 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
Jun 02, 2026Reward models (RMs) provide critical feedback signals for LLM post-training, notably in reinforced fine-tuning (RFT) and reinforcement learning (RL) pipelines. However, current reward evaluation relies on heterogeneous criteria such as rule-based verifiers, ground-truth references, procedural checklists, and complex rubrics, where a unified mechanism to integrate all types of evidence remains unexplored. To this end, we propose Skill Reward Model (Skill-RM), a unified framework that reformulates reward modeling as the execution of a reusable Reward-Evaluation Skill. By treating reward computation as a structured agentic task, Skill-RM provides a consistent interface to orchestrate heterogeneous resources, dynamically selecting and aggregating evidence tailored to the specific requirements of each input. This approach enables the reward model to move beyond static evaluation, ensuring consistency and transparency across diverse tasks. Extensive experiments on reward benchmarks and downstream applications, including best-of-N selection and reinforcement learning, demonstrate that Skill-RM consistently outperforms traditional judge baselines. Our findings suggest that Skill-RM not only provides a unified solution for reward modeling but also achieves superior performance through the strategic and dynamic orchestration of evidence. The code is at https://github.com/Qwen-Applications/Skill-RM.
Deploying Foundation Model Powered Agent Services: A Survey
Dec 18, 2024



Foundation model (FM) powered agent services are regarded as a promising solution to develop intelligent and personalized applications for advancing toward Artificial General Intelligence (AGI). To achieve high reliability and scalability in deploying these agent services, it is essential to collaboratively optimize computational and communication resources, thereby ensuring effective resource allocation and seamless service delivery. In pursuit of this vision, this paper proposes a unified framework aimed at providing a comprehensive survey on deploying FM-based agent services across heterogeneous devices, with the emphasis on the integration of model and resource optimization to establish a robust infrastructure for these services. Particularly, this paper begins with exploring various low-level optimization strategies during inference and studies approaches that enhance system scalability, such as parallelism techniques and resource scaling methods. The paper then discusses several prominent FMs and investigates research efforts focused on inference acceleration, including techniques such as model compression and token reduction. Moreover, the paper also investigates critical components for constructing agent services and highlights notable intelligent applications. Finally, the paper presents potential research directions for developing real-time agent services with high Quality of Service (QoS).
Detecting Emotional Incongruity of Sarcasm by Commonsense Reasoning
Dec 17, 2024This paper focuses on sarcasm detection, which aims to identify whether given statements convey criticism, mockery, or other negative sentiment opposite to the literal meaning. To detect sarcasm, humans often require a comprehensive understanding of the semantics in the statement and even resort to external commonsense to infer the fine-grained incongruity. However, existing methods lack commonsense inferential ability when they face complex real-world scenarios, leading to unsatisfactory performance. To address this problem, we propose a novel framework for sarcasm detection, which conducts incongruity reasoning based on commonsense augmentation, called EICR. Concretely, we first employ retrieval-augmented large language models to supplement the missing but indispensable commonsense background knowledge. To capture complex contextual associations, we construct a dependency graph and obtain the optimized topology via graph refinement. We further introduce an adaptive reasoning skeleton that integrates prior rules to extract sentiment-inconsistent subgraphs explicitly. To eliminate the possible spurious relations between words and labels, we employ adversarial contrastive learning to enhance the robustness of the detector. Experiments conducted on five datasets demonstrate the effectiveness of EICR.
