 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOFT: Test-Time Noise Finetune via Information Bottleneck for Highly Correlated Asset Creation
May 18, 2025The diffusion model has provided a strong tool for implementing text-to-image (T2I) and image-to-image (I2I) generation. Recently, topology and texture control are popular explorations, e.g., ControlNet, IP-Adapter, Ctrl-X, and DSG. These methods explicitly consider high-fidelity controllable editing based on external signals or diffusion feature manipulations. As for diversity, they directly choose different noise latents. However, the diffused noise is capable of implicitly representing the topological and textural manifold of the corresponding image. Moreover, it's an effective workbench to conduct the trade-off between content preservation and controllable variations. Previous T2I and I2I diffusion works do not explore the information within the compressed contextual latent. In this paper, we first propose a plug-and-play noise finetune NOFT module employed by Stable Diffusion to generate highly correlated and diverse images. We fine-tune seed noise or inverse noise through an optimal-transported (OT) information bottleneck (IB) with around only 14K trainable parameters and 10 minutes of training. Our test-time NOFT is good at producing high-fidelity image variations considering topology and texture alignments. Comprehensive experiments demonstrate that NOFT is a powerful general reimagine approach to efficiently fine-tune the 2D/3D AIGC assets with text or image guidance.
SARGes: Semantically Aligned Reliable Gesture Generation via Intent Chain
Mar 26, 2025



Co-speech gesture generation enhances human-computer interaction realism through speech-synchronized gesture synthesis. However, generating semantically meaningful gestures remains a challenging problem. We propose SARGes, a novel framework that leverages large language models (LLMs) to parse speech content and generate reliable semantic gesture labels, which subsequently guide the synthesis of meaningful co-speech gestures.First, we constructed a comprehensive co-speech gesture ethogram and developed an LLM-based intent chain reasoning mechanism that systematically parses and decomposes gesture semantics into structured inference steps following ethogram criteria, effectively guiding LLMs to generate context-aware gesture labels. Subsequently, we constructed an intent chain-annotated text-to-gesture label dataset and trained a lightweight gesture label generation model, which then guides the generation of credible and semantically coherent co-speech gestures. Experimental results demonstrate that SARGes achieves highly semantically-aligned gesture labeling (50.2% accuracy) with efficient single-pass inference (0.4 seconds). The proposed method provides an interpretable intent reasoning pathway for semantic gesture synthesis.
InfoBFR: Real-World Blind Face Restoration via Information Bottleneck
Jan 26, 2025



Blind face restoration (BFR) is a highly challenging problem due to the uncertainty of data degradation patterns. Current BFR methods have realized certain restored productions but with inherent neural degradations that limit real-world generalization in complicated scenarios. In this paper, we propose a plug-and-play framework InfoBFR to tackle neural degradations, e.g., prior bias, topological distortion, textural distortion, and artifact residues, which achieves high-generalization face restoration in diverse wild and heterogeneous scenes. Specifically, based on the results from pre-trained BFR models, InfoBFR considers information compression using manifold information bottleneck (MIB) and information compensation with efficient diffusion LoRA to conduct information optimization. InfoBFR effectively synthesizes high-fidelity faces without attribute and identity distortions. Comprehensive experimental results demonstrate the superiority of InfoBFR over state-of-the-art GAN-based and diffusion-based BFR methods, with around 70ms consumption, 16M trainable parameters, and nearly 85% BFR-boosting. It is promising that InfoBFR will be the first plug-and-play restorer universally employed by diverse BFR models to conquer neural degradations.
DiffMAC: Diffusion Manifold Hallucination Correction for High Generalization Blind Face Restoration
Mar 15, 2024Blind face restoration (BFR) is a highly challenging problem due to the uncertainty of degradation patterns. Current methods have low generalization across photorealistic and heterogeneous domains. In this paper, we propose a Diffusion-Information-Diffusion (DID) framework to tackle diffusion manifold hallucination correction (DiffMAC), which achieves high-generalization face restoration in diverse degraded scenes and heterogeneous domains. Specifically, the first diffusion stage aligns the restored face with spatial feature embedding of the low-quality face based on AdaIN, which synthesizes degradation-removal results but with uncontrollable artifacts for some hard cases. Based on Stage I, Stage II considers information compression using manifold information bottleneck (MIB) and finetunes the first diffusion model to improve facial fidelity. DiffMAC effectively fights against blind degradation patterns and synthesizes high-quality faces with attribute and identity consistencies. Experimental results demonstrate the superiority of DiffMAC over state-of-the-art methods, with a high degree of generalization in real-world and heterogeneous settings. The source code and models will be public.
