 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTIS: Agentic Risk-Aware Test-Time Scaling via Iterative Simulation
Feb 03, 2026Current test-time scaling (TTS) techniques enhance large language model (LLM) performance by allocating additional computation at inference time, yet they remain insufficient for agentic settings, where actions directly interact with external environments and their effects can be irreversible and costly. We propose ARTIS, Agentic Risk-Aware Test-Time Scaling via Iterative Simulation, a framework that decouples exploration from commitment by enabling test-time exploration through simulated interactions prior to real-world execution. This design allows extending inference-time computation to improve action-level reliability and robustness without incurring environmental risk. We further show that naive LLM-based simulators struggle to capture rare but high-impact failure modes, substantially limiting their effectiveness for agentic decision making. To address this limitation, we introduce a risk-aware tool simulator that emphasizes fidelity on failure-inducing actions via targeted data generation and rebalanced training. Experiments on multi-turn and multi-step agentic benchmarks demonstrate that iterative simulation substantially improves agent reliability, and that risk-aware simulation is essential for consistently realizing these gains across models and tasks.
Teaching Large Reasoning Models Effective Reflection
Jan 19, 2026Large Reasoning Models (LRMs) have recently shown impressive performance on complex reasoning tasks, often by engaging in self-reflective behaviors such as self-critique and backtracking. However, not all reflections are beneficial-many are superficial, offering little to no improvement over the original answer and incurring computation overhead. In this paper, we identify and address the problem of superficial reflection in LRMs. We first propose Self-Critique Fine-Tuning (SCFT), a training framework that enhances the model's reflective reasoning ability using only self-generated critiques. SCFT prompts models to critique their own outputs, filters high-quality critiques through rejection sampling, and fine-tunes the model using a critique-based objective. Building on this strong foundation, we further introduce Reinforcement Learning with Effective Reflection Rewards (RLERR). RLERR leverages the high-quality reflections initialized by SCFT to construct reward signals, guiding the model to internalize the self-correction process via reinforcement learning. Experiments on two challenging benchmarks, AIME2024 and AIME2025, show that SCFT and RLERR significantly improve both reasoning accuracy and reflection quality, outperforming state-of-the-art baselines. All data and codes are available at https://github.com/wanghanbinpanda/SCFT.
Fast, Slow, and Tool-augmented Thinking for LLMs: A Review
Aug 17, 2025Large Language Models (LLMs) have demonstrated remarkable progress in reasoning across diverse domains. However, effective reasoning in real-world tasks requires adapting the reasoning strategy to the demands of the problem, ranging from fast, intuitive responses to deliberate, step-by-step reasoning and tool-augmented thinking. Drawing inspiration from cognitive psychology, we propose a novel taxonomy of LLM reasoning strategies along two knowledge boundaries: a fast/slow boundary separating intuitive from deliberative processes, and an internal/external boundary distinguishing reasoning grounded in the model's parameters from reasoning augmented by external tools. We systematically survey recent work on adaptive reasoning in LLMs and categorize methods based on key decision factors. We conclude by highlighting open challenges and future directions toward more adaptive, efficient, and reliable LLMs.
QFFT, Question-Free Fine-Tuning for Adaptive Reasoning
Jun 15, 2025