Boosting Fine-Grained Visual Anomaly Detection with Coarse-Knowledge-Aware Adversarial Learning
Dec 17, 2024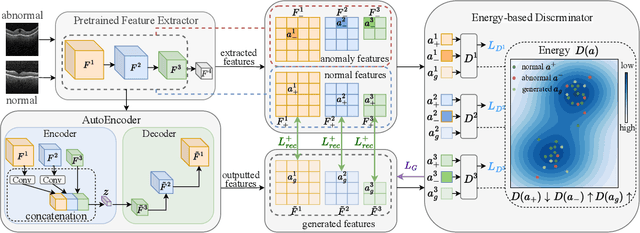
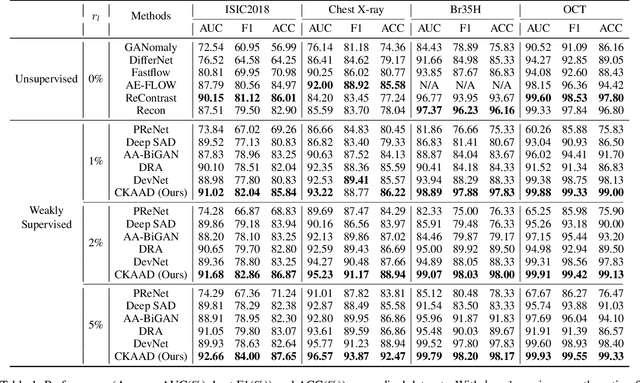
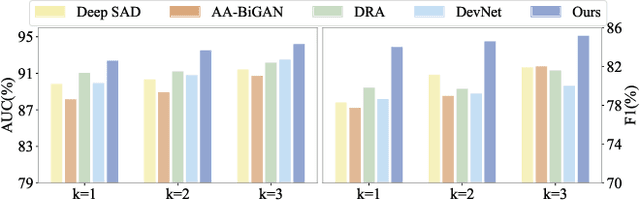

Many unsupervised visual anomaly detection methods train an auto-encoder to reconstruct normal samples and then leverage the reconstruction error map to detect and localize the anomalies. However, due to the powerful modeling and generalization ability of neural networks, some anomalies can also be well reconstructed, resulting in unsatisfactory detection and localization accuracy. In this paper, a small coarsely-labeled anomaly dataset is first collected. Then, a coarse-knowledge-aware adversarial learning method is developed to align the distribution of reconstructed features with that of normal features. The alignment can effectively suppress the auto-encoder's reconstruction ability on anomalies and thus improve the detection accuracy. Considering that anomalies often only occupy very small areas in anomalous images, a patch-level adversarial learning strategy is further developed. Although no patch-level anomalous information is available, we rigorously prove that by simply viewing any patch features from anomalous images as anomalies, the proposed knowledge-aware method can also align the distribution of reconstructed patch features with the normal ones. Experimental results on four medical datasets and two industrial datasets demonstrate the effectiveness of our method in improving the detection and localization performance.
AnomalySD: Few-Shot Multi-Class Anomaly Detection with Stable Diffusion Model
Aug 04, 2024



Anomaly detection is a critical task in industrial manufacturing, aiming to identify defective parts of products. Most industrial anomaly detection methods assume the availability of sufficient normal data for training. This assumption may not hold true due to the cost of labeling or data privacy policies. Additionally, mainstream methods require training bespoke models for different objects, which incurs heavy costs and lacks flexibility in practice. To address these issues, we seek help from Stable Diffusion (SD) model due to its capability of zero/few-shot inpainting, which can be leveraged to inpaint anomalous regions as normal. In this paper, a few-shot multi-class anomaly detection framework that adopts Stable Diffusion model is proposed, named AnomalySD. To adapt SD to anomaly detection task, we design different hierarchical text descriptions and the foreground mask mechanism for fine-tuning SD. In the inference stage, to accurately mask anomalous regions for inpainting, we propose multi-scale mask strategy and prototype-guided mask strategy to handle diverse anomalous regions. Hierarchical text prompts are also utilized to guide the process of inpainting in the inference stage. The anomaly score is estimated based on inpainting result of all masks. Extensive experiments on the MVTec-AD and VisA datasets demonstrate the superiority of our approach. We achieved anomaly classification and segmentation results of 93.6%/94.8% AUROC on the MVTec-AD dataset and 86.1%/96.5% AUROC on the VisA dataset under multi-class and one-shot settings.