GesGPT: Speech Gesture Synthesis With Text Parsing from GPT
Mar 23, 2023Gesture synthesis has gained significant attention as a critical research area, focusing on producing contextually appropriate and natural gestures corresponding to speech or textual input. Although deep learning-based approaches have achieved remarkable progress, they often overlook the rich semantic information present in the text, leading to less expressive and meaningful gestures. We propose GesGPT, a novel approach to gesture generation that leverages the semantic analysis capabilities of Large Language Models (LLMs), such as GPT. By capitalizing on the strengths of LLMs for text analysis, we design prompts to extract gesture-related information from textual input. Our method entails developing prompt principles that transform gesture generation into an intention classification problem based on GPT, and utilizing a curated gesture library and integration module to produce semantically rich co-speech gestures. Experimental results demonstrate that GesGPT effectively generates contextually appropriate and expressive gestures, offering a new perspective on semantic co-speech gesture generation.
A Fast Attention Network for Joint Intent Detection and Slot Filling on Edge Devices
May 16, 2022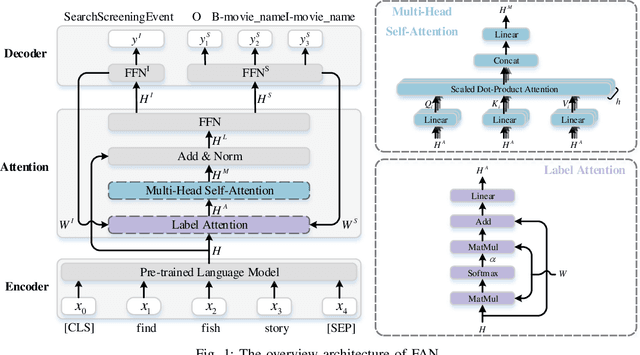



Intent detection and slot filling are two main tasks in natural language understanding and play an essential role in task-oriented dialogue systems. The joint learning of both tasks can improve inference accuracy and is popular in recent works. However, most joint models ignore the inference latency and cannot meet the need to deploy dialogue systems at the edge. In this paper, we propose a Fast Attention Network (FAN) for joint intent detection and slot filling tasks, guaranteeing both accuracy and latency. Specifically, we introduce a clean and parameter-refined attention module to enhance the information exchange between intent and slot, improving semantic accuracy by more than 2%. FAN can be implemented on different encoders and delivers more accurate models at every speed level. Our experiments on the Jetson Nano platform show that FAN inferences fifteen utterances per second with a small accuracy drop, showing its effectiveness and efficiency on edge devices.
Understanding occupants' behaviour, engagement, emotion, and comfort indoors with heterogeneous sensors and wearables
May 14, 2021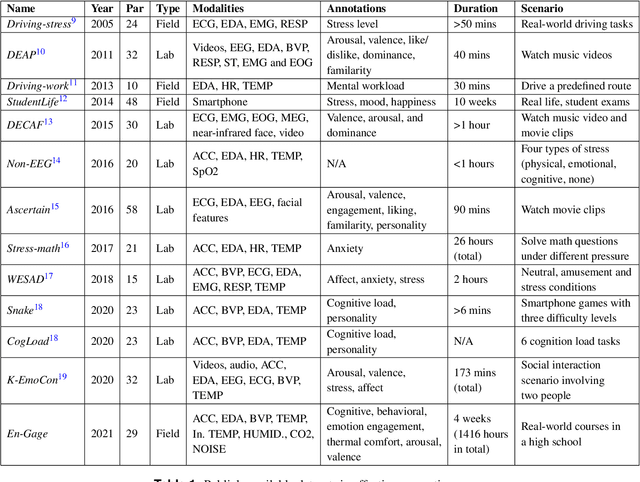

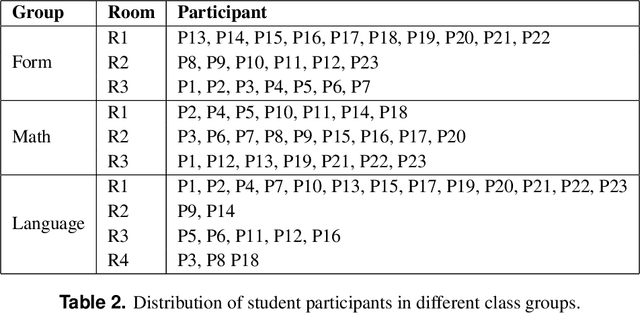
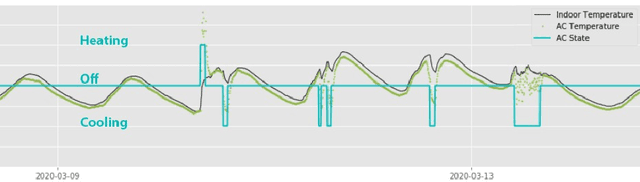
We conducted a field study at a K-12 private school in the suburbs of Melbourne, Australia. The data capture contained two elements: First, a 5-month longitudinal field study In-Gauge using two outdoor weather stations, as well as indoor weather stations in 17 classrooms and temperature sensors on the vents of occupant-controlled room air-conditioners; these were collated into individual datasets for each classroom at a 5-minute logging frequency, including additional data on