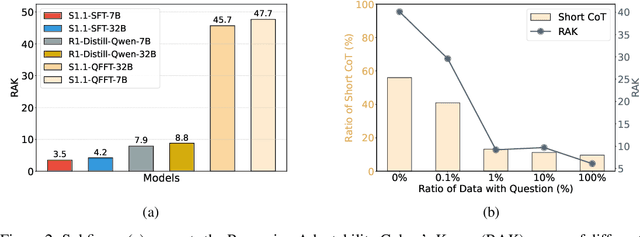

Recent advancements in Long Chain-of-Thought (CoT) reasoning models have improved performance on complex tasks, but they suffer from overthinking, which generates redundant reasoning steps, especially for simple questions. This paper revisits the reasoning patterns of Long and Short CoT models, observing that the Short CoT patterns offer concise reasoning efficiently, while the Long CoT patterns excel in challenging scenarios where the Short CoT patterns struggle. To enable models to leverage both patterns, we propose Question-Free Fine-Tuning (QFFT), a fine-tuning approach that removes the input question during training and learns exclusively from Long CoT responses. This approach enables the model to adaptively employ both reasoning patterns: it prioritizes the Short CoT patterns and activates the Long CoT patterns only when necessary. Experiments on various mathematical datasets demonstrate that QFFT reduces average response length by more than 50\%, while achieving performance comparable to Supervised Fine-Tuning (SFT). Additionally, QFFT exhibits superior performance compared to SFT in noisy, out-of-domain, and low-resource scenarios.
Humanity's Last Code Exam: Can Advanced LLMs Conquer Human's Hardest Code Competition?
Jun 15, 2025Code generation is a core capability of large language models (LLMs), yet mainstream benchmarks (e.g., APPs and LiveCodeBench) contain questions with medium-level difficulty and pose no challenge to advanced LLMs. To better reflected the advanced reasoning and code generation ability, We introduce Humanity's Last Code Exam (HLCE), comprising 235 most challenging problems from the International Collegiate Programming Contest (ICPC World Finals) and the International Olympiad in Informatics (IOI) spanning 2010 - 2024. As part of HLCE, we design a harmonized online-offline sandbox that guarantees fully reproducible evaluation. Through our comprehensive evaluation, we observe that even the strongest reasoning LLMs: o4-mini(high) and Gemini-2.5 Pro, achieve pass@1 rates of only 15.9% and 11.4%, respectively. Meanwhile, we propose a novel "self-recognition" task to measure LLMs' awareness of their own capabilities. Results indicate that LLMs' self-recognition abilities are not proportionally correlated with their code generation performance. Finally, our empirical validation of test-time scaling laws reveals that current advanced LLMs have substantial room for improvement on complex programming tasks. We expect HLCE to become a milestone challenge for code generation and to catalyze advances in high-performance reasoning and human-AI collaborative programming. Our code and dataset are also public available(https://github.com/Humanity-s-Last-Code-Exam/HLCE).
Safe: Enhancing Mathematical Reasoning in Large Language Models via Retrospective Step-aware Formal Verification
Jun 05, 2025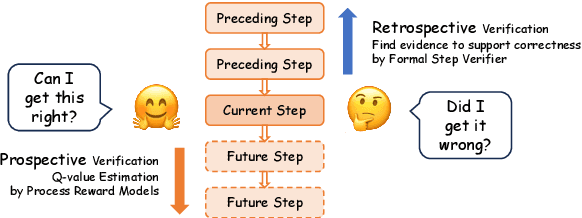



