 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Sparse Latent Feature Models for Knowledge Graph Completion
Nov 24, 2024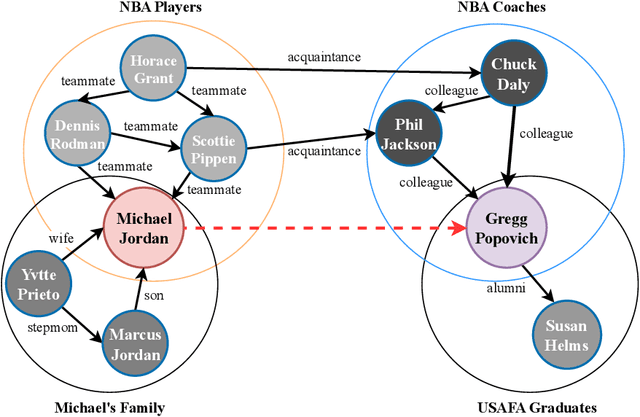

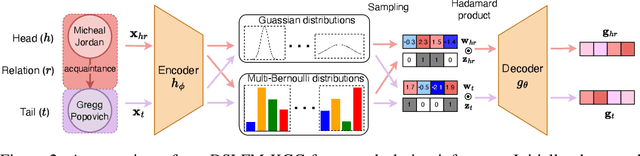

Recent progress in knowledge graph completion (KGC) has focused on text-based approaches to address the challenges of large-scale knowledge graphs (KGs). Despite their achievements, these methods often overlook the intricate interconnections between entities, a key aspect of the underlying topological structure of a KG. Stochastic blockmodels (SBMs), particularly the latent feature relational model (LFRM), offer robust probabilistic frameworks that can dynamically capture latent community structures and enhance link prediction. In this paper, we introduce a novel framework of sparse latent feature models for KGC, optimized through a deep variational autoencoder (VAE). Our approach not only effectively completes missing triples but also provides clear interpretability of the latent structures, leveraging textual information. Comprehensive experiments on the WN18RR, FB15k-237, and Wikidata5M datasets show that our method significantly improves performance by revealing latent communities and producing interpretable representations.
TsCA: On the Semantic Consistency Alignment via Conditional Transport for Compositional Zero-Shot Learning
Aug 16, 2024



Compositional Zero-Shot Learning (CZSL) aims to recognize novel \textit{state-object} compositions by leveraging the shared knowledge of their primitive components. Despite considerable progress, effectively calibrating the bias between semantically similar multimodal representations, as well as generalizing pre-trained knowledge to novel compositional contexts, remains an enduring challenge. In this paper, our interest is to revisit the conditional transport (CT) theory and its homology to the visual-semantics interaction in CZSL and further, propose a novel Trisets Consistency Alignment framework (dubbed TsCA) that well-addresses these issues. Concretely, we utilize three distinct yet semantically homologous sets, i.e., patches, primitives, and compositions, to construct pairwise CT costs to minimize their semantic discrepancies. To further ensure the consistency transfer within these sets, we implement a cycle-consistency constraint that refines the learning by guaranteeing the feature consistency of the self-mapping during transport flow, regardless of modality. Moreover, we extend the CT plans to an open-world setting, which enables the model to effectively filter out unfeasible pairs, thereby speeding up the inference as well as increasing the accuracy. Extensive experiments are conducted to verify the effectiveness of the proposed method.
KERMIT: Knowledge Graph Completion of Enhanced Relation Modeling with Inverse Transformation
Sep 26, 2023



Knowledge graph completion is a task that revolves around filling in missing triples based on the information available in a knowledge graph. Among the current studies, text-based methods complete the task by utilizing textual descriptions of triples. However, this modeling approach may encounter limitations, particularly when the description fails to accurately and adequately express the intended meaning. To overcome these challenges, we propose the augmentation of data through two additional mechanisms. Firstly, we employ ChatGPT as an external knowledge base to generate coherent descriptions to bridge the semantic gap between the queries and answers. Secondly, we leverage inverse relations to create a symmetric graph, thereby creating extra labeling and providing supplementary information for link prediction. This approach offers additional insights into the relationships between entities. Through these efforts, we have observed significant improvements in knowledge graph completion, as these mechanisms enhance the richness and diversity of the available data, leading to more accurate results.
A variational autoencoder-based nonnegative matrix factorisation model for deep dictionary learning
Jan 18, 2023



