 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTIS: Agentic Risk-Aware Test-Time Scaling via Iterative Simulation
Feb 03, 2026Current test-time scaling (TTS) techniques enhance large language model (LLM) performance by allocating additional computation at inference time, yet they remain insufficient for agentic settings, where actions directly interact with external environments and their effects can be irreversible and costly. We propose ARTIS, Agentic Risk-Aware Test-Time Scaling via Iterative Simulation, a framework that decouples exploration from commitment by enabling test-time exploration through simulated interactions prior to real-world execution. This design allows extending inference-time computation to improve action-level reliability and robustness without incurring environmental risk. We further show that naive LLM-based simulators struggle to capture rare but high-impact failure modes, substantially limiting their effectiveness for agentic decision making. To address this limitation, we introduce a risk-aware tool simulator that emphasizes fidelity on failure-inducing actions via targeted data generation and rebalanced training. Experiments on multi-turn and multi-step agentic benchmarks demonstrate that iterative simulation substantially improves agent reliability, and that risk-aware simulation is essential for consistently realizing these gains across models and tasks.
CoMaPOI: A Collaborative Multi-Agent Framework for Next POI Prediction Bridging the Gap Between Trajectory and Language
May 28, 2025
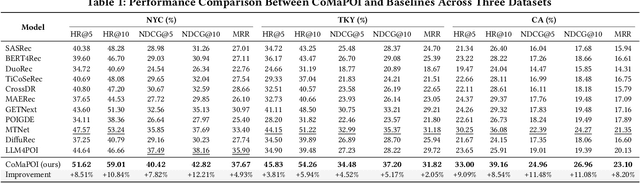
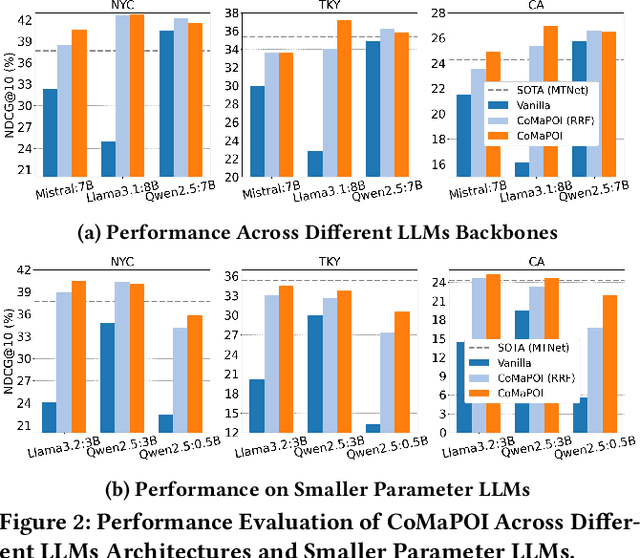
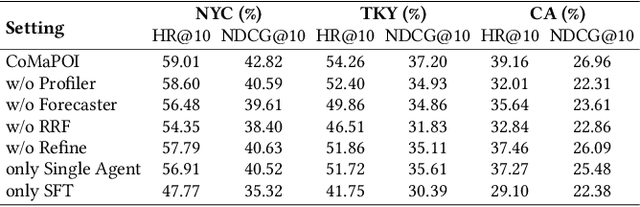
Large Language Models (LLMs) offer new opportunities for the next Point-Of-Interest (POI) prediction task, leveraging their capabilities in semantic understanding of POI trajectories. However, previous LLM-based methods, which are superficially adapted to next POI prediction, largely overlook critical challenges associated with applying LLMs to this task. Specifically, LLMs encounter two critical challenges: (1) a lack of intrinsic understanding of numeric spatiotemporal data, which hinders accurate modeling of users' spatiotemporal distributions and preferences; and (2) an excessively large and unconstrained candidate POI space, which often results in random or irrelevant predictions. To address these issues, we propose a Collaborative Multi Agent Framework for Next POI Prediction, named CoMaPOI. Through the close interaction of three specialized agents (Profiler, Forecaster, and Predictor), CoMaPOI collaboratively addresses the two critical challenges. The Profiler agent is responsible for converting numeric data into language descriptions, enhancing semantic understanding. The Forecaster agent focuses on dynamically constraining and refining the candidate POI space. The Predictor agent integrates this information to generate high-precision predictions. Extensive experiments on three benchmark datasets (NYC, TKY, and CA) demonstrate that CoMaPOI achieves state of the art performance, improving all metrics by 5% to 10% compared to SOTA baselines. This work pioneers the investigation of challenges associated with applying LLMs to complex spatiotemporal tasks by leveraging tailored collaborative agents.
Enhancing Knowledge Graph Completion with GNN Distillation and Probabilistic Interaction Modeling
May 18, 2025Knowledge graphs (KGs) serve as fundamental structures for organizing interconnected data across diverse domains. However, most KGs remain incomplete, limiting their effectiveness in downstream applications. Knowledge graph completion (KGC) aims to address this issue by inferring missing links, but existing methods face critical challenges: deep graph neural networks (GNNs) suffer from over-smoothing, while embedding-based models fail to capture abstract relational features. This study aims to overcome these limitations by proposing a unified framework that integrates GNN distillation and abstract probabilistic interaction modeling (APIM). GNN distillation approach introduces an iterative message-feature filtering process to mitigate over-smoothing, preserving the discriminative power of node representations. APIM module complements this by learning structured, abstract interaction patterns through probabilistic signatures and transition matrices, allowing for a richer, more flexible representation of entity and relation interactions. We apply these methods to GNN-based models and the APIM to embedding-based KGC models, conducting extensive evaluations on the widely used WN18RR and FB15K-237 datasets. Our results demonstrate significant performance gains over baseline models, showcasing the effectiveness of the proposed techniques. The findings highlight the importance of both controlling information propagation and leveraging structured probabilistic modeling, offering new avenues for advancing knowledge graph completion. And our codes are available at https://anonymous.4open.science/r/APIM_and_GNN-Distillation-461C.
ToolACE-R: Tool Learning with Adaptive Self-Refinement
Apr 02, 2025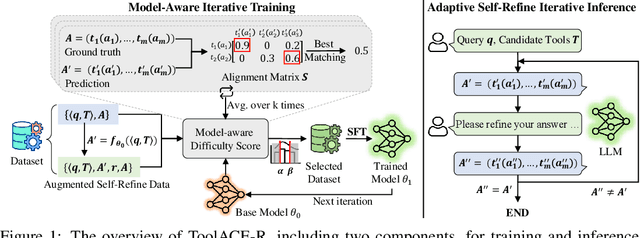
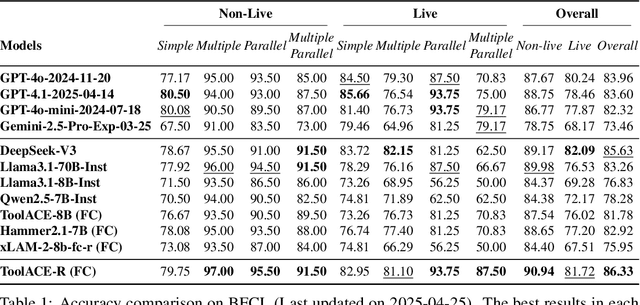
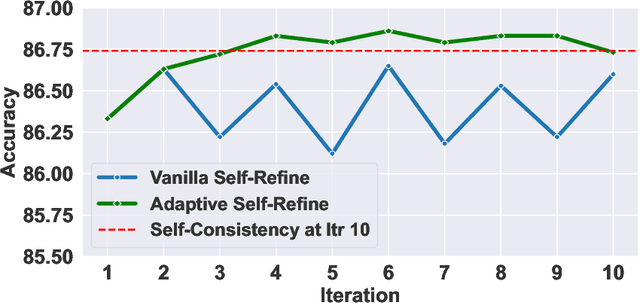