Learning Summary-Worthy Visual Representation for Abstractive Summarization in Video
May 08, 2023Multimodal abstractive summarization for videos (MAS) requires generating a concise textual summary to describe the highlights of a video according to multimodal resources, in our case, the video content and its transcript. Inspired by the success of the large-scale generative pre-trained language model (GPLM) in generating high-quality textual content (e.g., summary), recent MAS methods have proposed to adapt the GPLM to this task by equipping it with the visual information, which is often obtained through a general-purpose visual feature extractor. However, the generally extracted visual features may overlook some summary-worthy visual information, which impedes model performance. In this work, we propose a novel approach to learning the summary-worthy visual representation that facilitates abstractive summarization. Our method exploits the summary-worthy information from both the cross-modal transcript data and the knowledge that distills from the pseudo summary. Extensive experiments on three public multimodal datasets show that our method outperforms all competing baselines. Furthermore, with the advantages of summary-worthy visual information, our model can have a significant improvement on small datasets or even datasets with limited training data.
Leveraging Contaminated Datasets to Learn Clean-Data Distribution with Purified Generative Adversarial Networks
Feb 03, 2023


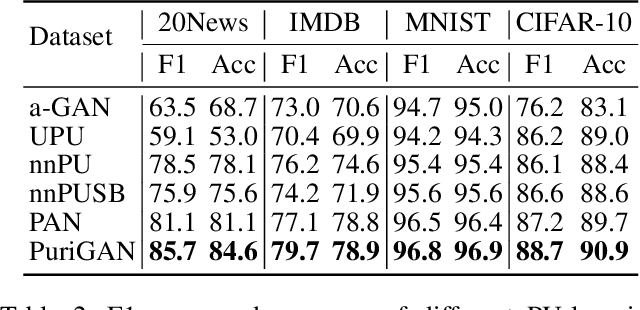
Generative adversarial networks (GANs) are known for their strong abilities on capturing the underlying distribution of training instances. Since the seminal work of GAN, many variants of GAN have been proposed. However, existing GANs are almost established on the assumption that the training dataset is clean. But in many real-world applications, this may not hold, that is, the training dataset may be contaminated by a proportion of undesired instances. When training on such datasets, existing GANs will learn a mixture distribution of desired and contaminated instances, rather than the desired