Construction of dictionaries using nonnegative matrix factorisation (NMF) has extensive applications in signal processing and machine learning. With the advances in deep learning, training compact and robust dictionaries using deep neural networks, i.e., dictionaries of deep features, has been proposed. In this study, we propose a probabilistic generative model which employs a variational autoencoder (VAE) to perform nonnegative dictionary learning. In contrast to the existing VAE models, we cast the model under a statistical framework with latent variables obeying a Gamma distribution and design a new loss function to guarantee the nonnegative dictionaries. We adopt an acceptance-rejection sampling reparameterization trick to update the latent variables iteratively. We apply the dictionaries learned from VAE-NMF to two signal processing tasks, i.e., enhancement of speech and extraction of muscle synergies. Experimental results demonstrate that VAE-NMF performs better in learning the latent nonnegative dictionaries in comparison with state-of-the-art methods.
Free Lunch for Generating Effective Outlier Supervision
Jan 17, 2023
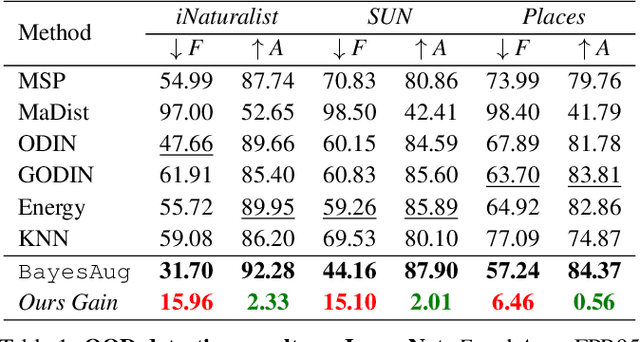
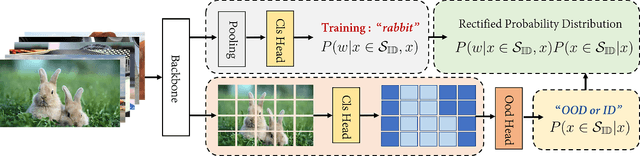
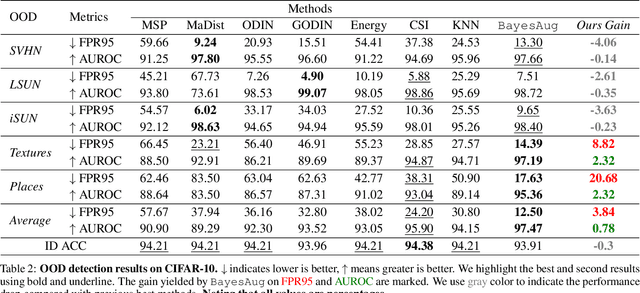
When deployed in practical applications, computer vision systems will encounter numerous unexpected images (\emph{{i.e.}}, out-of-distribution data). Due to the potentially raised safety risks, these aforementioned unseen data should be carefully identified and handled. Generally, existing approaches in dealing with out-of-distribution (OOD) detection mainly focus on the statistical difference between the features of OOD and in-distribution (ID) data extracted by the classifiers. Although many of these schemes have brought considerable performance improvements, reducing the false positive rate (FPR) when processing open-set images, they necessarily lack reliable theoretical analysis and generalization guarantees. Unlike the observed ways, in this paper, we investigate the OOD detection problem based on the Bayes rule and present a convincing description of the reason for failures encountered by conventional classifiers. Concretely, our analysis reveals that refining the probability distribution yielded by the vanilla neural networks is necessary for OOD detection, alleviating the issues of assigning high confidence to OOD data. To achieve this effortlessly, we propose an ultra-effective method to generate near-realistic outlier supervision. Extensive experiments on large-scale benchmarks reveal that our proposed \texttt{BayesAug} significantly reduces the FPR95 over 12.50\% compared with the previous schemes, boosting the reliability of machine learning systems. The code will be made publicly available.
Demystify Optimization and Generalization of Over-parameterized PAC-Bayesian Learning
Feb 04, 2022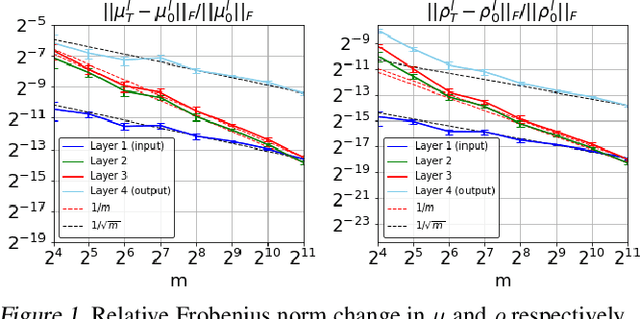
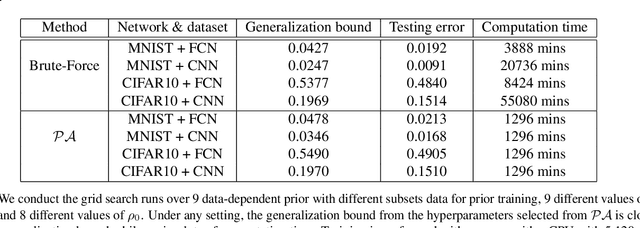
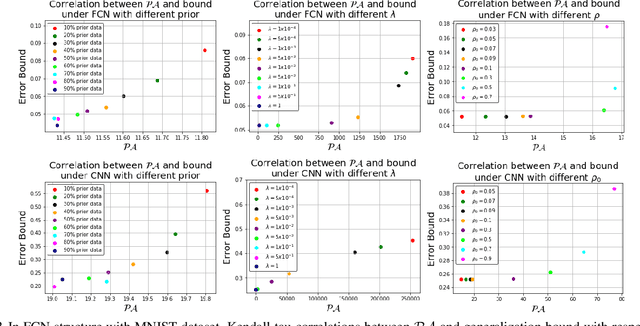
PAC-Bayesian is an analysis framework where the training error can be expressed as the weighted average of the hypotheses in the posterior distribution whilst incorporating the prior knowledge. In addition to being a pure generalization bound analysis tool, PAC-Bayesian bound can also be incorporated into an objective function to train a probabilistic neural network, making them a powerful and relevant framework that can numerically provide a tight generalization bound for supervised learning. For simplicity, we call probabilistic neural network learned using training objectives derived from PAC-Bayesian bounds as {\it PAC-Bayesian learning}. Despite their empirical success, the theoretical analysis of PAC-Bayesian learning for neural networks is rarely explored. This paper proposes a new class of convergence and generalization analysis for PAC-Bayes learning when it is used to train the over-parameterized neural networks by the gradient descent method. For a wide probabilistic neural network, we show that when PAC-Bayes learning is applied, the convergence result corresponds to solving a kernel ridge regression when the probabilistic neural tangent kernel (PNTK) is used as its kernel. Based on this finding, we further characterize the uniform PAC-Bayesian generalization bound which improves over the Rademacher complexity-based bound for non-probabilistic neural network. Finally, drawing the insight from our theoretical results, we propose a proxy measure for efficient hyperparameters selection, which is proven to be time-saving.
Regularize! Don't Mix: Multi-Agent Reinforcement Learning without Explicit Centralized Structures
Sep 19, 2021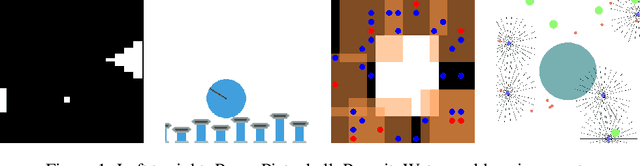