occupant presence. The dataset was used to derive predictive models of how occupants operate room air-conditioning units. Second, we tracked 23 students and 6 teachers in a 4-week cross-sectional study En-Gage, using wearable sensors to log physiological data, as well as daily surveys to query the occupants' thermal comfort, learning engagement, emotions and seating behaviours. This is the first publicly available dataset studying the daily behaviours and engagement of high school students using heterogeneous methods. The combined data could be used to analyse the relationships between indoor climates and mental states of school students.
Generative Adversarial Networks for Spatio-temporal Data: A Survey
Aug 18, 2020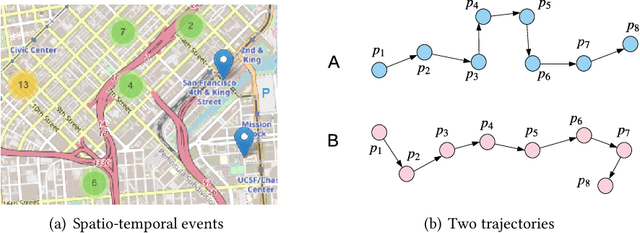
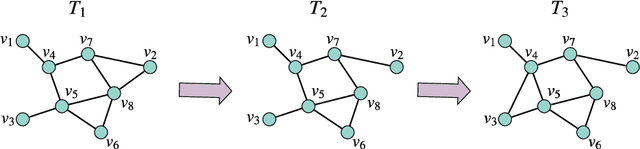
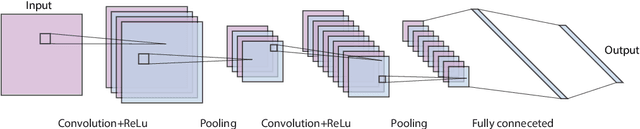
Generative Adversarial Networks (GANs) have shown remarkable success in the computer vision area for producing realistic-looking images. Recently, GAN-based techniques are shown to be promising for spatiotemporal-based applications such as trajectory prediction, events generation and time-series data imputation. While several reviews for GANs in computer vision been presented, nobody has considered addressing the practical applications and challenges relevant to spatio-temporal data. In this paper, we conduct a comprehensive review of the recent developments of GANs in spatio-temporal data. we summarise the popular GAN architectures in spatio-temporal data and common practices for evaluating the performance of spatio-temporal applications with GANs. In the end, we point out the future directions with the hope of benefiting researchers interested in this area.
Overview: Computer vision and machine learning for microstructural characterization and analysis
May 28, 2020
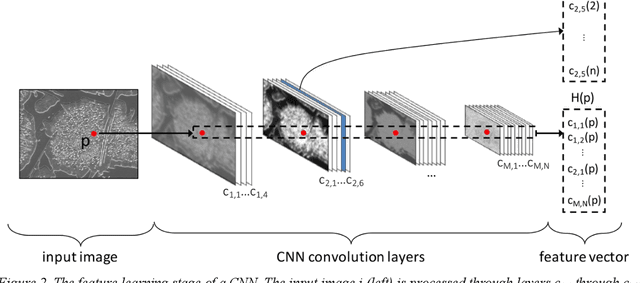


The characterization and analysis of microstructure is the foundation of microstructural science, connecting the materials structure to its composition, process history, and properties. Microstructural quantification traditionally involves a human deciding a priori what to measure and then devising a purpose-built method for doing so. However, recent advances in data science, including computer vision (CV) and machine learning (ML) offer new approaches to extracting information from microstructural images. This overview surveys CV approaches to numerically encode the visual information contained in a microstructural image, which then provides input to supervised or unsupervised ML algorithms that find associations and trends in the high-dimensional image representation. CV/ML systems for microstructural characterization and analysis span the taxonomy of image analysis tasks, including image classification, semantic segmentation, object detection, and instance segmentation. These tools enable new approaches to microstructural analysis, including the development of new, rich visual metrics and the discovery of processing-microstructure-property relationships.
