 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Knowledge-enhanced Spatio-temporal Epidemic Forecasting
Feb 25, 2026Spatio-temporal epidemic forecasting is critical for public health management, yet existing methods often struggle with insensitivity to weak epidemic signals, over-simplified spatial relations, and unstable parameter estimation. To address these challenges, we propose the Spatio-Temporal priOr-aware Epidemic Predictor (STOEP), a novel hybrid framework that integrates implicit spatio-temporal priors and explicit expert priors. STOEP consists of three key components: (1) Case-aware Adjacency Learning (CAL), which dynamically adjusts mobility-based regional dependencies using historical infection patterns; (2) Space-informed Parameter Estimating (SPE), which employs learnable spatial priors to amplify weak epidemic signals; and (3) Filter-based Mechanistic Forecasting (FMF), which uses an expert-guided adaptive thresholding strategy to regularize epidemic parameters. Extensive experiments on real-world COVID-19 and influenza datasets demonstrate that STOEP outperforms the best baseline by 11.1% in RMSE. The system has been deployed at one provincial CDC in China to facilitate downstream applications.
Meta Dynamic Graph for Traffic Flow Prediction
Jan 15, 2026Traffic flow prediction is a typical spatio-temporal prediction problem and has a wide range of applications. The core challenge lies in modeling the underlying complex spatio-temporal dependencies. Various methods have been proposed, and recent studies show that the modeling of dynamics is useful to meet the core challenge. While handling spatial dependencies and temporal dependencies using separate base model structures may hinder the modeling of spatio-temporal correlations, the modeling of dynamics can bridge this gap. Incorporating spatio-temporal heterogeneity also advances the main goal, since it can extend the parameter space and allow more flexibility. Despite these advances, two limitations persist: 1) the modeling of dynamics is often limited to the dynamics of spatial topology (e.g., adjacency matrix changes), which, however, can be extended to a broader scope; 2) the modeling of heterogeneity is often separated for spatial and temporal dimensions, but this gap can also be bridged by the modeling of dynamics. To address the above limitations, we propose a novel framework for traffic prediction, called Meta Dynamic Graph (MetaDG). MetaDG leverages dynamic graph structures of node representations to explicitly model spatio-temporal dynamics. This generates both dynamic adjacency matrices and meta-parameters, extending dynamic modeling beyond topology while unifying the capture of spatio-temporal heterogeneity into a single dimension. Extensive experiments on four real-world datasets validate the effectiveness of MetaDG.
Detecting outliers by clustering algorithms
Dec 07, 2024



Clustering and outlier detection are two important tasks in data mining. Outliers frequently interfere with clustering algorithms to determine the similarity between objects, resulting in unreliable clustering results. Currently, only a few clustering algorithms (e.g., DBSCAN) have the ability to detect outliers to eliminate interference. For other clustering algorithms, it is tedious to introduce another outlier detection task to eliminate outliers before each clustering process. Obviously, how to equip more clustering algorithms with outlier detection ability is very meaningful. Although a common strategy allows clustering algorithms to detect outliers based on the distance between objects and clusters, it is contradictory to improving the performance of clustering algorithms on the datasets with outliers. In this paper, we propose a novel outlier detection approach, called ODAR, for clustering. ODAR maps outliers and normal objects into two separated clusters by feature transformation. As a result, any clustering algorithm can detect outliers by identifying clusters. Experiments show that ODAR is robust to diverse datasets. Compared with baseline methods, the clustering algorithms achieve the best on 7 out of 10 datasets with the help of ODAR, with at least 5% improvement in accuracy.
SIG: Efficient Self-Interpretable Graph Neural Network for Continuous-time Dynamic Graphs
May 29, 2024
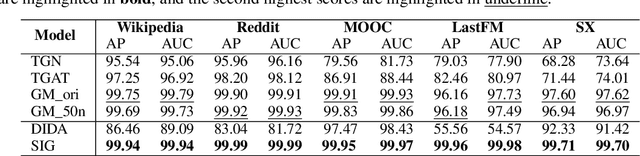
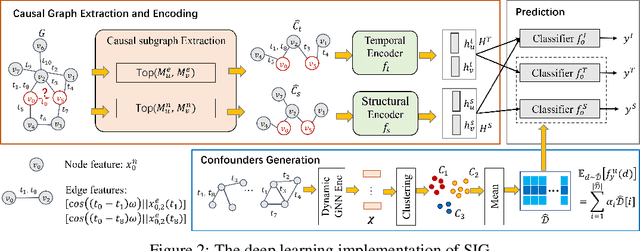