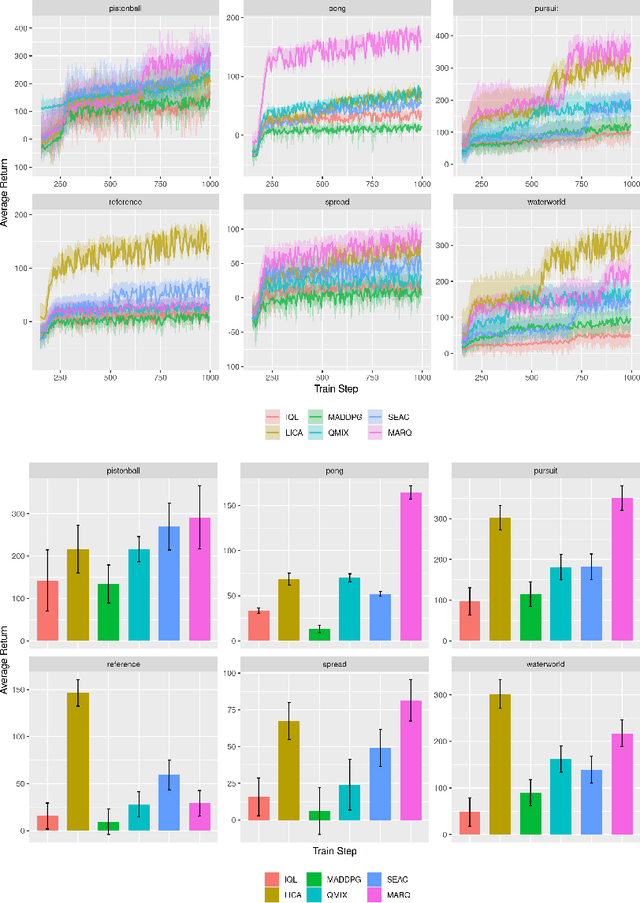
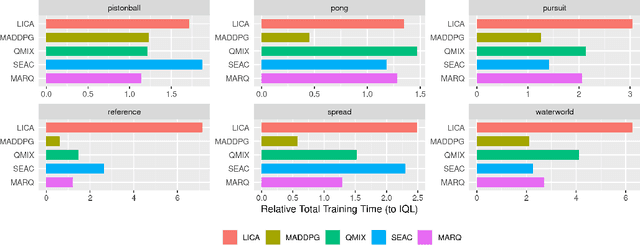
We propose using regularization for Multi-Agent Reinforcement Learning rather than learning explicit cooperative structures called {\em Multi-Agent Regularized Q-learning} (MARQ). Many MARL approaches leverage centralized structures in order to exploit global state information or removing communication constraints when the agents act in a decentralized manner. Instead of learning redundant structures which is removed during agent execution, we propose instead to leverage shared experiences of the agents to regularize the individual policies in order to promote structured exploration. We examine several different approaches to how MARQ can either explicitly or implicitly regularize our policies in a multi-agent setting. MARQ aims to address these limitations in the MARL context through applying regularization constraints which can correct bias in off-policy out-of-distribution agent experiences and promote diverse exploration. Our algorithm is evaluated on several benchmark multi-agent environments and we show that MARQ consistently outperforms several baselines and state-of-the-art algorithms; learning in fewer steps and converging to higher returns.
Dual Behavior Regularized Reinforcement Learning
Sep 19, 2021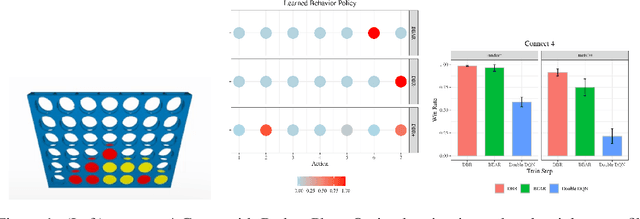
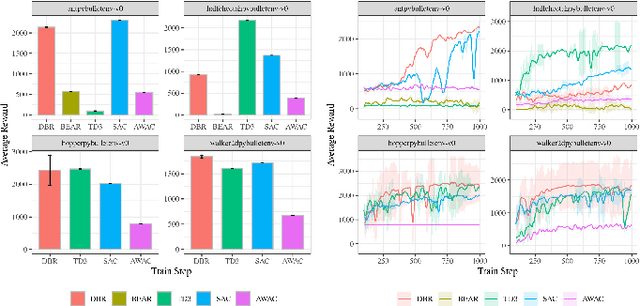
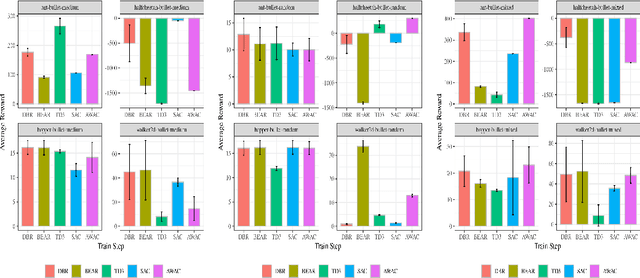
Reinforcement learning has been shown to perform a range of complex tasks through interaction with an environment or collected leveraging experience. However, many of these approaches presume optimal or near optimal experiences or the presence of a consistent environment. In this work we propose dual, advantage-based behavior policy based on counterfactual regret minimization. We demonstrate the flexibility of this approach and how it can be adapted to online contexts where the environment is available to collect experiences and a variety of other contexts. We demonstrate this new algorithm can outperform several strong baseline models in different contexts based on a range of continuous environments. Additional ablations provide insights into how our dual behavior regularized reinforcement learning approach is designed compared with other plausible modifications and demonstrates its ability to generalize.
Greedy UnMixing for Q-Learning in Multi-Agent Reinforcement Learning
Sep 19, 2021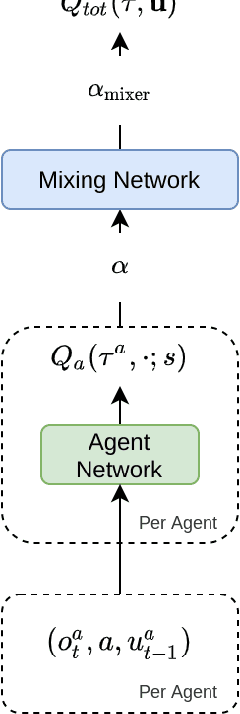