Tool learning, which allows Large Language Models (LLMs) to leverage external tools for solving complex user tasks, has emerged as a promising avenue for extending model capabilities. However, current approaches primarily focus on data synthesis for fine-tuning LLMs to invoke tools effectively, largely ignoring how to fully stimulate the potential of the model. In this paper, we propose ToolACE-R, a novel method that introduces adaptive self-refinement for tool invocations. Our approach features a model-aware iterative training procedure that progressively incorporates more training samples based on the model's evolving capabilities. Additionally, it allows LLMs to iteratively refine their tool calls, optimizing performance without requiring external feedback. To further enhance computational efficiency, we integrate an adaptive mechanism when scaling the inference time, enabling the model to autonomously determine when to stop the refinement process. We conduct extensive experiments across several benchmark datasets, showing that ToolACE-R achieves competitive performance compared to advanced API-based models, even without any refinement. Furthermore, its performance can be further improved efficiently through adaptive self-refinement. Our results demonstrate the effectiveness of the proposed method, which is compatible with base models of various sizes, offering a promising direction for more efficient tool learning.
Deep Sparse Latent Feature Models for Knowledge Graph Completion
Nov 24, 2024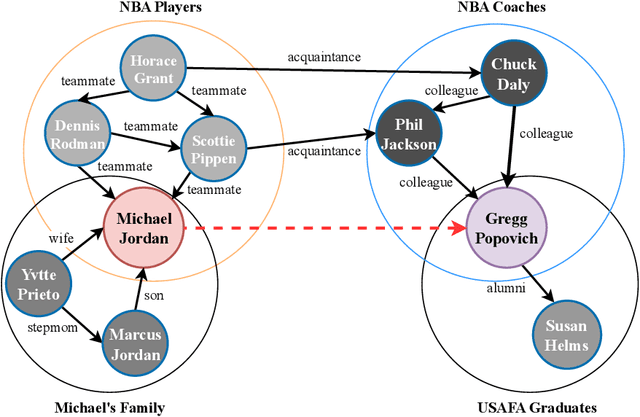

