 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-Valued Optimism is Matrix-Valued Augmentation: Additive Hybrid Designs for Constrained Optimization
May 07, 2026Augmented Lagrangian and optimistic primal--dual methods stabilize equality-constrained optimization through seemingly different mechanisms: the former adds constraint-dependent primal curvature, while the latter adds dual memory. Recent work has shown that these mechanisms are equivalent for scalar parameters. We extend this equivalence to matrix-valued correction. We prove an additivity principle: for symmetric matrix parameters, the ideal primal trajectory depends only on the summed correction matrix, not on how it is split between augmented and optimistic channels. This exposes a design freedom: algebraically equivalent decompositions can have different finite-step feasibility because augmented correction affects primal curvature, whereas optimistic correction affects the scale of the dual memory correction. We formulate the resulting step-size-limited design problem and derive a closed-form hybrid rule that selects a matrix correction, splits it between the two channels, and chooses primal and dual steps using local spectral weights. Experiments on nonlinear equality-constrained problems with controlled constraint-Jacobian conditioning show that the hybrid design improves over pure augmented and pure optimistic endpoints, closely tracks a grid-search hybrid oracle, and is competitive with first-order primal--dual baselines under mild-to-moderate ill-conditioning. The experiments also identify the expected limitation: exact cancellation requires increasingly large matrix corrections as the constraint Jacobian becomes ill-conditioned.
ComPASS: Towards Personalized Agentic Social Support via Tool-Augmented Companionship
Apr 20, 2026Developing compassionate interactive systems requires agents to not only understand user emotions but also provide diverse, substantive support. While recent works explore empathetic dialogue generation, they remain limited in response form and content, struggling to satisfy diverse needs across users and contexts. To address this, we explore empowering agents with external tools to execute diverse actions. Grounded in the psychological concept of "social support", this paradigm delivers substantive, human-like companionship. Specifically, we first design a dozen user-centric tools simulating various multimedia applications, which can cover different types of social support behaviors in human-agent interaction scenarios. We then construct ComPASS-Bench, the first personalized social support benchmark for LLM-based agents, via multi-step automated synthesis and manual refinement. Based on ComPASS-Bench, we further synthesize tool use records to fine-tune the Qwen3-8B model, yielding a task-specific ComPASS-Qwen. Comprehensive evaluations across two settings reveal that while the evaluated LLMs can generate valid tool-calling requests with high success rates, significant gaps remain in final response quality. Moreover, tool-augmented responses achieve better overall performance than directly producing conversational empathy. Notably, our trained ComPASS-Qwen demonstrates substantial improvements over its base model, achieving comparable performance to several large-scale models. Our code and data are available at https://github.com/hzp3517/ComPASS.
CloudMatch: Weak-to-Strong Consistency Learning for Semi-Supervised Cloud Detection
Jan 07, 2026Due to the high cost of annotating accurate pixel-level labels, semi-supervised learning has emerged as a promising approach for cloud detection. In this paper, we propose CloudMatch, a semi-supervised framework that effectively leverages unlabeled remote sensing imagery through view-consistency learning combined with scene-mixing augmentations. An observation behind CloudMatch is that cloud patterns exhibit structural diversity and contextual variability across different scenes and within the same scene category. Our key insight is that enforcing prediction consistency across diversely augmented views, incorporating both inter-scene and intra-scene mixing, enables the model to capture the structural diversity and contextual richness of cloud patterns. Specifically, CloudMatch generates one weakly augmented view along with two complementary strongly augmented views for each unlabeled image: one integrates inter-scene patches to simulate contextual variety, while the other employs intra-scene mixing to preserve semantic coherence. This approach guides pseudolabel generation and enhances generalization. Extensive experiments show that CloudMatch achieves good performance, demonstrating its capability to utilize unlabeled data efficiently and advance semi-supervised cloud detection.