Transfer Learning for Thermal Comfort Prediction in Multiple Cities
Apr 29, 2020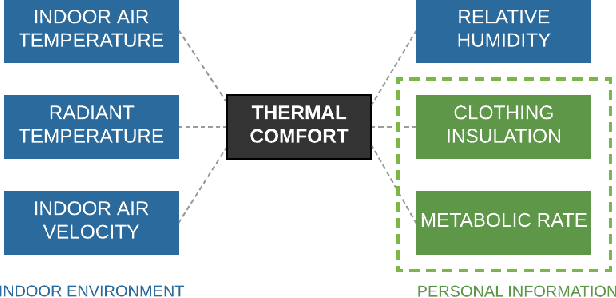
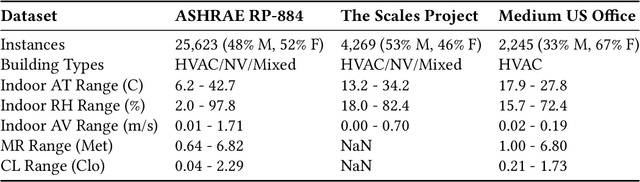
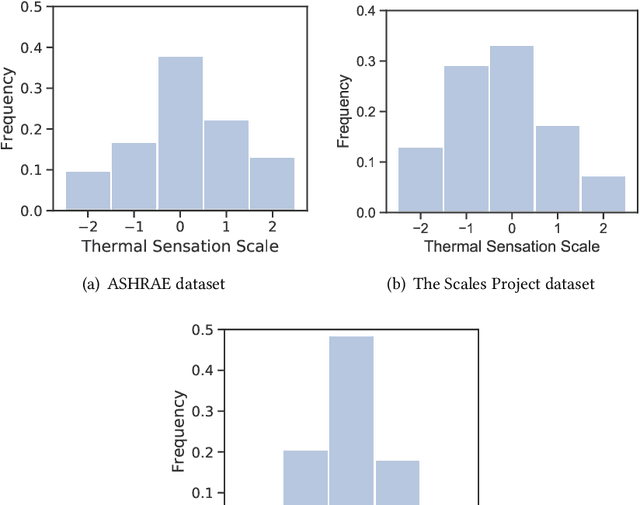
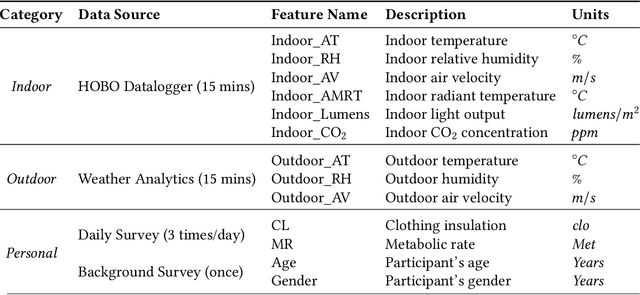
HVAC (Heating, Ventilation and Air Conditioning) system is an important part of a building, which constitutes up to 40% of building energy usage. The main purpose of HVAC, maintaining appropriate thermal comfort, is crucial for the best utilisation of energy usage. Besides, thermal comfort is also crucial for well-being, health, and work productivity. Recently, data-driven thermal comfort models have got better performance than traditional knowledge-based methods (e.g. Predicted Mean Vote Model). An accurate thermal comfort model requires a large amount of self-reported thermal comfort data from indoor occupants which undoubtedly remains a challenge for researchers. In this research, we aim to tackle this data-shortage problem and boost the performance of thermal comfort prediction. We utilise sensor data from multiple cities in the same climate zone to learn thermal comfort patterns. We present a transfer learning based multilayer perceptron model from the same climate zone (TL-MLP-C*) for accurate thermal comfort prediction. Extensive experimental results on ASHRAE RP-884, the Scales Project and Medium US Office datasets show that the performance of the proposed TL-MLP-C* exceeds the state-of-the-art methods in accuracy, precision and F1-score.