distribution of desired data only (target distribution). To learn the target distribution from contaminated datasets, two purified generative adversarial networks (PuriGAN) are developed, in which the discriminators are augmented with the capability to distinguish between target and contaminated instances by leveraging an extra dataset solely composed of contamination instances. We prove that under some mild conditions, the proposed PuriGANs are guaranteed to converge to the distribution of desired instances. Experimental results on several datasets demonstrate that the proposed PuriGANs are able to generate much better images from the desired distribution than comparable baselines when trained on contaminated datasets. In addition, we also demonstrate the usefulness of PuriGAN on downstream applications by applying it to the tasks of semi-supervised anomaly detection on contaminated datasets and PU-learning. Experimental results show that PuriGAN is able to deliver the best performance over comparable baselines on both tasks.
Efficient Document Retrieval by End-to-End Refining and Quantizing BERT Embedding with Contrastive Product Quantization
Oct 31, 2022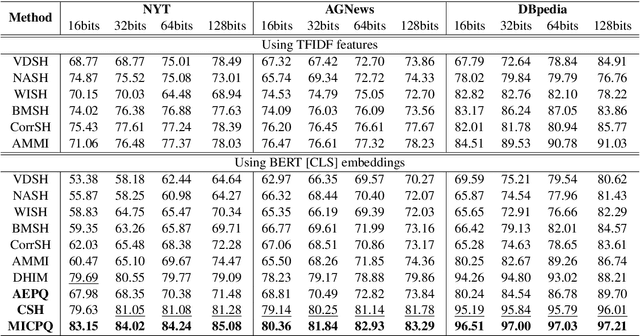
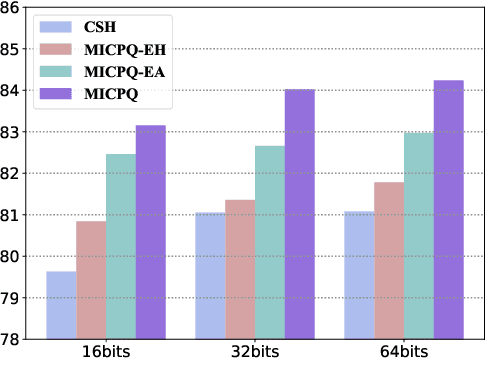
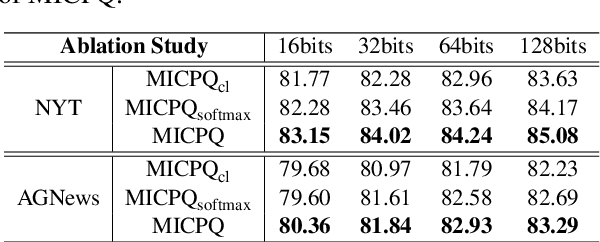
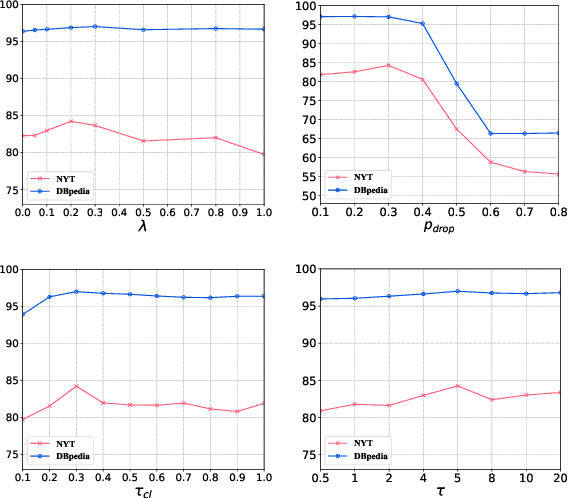
Efficient document retrieval heavily relies on the technique of semantic hashing, which learns a binary code for every document and employs Hamming distance to evaluate document distances. However, existing semantic hashing methods are mostly established on outdated TFIDF features, which obviously do not contain lots of important semantic information about documents. Furthermore, the Hamming distance can only be equal to one of several integer values, significantly limiting its representational ability for document distances. To address these issues, in this paper, we propose to leverage BERT embeddings to perform efficient retrieval based on the product quantization technique, which will assign for every document a real-valued codeword from the codebook, instead of a binary code as in semantic