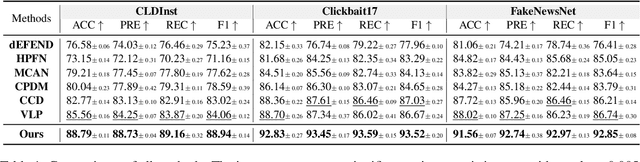
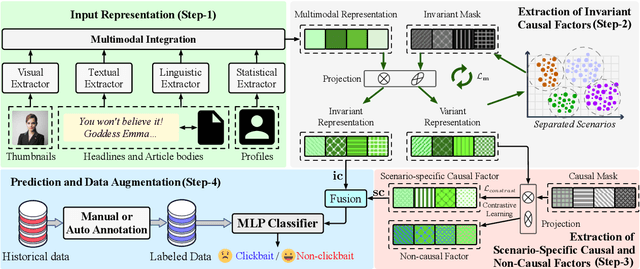

This paper focuses on detecting clickbait posts on the Web. These posts often use eye-catching disinformation in mixed modalities to mislead users to click for profit. That affects the user experience and thus would be blocked by content provider. To escape detection, malicious creators use tricks to add some irrelevant non-bait content into bait posts, dressing them up as legal to fool the detector. This content often has biased relations with non-bait labels, yet traditional detectors tend to make predictions based on simple co-occurrence rather than grasping inherent factors that lead to malicious behavior. This spurious bias would easily cause misjudgments. To address this problem, we propose a new debiased method based on causal inference. We first employ a set of features in multiple modalities to characterize the posts. Considering these features are often mixed up with unknown biases, we then disentangle three kinds of latent factors from them, including the invariant factor that indicates intrinsic bait intention; the causal factor which reflects deceptive patterns in a certain scenario, and non-causal noise. By eliminating the noise that causes bias, we can use invariant and causal factors to build a robust model with good generalization ability. Experiments on three popular datasets show the effectiveness of our approach.
VideoQA in the Era of LLMs: An Empirical Study
Aug 08, 2024



Video Large Language Models (Video-LLMs) are flourishing and has advanced many video-language tasks. As a golden testbed, Video Question Answering (VideoQA) plays pivotal role in Video-LLM developing. This work conducts a timely and comprehensive study of Video-LLMs' behavior in VideoQA, aiming to elucidate their success and failure modes, and provide insights towards more human-like video understanding and question answering. Our analyses demonstrate that Video-LLMs excel in VideoQA; they can correlate contextual cues and generate plausible responses to questions about varied video contents. However, models falter in handling video temporality, both in reasoning about temporal content ordering and grounding QA-relevant temporal moments. Moreover, the models behave unintuitively - they are unresponsive to adversarial video perturbations while being sensitive to simple variations of candidate answers and questions. Also, they do not necessarily generalize better. The findings demonstrate Video-LLMs' QA capability in standard condition yet highlight their severe deficiency in robustness and interpretability, suggesting the urgent need on rationales in Video-LLM developing.