DriveExplorer: Images-Only Decoupled 4D Reconstruction with Progressive Restoration for Driving View Extrapolation
Dec 30, 2025This paper presents an effective solution for view extrapolation in autonomous driving scenarios. Recent approaches focus on generating shifted novel view images from given viewpoints using diffusion models. However, these methods heavily rely on priors such as LiDAR point clouds, 3D bounding boxes, and lane annotations, which demand expensive sensors or labor-intensive labeling, limiting applicability in real-world deployment. In this work, with only images and optional camera poses, we first estimate a global static point cloud and per-frame dynamic point clouds, fusing them into a unified representation. We then employ a deformable 4D Gaussian framework to reconstruct the scene. The initially trained 4D Gaussian model renders degraded and pseudo-images to train a video diffusion model. Subsequently, progressively shifted Gaussian renderings are iteratively refined by the diffusion model,and the enhanced results are incorporated back as training data for 4DGS. This process continues until extrapolation reaches the target viewpoints. Compared with baselines, our method produces higher-quality images at novel extrapolated viewpoints.
CD-Mamba: Cloud detection with long-range spatial dependency modeling
Sep 05, 2025
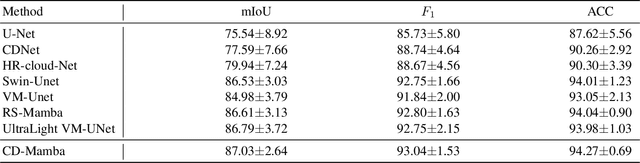
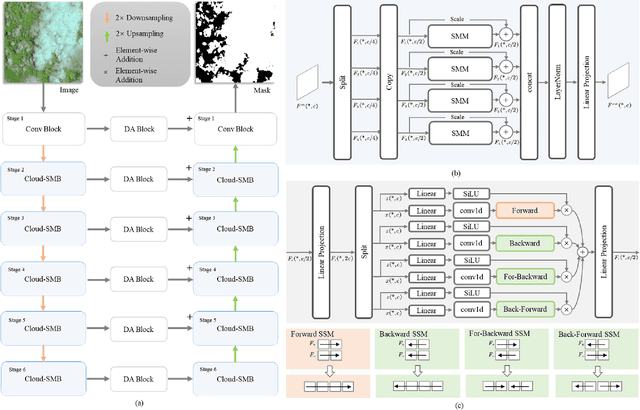
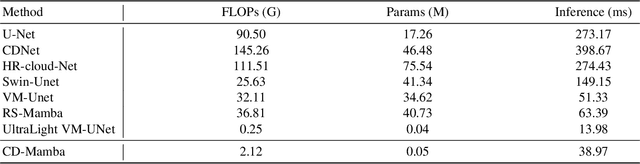
Remote sensing images are frequently obscured by cloud cover, posing significant challenges to data integrity and reliability. Effective cloud detection requires addressing both short-range spatial redundancies and long-range atmospheric similarities among cloud patches. Convolutional neural networks are effective at capturing local spatial dependencies, while Mamba has strong capabilities in modeling long-range dependencies. To fully leverage both local spatial relations and long-range dependencies, we propose CD-Mamba, a hybrid model that integrates convolution and Mamba's state-space modeling into a unified cloud detection network. CD-Mamba is designed to comprehensively capture pixelwise textural details and long term patchwise dependencies for cloud detection. This design enables CD-Mamba to manage both pixel-wise interactions and extensive patch-wise dependencies simultaneously, improving detection accuracy across diverse spatial scales. Extensive experiments validate the effectiveness of CD-Mamba and demonstrate its superior performance over existing methods.