hashing. Specifically, we first transform the original BERT embeddings via a learnable mapping and feed the transformed embedding into a probabilistic product quantization module to output the assigned codeword. The refining and quantizing modules can be optimized in an end-to-end manner by minimizing the probabilistic contrastive loss. A mutual information maximization based method is further proposed to improve the representativeness of codewords, so that documents can be quantized more accurately. Extensive experiments conducted on three benchmarks demonstrate that our proposed method significantly outperforms current state-of-the-art baselines.
Federated Non-negative Matrix Factorization for Short Texts Topic Modeling with Mutual Information
May 26, 2022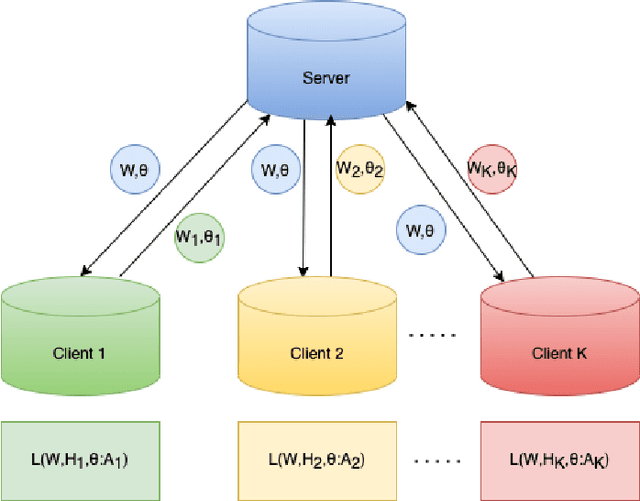
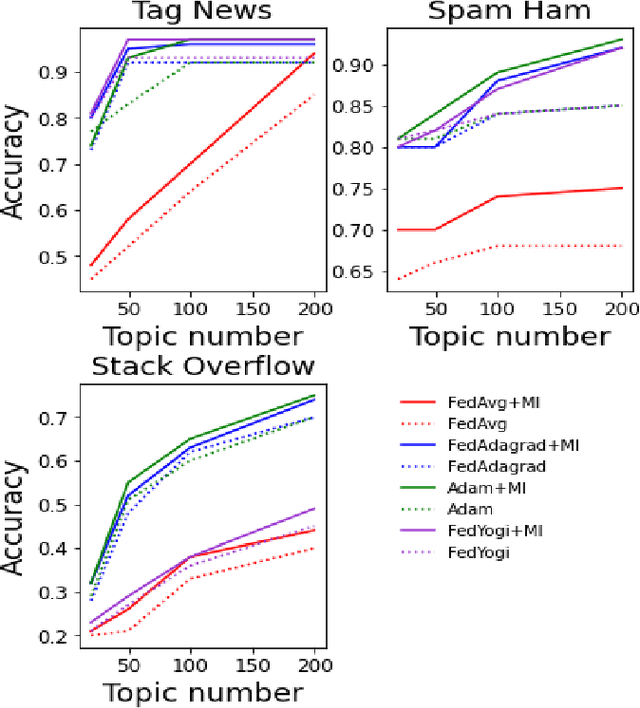
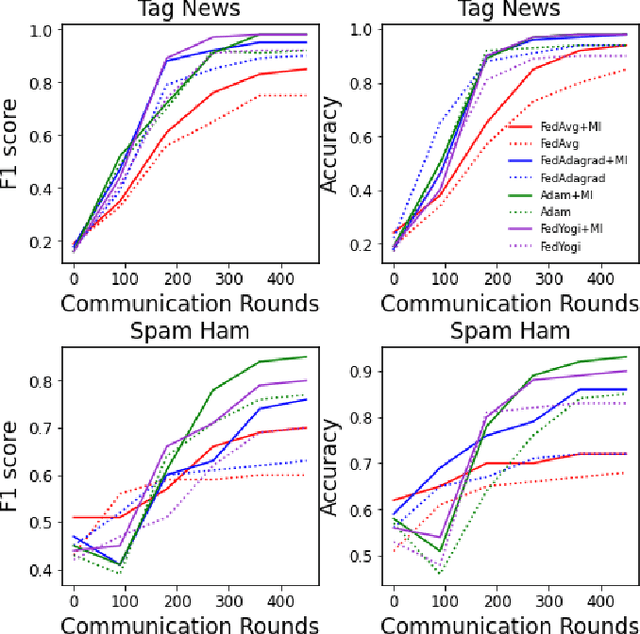
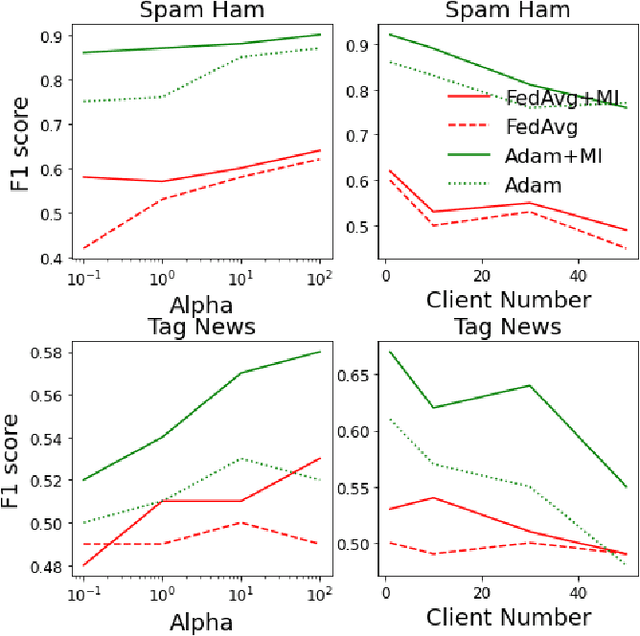
Non-negative matrix factorization (NMF) based topic modeling is widely used in natural language processing (NLP) to uncover hidden topics of short text documents. Usually, training a high-quality topic model requires large amount of textual data. In many real-world scenarios, customer textual data should be private and sensitive, precluding uploading to data centers. This paper proposes a Federated NMF (FedNMF) framework, which allows multiple clients to collaboratively train a high-quality NMF based topic model with locally stored data. However, standard federated learning will significantly undermine the performance of topic models in downstream tasks (e.g., text classification) when the data distribution over clients is heterogeneous. To alleviate this issue, we further propose FedNMF+MI, which simultaneously maximizes the mutual information (MI) between the count features of local texts and their topic weight vectors to mitigate the performance degradation. Experimental results show that our FedNMF+MI methods outperform Federated Latent Dirichlet Allocation (FedLDA) and the FedNMF without MI methods for short texts by a significant margin on both coherence score and classification F1 score.
