 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA variational autoencoder-based nonnegative matrix factorisation model for deep dictionary learning
Jan 18, 2023



Construction of dictionaries using nonnegative matrix factorisation (NMF) has extensive applications in signal processing and machine learning. With the advances in deep learning, training compact and robust dictionaries using deep neural networks, i.e., dictionaries of deep features, has been proposed. In this study, we propose a probabilistic generative model which employs a variational autoencoder (VAE) to perform nonnegative dictionary learning. In contrast to the existing VAE models, we cast the model under a statistical framework with latent variables obeying a Gamma distribution and design a new loss function to guarantee the nonnegative dictionaries. We adopt an acceptance-rejection sampling reparameterization trick to update the latent variables iteratively. We apply the dictionaries learned from VAE-NMF to two signal processing tasks, i.e., enhancement of speech and extraction of muscle synergies. Experimental results demonstrate that VAE-NMF performs better in learning the latent nonnegative dictionaries in comparison with state-of-the-art methods.
Scalable Deep Generative Relational Models with High-Order Node Dependence
Nov 04, 2019



We propose a probabilistic framework for modelling and exploring the latent structure of relational data. Given feature information for the nodes in a network, the scalable deep generative relational model (SDREM) builds a deep network architecture that can approximate potential nonlinear mappings between nodes' feature information and the nodes' latent representations. Our contribution is two-fold: (1) We incorporate high-order neighbourhood structure information to generate the latent representations at each node, which vary smoothly over the network. (2) Due to the Dirichlet random variable structure of the latent representations, we introduce a novel data augmentation trick which permits efficient Gibbs sampling. The SDREM can be used for large sparse networks as its computational cost scales with the number of positive links. We demonstrate its competitive performance through improved link prediction performance on a range of real-world datasets.
Comment on "Clustering by fast search and find of density peaks"
Jan 20, 2015
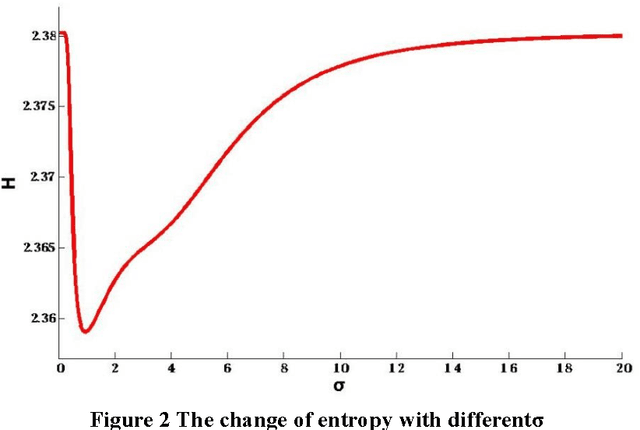

In [1], a clustering algorithm was given to find the centers of clusters quickly. However, the accuracy of this algorithm heavily depend on the threshold value of d-c. Furthermore, [1] has not provided any efficient way to select the threshold value of d-c, that is, one can have to estimate the value of d_c depend on one's subjective experience. In this paper, based on the data field [2], we propose a new way to automatically extract the threshold value of d_c from the original data set by using the potential entropy of data field. For any data set to be clustered, the most reasonable value of d_c can be objectively calculated from the data set by using our proposed method. The same experiments in [1] are redone with our proposed method on the same experimental data set used in [1], the results of which shows that the problem to calculate the threshold value of d_c in [1] has been solved by using our method.