 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Contaminated Datasets to Learn Clean-Data Distribution with Purified Generative Adversarial Networks
Paper and Code



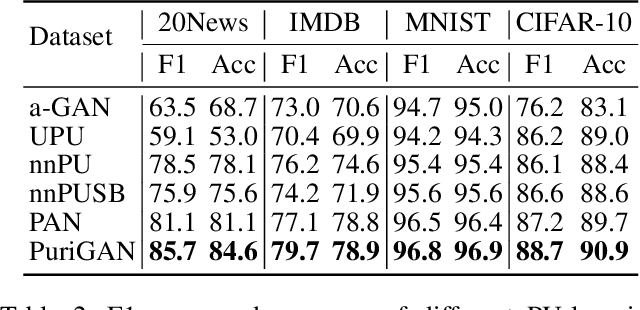
Generative adversarial networks (GANs) are known for their strong abilities on capturing the underlying distribution of training instances. Since the seminal work of GAN, many variants of GAN have been proposed. However, existing GANs are almost established on the assumption that the training dataset is clean. But in many real-world applications, this may not hold, that is, the training dataset may be contaminated by a proportion of undesired instances. When training on such datasets, existing GANs will learn a mixture distribution of desired and contaminated instances, rather than the desired distribution of desired data only (target distribution). To learn the target distribution from contaminated datasets, two purified generative adversarial networks (PuriGAN) are developed, in which the discriminators are augmented with the capability to distinguish between target and contaminated instances by leveraging an extra dataset solely composed of contamination instances. We prove that under some mild conditions, the proposed PuriGANs are guaranteed to converge to the distribution of desired instances. Experimental results on several datasets demonstrate that the proposed PuriGANs are able to generate much better images from the desired distribution than comparable baselines when trained on contaminated datasets. In addition, we also demonstrate the usefulness of PuriGAN on downstream applications by applying it to the tasks of semi-supervised anomaly detection on contaminated datasets and PU-learning. Experimental results show that PuriGAN is able to deliver the best performance over comparable baselines on both tasks.