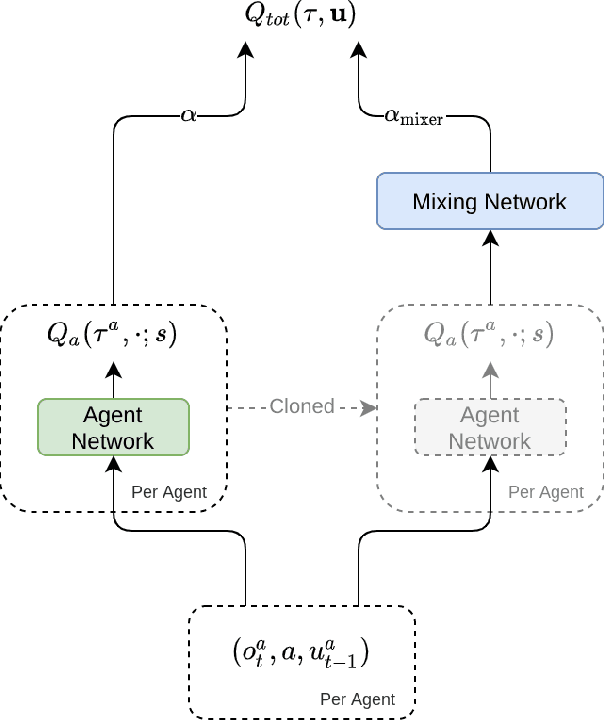
This paper introduces Greedy UnMix (GUM) for cooperative multi-agent reinforcement learning (MARL). Greedy UnMix aims to avoid scenarios where MARL methods fail due to overestimation of values as part of the large joint state-action space. It aims to address this through a conservative Q-learning approach through restricting the state-marginal in the dataset to avoid unobserved joint state action spaces, whilst concurrently attempting to unmix or simplify the problem space under the centralized training with decentralized execution paradigm. We demonstrate the adherence to Q-function lower bounds in the Q-learning for MARL scenarios, and demonstrate superior performance to existing Q-learning MARL approaches as well as more general MARL algorithms over a set of benchmark MARL tasks, despite its relative simplicity compared with state-of-the-art approaches.
Alleviating Mode Collapse in GAN via Diversity Penalty Module
Aug 24, 2021

