 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutting the Unnecessary Long Tail: Cost-Effective Big Data Clustering in the Cloud
Paper and Code
Sep 22, 2019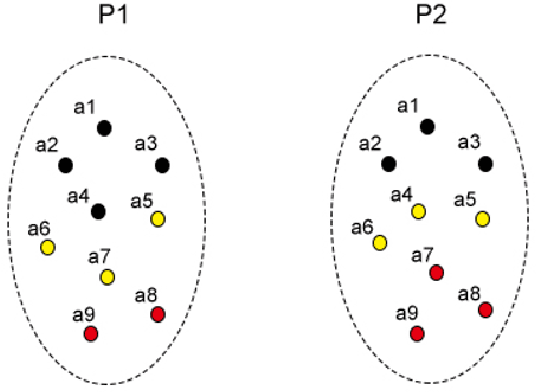
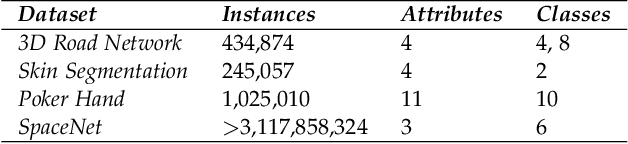
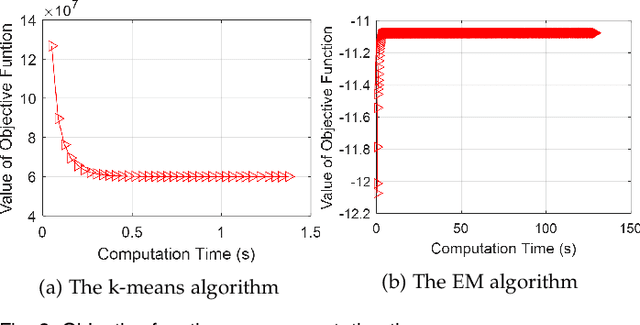

Clustering big data often requires tremendous computational resources where cloud computing is undoubtedly one of the promising solutions. However, the computation cost in the cloud can be unexpectedly high if it cannot be managed properly. The long tail phenomenon has been observed widely in the big data clustering area, which indicates that the majority of time is often consumed in the middle to late stages in the clustering process. In this research, we try to cut the unnecessary long tail in the clustering process to achieve a sufficiently satisfactory accuracy at the lowest possible computation cost. A novel approach is proposed to achieve cost-effective big data clustering in the cloud. By training the regression model with the sampling data, we can make widely used k-means and EM (Expectation-Maximization) algorithms stop automatically at an early point when the desired accuracy is obtained. Experiments are conducted on four popular data sets and the results demonstrate that both k-means and EM algorithms can achieve high cost-effectiveness in the cloud with our proposed approach. For example, in the case studies with the much more efficient k-means algorithm, we find that achieving a 99% accuracy needs only 47.71%-71.14% of the computation cost required for achieving a 100% accuracy while the less efficient EM algorithm needs 16.69%-32.04% of the computation cost. To put that into perspective, in the United States land use classification example, our approach can save up to $94,687.49 for the government in each use.