While dynamic graph neural networks have shown promise in various applications, explaining their predictions on continuous-time dynamic graphs (CTDGs) is difficult. This paper investigates a new research task: self-interpretable GNNs for CTDGs. We aim to predict future links within the dynamic graph while simultaneously providing causal explanations for these predictions. There are two key challenges: (1) capturing the underlying structural and temporal information that remains consistent across both independent and identically distributed (IID) and out-of-distribution (OOD) data, and (2) efficiently generating high-quality link prediction results and explanations. To tackle these challenges, we propose a novel causal inference model, namely the Independent and Confounded Causal Model (ICCM). ICCM is then integrated into a deep learning architecture that considers both effectiveness and efficiency. Extensive experiments demonstrate that our proposed model significantly outperforms existing methods across link prediction accuracy, explanation quality, and robustness to shortcut features. Our code and datasets are anonymously released at https://github.com/2024SIG/SIG.
A parameter-free clustering algorithm for missing datasets
Apr 08, 2024



Missing datasets, in which some objects have missing values in certain dimensions, are prevalent in the Real-world. Existing clustering algorithms for missing datasets first impute the missing values and then perform clustering. However, both the imputation and clustering processes require input parameters. Too many input parameters inevitably increase the difficulty of obtaining accurate clustering results. Although some studies have shown that decision graphs can replace the input parameters of clustering algorithms, current decision graphs require equivalent dimensions among objects and are therefore not suitable for missing datasets. To this end, we propose a Single-Dimensional Clustering algorithm, i.e., SDC. SDC, which removes the imputation process and adapts the decision graph to the missing datasets by splitting dimension and partition intersection fusion, can obtain valid clustering results on the missing datasets without input parameters. Experiments demonstrate that, across three evaluation metrics, SDC outperforms baseline algorithms by at least 13.7%(NMI), 23.8%(ARI), and 8.1%(Purity).
A variational autoencoder-based nonnegative matrix factorisation model for deep dictionary learning
Jan 18, 2023



Construction of dictionaries using nonnegative matrix factorisation (NMF) has extensive applications in signal processing and machine learning. With the advances in deep learning, training compact and robust dictionaries using deep neural networks, i.e., dictionaries of deep features, has been proposed. In this study, we propose a probabilistic generative model which employs a variational autoencoder (VAE) to perform nonnegative dictionary learning. In contrast to the existing VAE models, we cast the model under a statistical framework with latent variables obeying a Gamma distribution and design a new loss function to guarantee the nonnegative dictionaries. We adopt an acceptance-rejection sampling reparameterization trick to update the latent variables iteratively. We apply the dictionaries learned from VAE-NMF to two signal processing tasks, i.e., enhancement of speech and extraction of muscle synergies. Experimental results demonstrate that VAE-NMF performs better in learning the latent nonnegative dictionaries in comparison with state-of-the-art methods.
Position-enhanced and Time-aware Graph Convolutional Network for Sequential Recommendations
Jul 12, 2021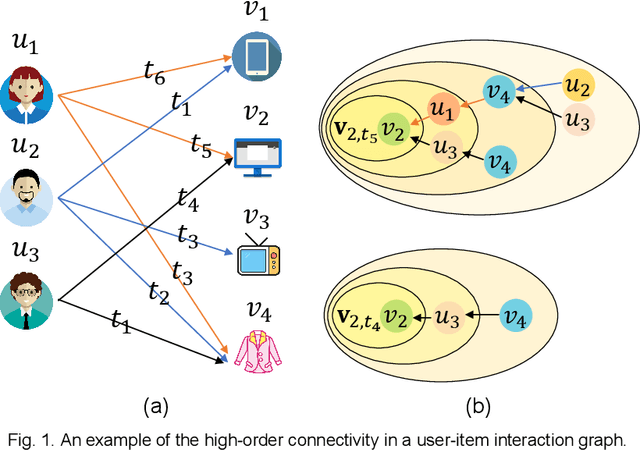