Chain-of-Thought (CoT) prompting has become the de facto method to elicit reasoning capabilities from large language models (LLMs). However, to mitigate hallucinations in CoT that are notoriously difficult to detect, current methods such as process reward models (PRMs) or self-consistency operate as opaque boxes and do not provide checkable evidence for their judgments, possibly limiting their effectiveness. To address this issue, we draw inspiration from the idea that "the gold standard for supporting a mathematical claim is to provide a proof". We propose a retrospective, step-aware formal verification framework $Safe$. Rather than assigning arbitrary scores, we strive to articulate mathematical claims in formal mathematical language Lean 4 at each reasoning step and provide formal proofs to identify hallucinations. We evaluate our framework $Safe$ across multiple language models and various mathematical datasets, demonstrating a significant performance improvement while offering interpretable and verifiable evidence. We also propose $FormalStep$ as a benchmark for step correctness theorem proving with $30,809$ formal statements. To the best of our knowledge, our work represents the first endeavor to utilize formal mathematical language Lean 4 for verifying natural language content generated by LLMs, aligning with the reason why formal mathematical languages were created in the first place: to provide a robust foundation for hallucination-prone human-written proofs.
Pangu DeepDiver: Adaptive Search Intensity Scaling via Open-Web Reinforcement Learning
May 30, 2025Information seeking demands iterative evidence gathering and reflective reasoning, yet large language models (LLMs) still struggle with it in open-web question answering. Existing methods rely on static prompting rules or training with Wikipedia-based corpora and retrieval environments, limiting adaptability to the real-world web environment where ambiguity, conflicting evidence, and noise are prevalent. These constrained training settings hinder LLMs from learning to dynamically decide when and where to search, and how to adjust search depth and frequency based on informational demands. We define this missing capacity as Search Intensity Scaling (SIS)--the emergent skill to intensify search efforts under ambiguous or conflicting conditions, rather than settling on overconfident, under-verification answers. To study SIS, we introduce WebPuzzle, the first dataset designed to foster information-seeking behavior in open-world internet environments. WebPuzzle consists of 24K training instances and 275 test questions spanning both wiki-based and open-web queries. Building on this dataset, we propose DeepDiver, a Reinforcement Learning (RL) framework that promotes SIS by encouraging adaptive search policies through exploration under a real-world open-web environment. Experimental results show that Pangu-7B-Reasoner empowered by DeepDiver achieve performance on real-web tasks comparable to the 671B-parameter DeepSeek-R1. We detail DeepDiver's training curriculum from cold-start supervised fine-tuning to a carefully designed RL phase, and present that its capability of SIS generalizes from closed-form QA to open-ended tasks such as long-form writing. Our contributions advance adaptive information seeking in LLMs and provide a valuable benchmark and dataset for future research.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025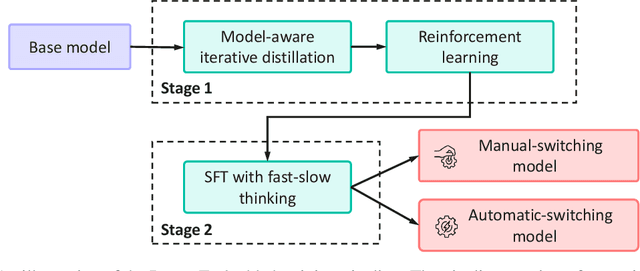

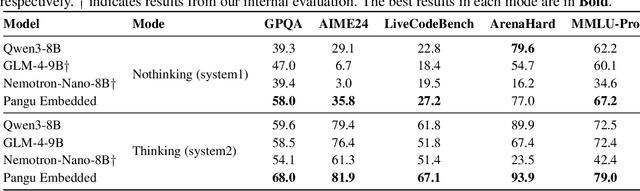
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025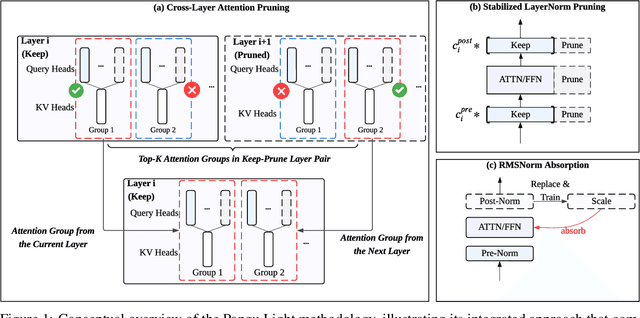

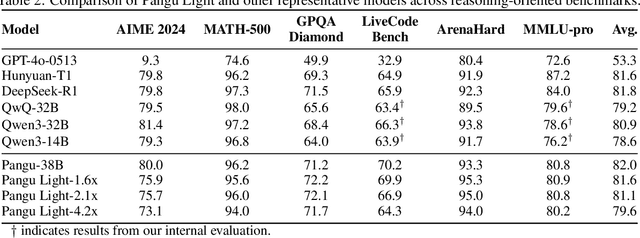
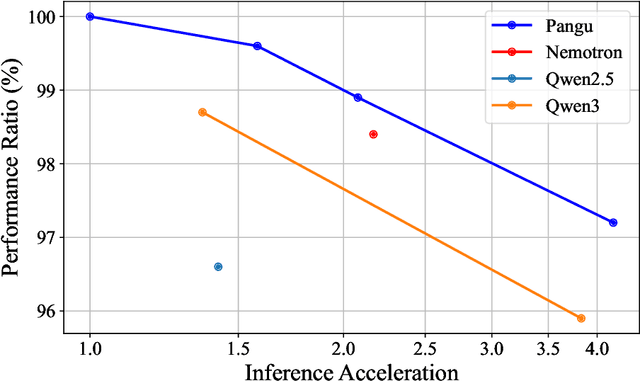
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.