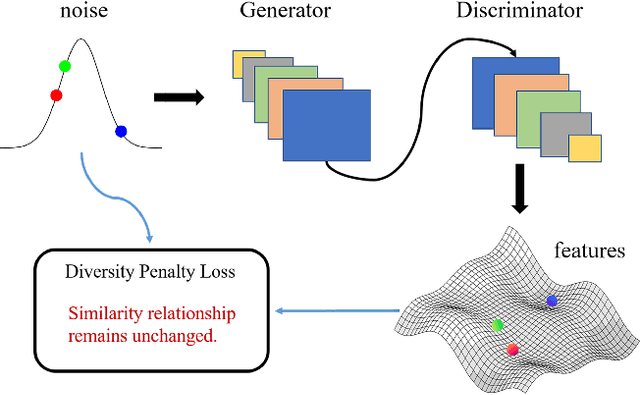

The vanilla GAN (Goodfellow et al. 2014) suffers from mode collapse deeply, which usually manifests as that the images generated by generators tend to have a high similarity amongst them, even though their corresponding latent vectors have been very different. In this paper, we introduce a pluggable diversity penalty module (DPM) to alleviate mode collapse of GANs. It reduces the similarity of image pairs in feature space, i.e., if two latent vectors are different, then we enforce the generator to generate two images with different features. The normalized Gram matrix is used to measure the similarity. We compare the proposed method with Unrolled GAN (Metz et al. 2016), BourGAN (Xiao, Zhong, and Zheng 2018), PacGAN (Lin et al. 2018), VEEGAN (Srivastava et al. 2017) and ALI (Dumoulin et al. 2016) on 2D synthetic dataset, and results show that the diversity penalty module can help GAN capture much more modes of the data distribution. Further, in classification tasks, we apply this method as image data augmentation on MNIST, Fashion- MNIST and CIFAR-10, and the classification testing accuracy is improved by 0.24%, 1.34% and 0.52% compared with WGAN GP (Gulrajani et al. 2017), respectively. In domain translation, diversity penalty module can help StarGAN (Choi et al. 2018) generate more accurate attention masks and accelarate the convergence process. Finally, we quantitatively evaluate the proposed method with IS and FID on CelebA, CIFAR-10, MNIST and Fashion-MNIST, and the results suggest GAN with diversity penalty module gets much higher IS and lower FID compared with some SOTA GAN architectures.