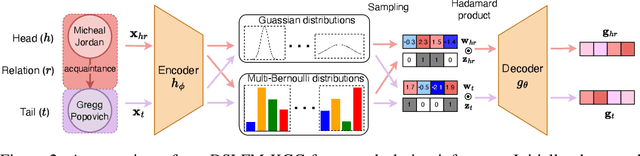

Recent progress in knowledge graph completion (KGC) has focused on text-based approaches to address the challenges of large-scale knowledge graphs (KGs). Despite their achievements, these methods often overlook the intricate interconnections between entities, a key aspect of the underlying topological structure of a KG. Stochastic blockmodels (SBMs), particularly the latent feature relational model (LFRM), offer robust probabilistic frameworks that can dynamically capture latent community structures and enhance link prediction. In this paper, we introduce a novel framework of sparse latent feature models for KGC, optimized through a deep variational autoencoder (VAE). Our approach not only effectively completes missing triples but also provides clear interpretability of the latent structures, leveraging textual information. Comprehensive experiments on the WN18RR, FB15k-237, and Wikidata5M datasets show that our method significantly improves performance by revealing latent communities and producing interpretable representations.
Selective Forgetting: Advancing Machine Unlearning Techniques and Evaluation in Language Models
Feb 08, 2024



The aim of this study is to investigate Machine Unlearning (MU), a burgeoning field focused on addressing concerns related to neural models inadvertently retaining personal or sensitive data. Here, a novel approach is introduced to achieve precise and selective forgetting within language models. Unlike previous methodologies that adopt completely opposing training objectives, this approach aims to mitigate adverse effects on language model performance, particularly in generation tasks. Furthermore, two innovative evaluation metrics are proposed: Sensitive Information Extraction Likelihood (S-EL) and Sensitive Information Memory Accuracy (S-MA), designed to gauge the effectiveness of sensitive information elimination. To reinforce the forgetting framework, an effective method for annotating sensitive scopes is presented, involving both online and offline strategies. The online selection mechanism leverages language probability scores to ensure computational efficiency, while the offline annotation entails a robust two-stage process based on Large Language Models (LLMs).
IndiVec: An Exploration of Leveraging Large Language Models for Media Bias Detection with Fine-Grained Bias Indicators
Feb 01, 2024



This study focuses on media bias detection, crucial in today's era of influential social media platforms shaping individual attitudes and opinions. In contrast to prior work that primarily relies on training specific models tailored to particular datasets, resulting in limited adaptability and subpar performance on out-of-domain data, we introduce a general bias detection framework, IndiVec, built upon large language models. IndiVec begins by constructing a fine-grained media bias database, leveraging the robust instruction-following capabilities of large language models and vector database techniques. When confronted with new input for bias detection, our framework automatically selects the most relevant indicator from the vector database and employs majority voting to determine the input's bias label. IndiVec excels compared to previous methods due to its adaptability (demonstrating consistent performance across diverse datasets from various sources) and explainability (providing explicit top-k indicators to interpret bias predictions). Experimental results on four political bias datasets highlight IndiVec's significant superiority over baselines. Furthermore, additional experiments and analysis provide profound insights into the framework's effectiveness.
A Survey of the Evolution of Language Model-Based Dialogue Systems
Nov 28, 2023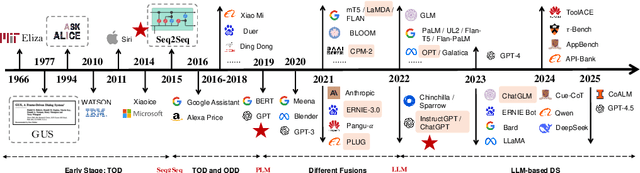