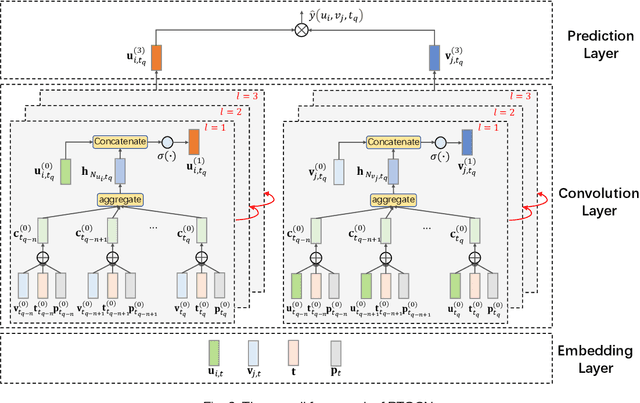

Most of the existing deep learning-based sequential recommendation approaches utilize the recurrent neural network architecture or self-attention to model the sequential patterns and temporal influence among a user's historical behavior and learn the user's preference at a specific time. However, these methods have two main drawbacks. First, they focus on modeling users' dynamic states from a user-centric perspective and always neglect the dynamics of items over time. Second, most of them deal with only the first-order user-item interactions and do not consider the high-order connectivity between users and items, which has recently been proved helpful for the sequential recommendation. To address the above problems, in this article, we attempt to model user-item interactions by a bipartite graph structure and propose a new recommendation approach based on a Position-enhanced and Time-aware Graph Convolutional Network (PTGCN) for the sequential recommendation. PTGCN models the sequential patterns and temporal dynamics between user-item interactions by defining a position-enhanced and time-aware graph convolution operation and learning the dynamic representations of users and items simultaneously on the bipartite graph with a self-attention aggregator. Also, it realizes the high-order connectivity between users and items by stacking multi-layer graph convolutions. To demonstrate the effectiveness of PTGCN, we carried out a comprehensive evaluation of PTGCN on three real-world datasets of different sizes compared with a few competitive baselines. Experimental results indicate that PTGCN outperforms several state-of-the-art models in terms of two commonly-used evaluation metrics for ranking.
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
Apr 02, 2020