* 7 pages, 4 figures, accepted by IJCNN 2022
Modeling Semantic Composition with Syntactic Hypergraph for Video Question Answering
May 13, 2022
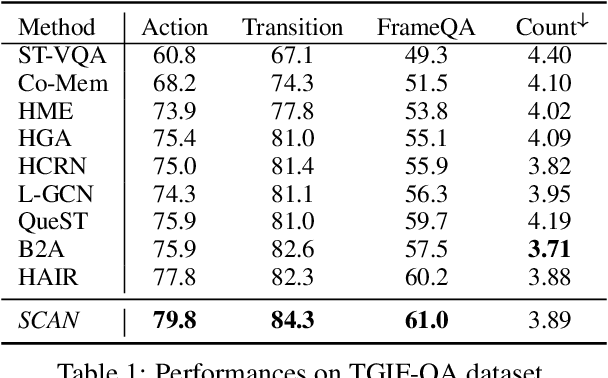
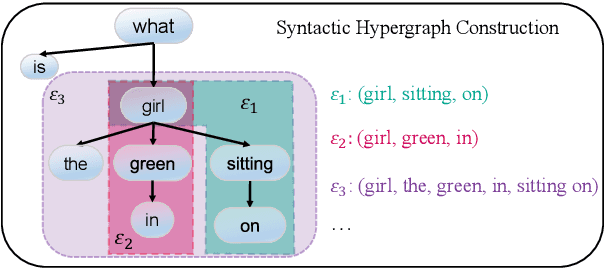
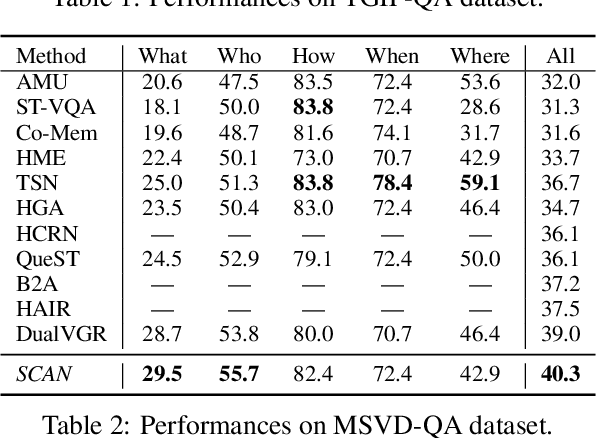
A key challenge in video question answering is how to realize the cross-modal semantic alignment between textual concepts and corresponding visual objects. Existing methods mostly seek to align the word representations with the video regions. However, word representations are often not able to convey a complete description of textual concepts, which are in general described by the compositions of certain words. To address this issue, we propose to first build a syntactic dependency tree for each question with an off-the-shelf tool and use it to guide the extraction of meaningful word compositions. Based on the extracted compositions, a hypergraph is further built by viewing the words as nodes and the compositions as hyperedges. Hypergraph convolutional networks (HCN) are then employed to learn the initial representations of word compositions. Afterwards, an optimal transport based method is proposed to perform cross-modal semantic alignment for the textual and visual semantic space. To reflect the cross-modal influences, the cross-modal information is incorporated into the initial representations, leading to a model named cross-modality-aware syntactic HCN. Experimental results on three benchmarks show that our method outperforms all strong baselines. Further analyses demonstrate the effectiveness of each component, and show that our model is good at modeling different levels of semantic compositions and filtering out irrelevant information.