Dialogue systems, including task-oriented_dialogue_system (TOD) and open-domain_dialogue_system (ODD), have undergone significant transformations, with language_models (LM) playing a central role. This survey delves into the historical trajectory of dialogue systems, elucidating their intricate relationship with advancements in language models by categorizing this evolution into four distinct stages, each marked by pivotal LM breakthroughs: 1) Early_Stage: characterized by statistical LMs, resulting in rule-based or machine-learning-driven dialogue_systems; 2) Independent development of TOD and ODD based on neural_language_models (NLM; e.g., LSTM and GRU), since NLMs lack intrinsic knowledge in their parameters; 3) fusion between different types of dialogue systems with the advert of pre-trained_language_models (PLMs), starting from the fusion between four_sub-tasks_within_TOD, and then TOD_with_ODD; and 4) current LLM-based_dialogue_system, wherein LLMs can be used to conduct TOD and ODD seamlessly. Thus, our survey provides a chronological perspective aligned with LM breakthroughs, offering a comprehensive review of state-of-the-art research outcomes. What's more, we focus on emerging topics and discuss open challenges, providing valuable insights into future directions for LLM-based_dialogue_systems. Through this exploration, we pave the way for a deeper_comprehension of the evolution, guiding future developments in LM-based dialogue_systems.
TPE: Towards Better Compositional Reasoning over Conceptual Tools with Multi-persona Collaboration
Sep 28, 2023Large language models (LLMs) have demonstrated exceptional performance in planning the use of various functional tools, such as calculators and retrievers, particularly in question-answering tasks. In this paper, we expand the definition of these tools, centering on conceptual tools within the context of dialogue systems. A conceptual tool specifies a cognitive concept that aids systematic or investigative thought. These conceptual tools play important roles in practice, such as multiple psychological or tutoring strategies being dynamically applied in a single turn to compose helpful responses. To further enhance the reasoning and planning capability of LLMs with these conceptual tools, we introduce a multi-persona collaboration framework: Think-Plan-Execute (TPE). This framework decouples the response generation process into three distinct roles: Thinker, Planner, and Executor. Specifically, the Thinker analyzes the internal status exhibited in the dialogue context, such as user emotions and preferences, to formulate a global guideline. The Planner then generates executable plans to call different conceptual tools (e.g., sources or strategies), while the Executor compiles all intermediate results into a coherent response. This structured approach not only enhances the explainability and controllability of responses but also reduces token redundancy. We demonstrate the effectiveness of TPE across various dialogue response generation tasks, including multi-source (FoCus) and multi-strategy interactions (CIMA and PsyQA). This reveals its potential to handle real-world dialogue interactions that require more complicated tool learning beyond just functional tools. The full code and data will be released for reproduction.
KERMIT: Knowledge Graph Completion of Enhanced Relation Modeling with Inverse Transformation
Sep 26, 2023



Knowledge graph completion is a task that revolves around filling in missing triples based on the information available in a knowledge graph. Among the current studies, text-based methods complete the task by utilizing textual descriptions of triples. However, this modeling approach may encounter limitations, particularly when the description fails to accurately and adequately express the intended meaning. To overcome these challenges, we propose the augmentation of data through two additional mechanisms. Firstly, we employ ChatGPT as an external knowledge base to generate coherent descriptions to bridge the semantic gap between the queries and answers. Secondly, we leverage inverse relations to create a symmetric graph, thereby creating extra labeling and providing supplementary information for link prediction. This approach offers additional insights into the relationships between entities. Through these efforts, we have observed significant improvements in knowledge graph completion, as these mechanisms enhance the richness and diversity of the available data, leading to more accurate results.