Occluded person re-identification (ReID) aims to match occluded person images to holistic ones across dis-joint cameras. In this paper, we propose a novel framework by learning high-order relation and topology information for discriminative features and robust alignment. At first, we use a CNN backbone and a key-points estimation model to extract semantic local features. Even so, occluded images still suffer from occlusion and outliers. Then, we view the local features of an image as nodes of a graph and propose an adaptive direction graph convolutional (ADGC)layer to pass relation information between nodes. The proposed ADGC layer can automatically suppress the message-passing of meaningless features by dynamically learning di-rection and degree of linkage. When aligning two groups of local features from two images, we view it as a graph matching problem and propose a cross-graph embedded-alignment (CGEA) layer to jointly learn and embed topology information to local features, and straightly predict similarity score. The proposed CGEA layer not only take full use of alignment learned by graph matching but also re-place sensitive one-to-one matching with a robust soft one. Finally, extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed method. Specifically, our framework significantly outperforms state-of-the-art by6.5%mAP scores on Occluded-Duke dataset.
Cutting the Unnecessary Long Tail: Cost-Effective Big Data Clustering in the Cloud
Sep 22, 2019
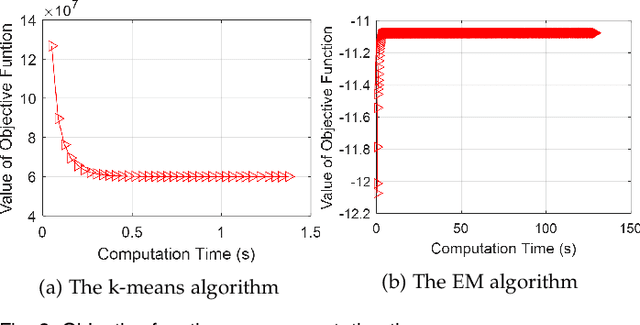

Clustering big data often requires tremendous computational resources where cloud computing is undoubtedly one of the promising solutions. However, the computation cost in the cloud can be unexpectedly high if it cannot be managed properly. The long tail phenomenon has been observed widely in the big data clustering area, which indicates that the majority of time is often consumed in the middle to late stages in the clustering process. In this research, we try to cut the unnecessary long tail in the clustering process to achieve a sufficiently satisfactory accuracy at the lowest possible computation cost. A novel approach is proposed to achieve cost-effective big data clustering in the cloud. By training the regression model with the sampling data, we can make widely used k-means and EM (Expectation-Maximization) algorithms stop automatically at an early point when the desired accuracy is obtained. Experiments are conducted on four popular data sets and the results demonstrate that both k-means and EM algorithms can achieve high cost-effectiveness in the cloud with our proposed approach. For example, in the case studies with the much more efficient k-means algorithm, we find that achieving a 99% accuracy needs only 47.71%-71.14% of the computation cost required for achieving a 100% accuracy while the less efficient EM algorithm needs 16.69%-32.04% of the computation cost. To put that into perspective, in the United States land use classification example, our approach can save up to $94,687.49 for the government in each use.
Comment on "Clustering by fast search and find of density peaks"
Jan 20, 2015
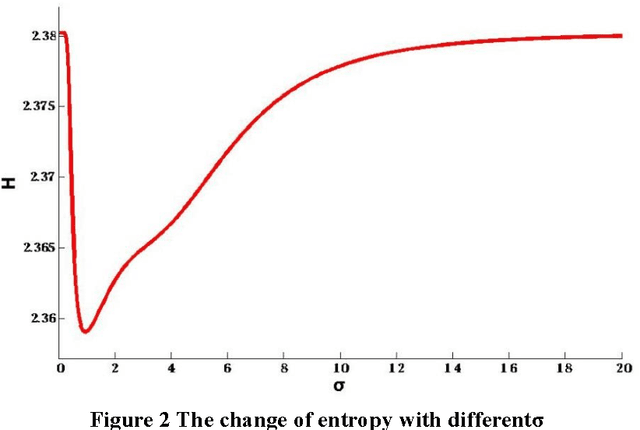

In [1], a clustering algorithm was given to find the centers of clusters quickly. However, the accuracy of this algorithm heavily depend on the threshold value of d-c. Furthermore, [1] has not provided any efficient way to select the threshold value of d-c, that is, one can have to estimate the value of d_c depend on one's subjective experience. In this paper, based on the data field [2], we propose a new way to automatically extract the threshold value of d_c from the original data set by using the potential entropy of data field. For any data set to be clustered, the most reasonable value of d_c can be objectively calculated from the data set by using our proposed method. The same experiments in [1] are redone with our proposed method on the same experimental data set used in [1], the results of which shows that the problem to calculate the threshold value of d_c in [1] has been solved by using our method.