MotionPRO: Exploring the Role of Pressure in Human MoCap and Beyond
Apr 07, 2025Existing human Motion Capture (MoCap) methods mostly focus on the visual similarity while neglecting the physical plausibility. As a result, downstream tasks such as driving virtual human in 3D scene or humanoid robots in real world suffer from issues such as timing drift and jitter, spatial problems like sliding and penetration, and poor global trajectory accuracy. In this paper, we revisit human MoCap from the perspective of interaction between human body and physical world by exploring the role of pressure. Firstly, we construct a large-scale human Motion capture dataset with Pressure, RGB and Optical sensors (named MotionPRO), which comprises 70 volunteers performing 400 types of motion, encompassing a total of 12.4M pose frames. Secondly, we examine both the necessity and effectiveness of the pressure signal through two challenging tasks: (1) pose and trajectory estimation based solely on pressure: We propose a network that incorporates a small kernel decoder and a long-short-term attention module, and proof that pressure could provide accurate global trajectory and plausible lower body pose. (2) pose and trajectory estimation by fusing pressure and RGB: We impose constraints on orthographic similarity along the camera axis and whole-body contact along the vertical axis to enhance the cross-attention strategy to fuse pressure and RGB feature maps. Experiments demonstrate that fusing pressure with RGB features not only significantly improves performance in terms of objective metrics, but also plausibly drives virtual humans (SMPL) in 3D scene. Furthermore, we demonstrate that incorporating physical perception enables humanoid robots to perform more precise and stable actions, which is highly beneficial for the development of embodied artificial intelligence. Project page is available at: https://nju-cite-mocaphumanoid.github.io/MotionPRO/
SARGes: Semantically Aligned Reliable Gesture Generation via Intent Chain
Mar 26, 2025



Co-speech gesture generation enhances human-computer interaction realism through speech-synchronized gesture synthesis. However, generating semantically meaningful gestures remains a challenging problem. We propose SARGes, a novel framework that leverages large language models (LLMs) to parse speech content and generate reliable semantic gesture labels, which subsequently guide the synthesis of meaningful co-speech gestures.First, we constructed a comprehensive co-speech gesture ethogram and developed an LLM-based intent chain reasoning mechanism that systematically parses and decomposes gesture semantics into structured inference steps following ethogram criteria, effectively guiding LLMs to generate context-aware gesture labels. Subsequently, we constructed an intent chain-annotated text-to-gesture label dataset and trained a lightweight gesture label generation model, which then guides the generation of credible and semantically coherent co-speech gestures. Experimental results demonstrate that SARGes achieves highly semantically-aligned gesture labeling (50.2% accuracy) with efficient single-pass inference (0.4 seconds). The proposed method provides an interpretable intent reasoning pathway for semantic gesture synthesis.
Unveiling the Potential of Segment Anything Model 2 for RGB-Thermal Semantic Segmentation with Language Guidance
Mar 04, 2025The perception capability of robotic systems relies on the richness of the dataset. Although Segment Anything Model 2 (SAM2), trained on large datasets, demonstrates strong perception potential in perception tasks, its inherent training paradigm prevents it from being suitable for RGB-T tasks. To address these challenges, we propose SHIFNet, a novel SAM2-driven Hybrid Interaction Paradigm that unlocks the potential of SAM2 with linguistic guidance for efficient RGB-Thermal perception. Our framework consists of two key components: (1) Semantic-Aware Cross-modal Fusion (SACF) module that dynamically balances modality contributions through text-guided affinity learning, overcoming SAM2's inherent RGB bias; (2) Heterogeneous Prompting Decoder (HPD) that enhances global semantic information through a semantic enhancement module and then combined with category embeddings to amplify cross-modal semantic consistency. With 32.27M trainable parameters, SHIFNet achieves state-of-the-art segmentation performance on public benchmarks, reaching 89.8% on PST900 and 67.8% on FMB, respectively. The framework facilitates the adaptation of pre-trained large models to RGB-T segmentation tasks, effectively mitigating the high costs associated with data collection while endowing robotic systems with comprehensive perception capabilities. The source code will be made publicly available at https://github.com/iAsakiT3T/SHIFNet.
Motion Generation Review: Exploring Deep Learning for Lifelike Animation with Manifold
Dec 12, 2024

Human motion generation involves creating natural sequences of human body poses, widely used in gaming, virtual reality, and human-computer interaction. It aims to produce lifelike virtual characters with realistic movements, enhancing virtual agents and immersive experiences. While previous work has focused on motion generation based on signals like movement, music, text, or scene background, the complexity of human motion and its relationships with these signals often results in unsatisfactory outputs. Manifold learning offers a solution by reducing data dimensionality and capturing subspaces of effective motion. In this review, we present a comprehensive overview of manifold applications in human motion generation, one of the first in this domain. We explore methods for extracting manifolds from unstructured data, their application in motion generation, and discuss their advantages and future directions. This survey aims to provide a broad perspective on the field and stimulate new approaches to ongoing challenges.
Residual Attention Single-Head Vision Transformer Network for Rolling Bearing Fault Diagnosis in Noisy Environments
Nov 27, 2024



Rolling bearings play a crucial role in industrial machinery, directly influencing equipment performance, durability, and safety. However, harsh operating conditions, such as high speeds and temperatures, often lead to bearing malfunctions, resulting in downtime, economic losses, and safety hazards. This paper proposes the Residual Attention Single-Head Vision Transformer Network (RA-SHViT-Net) for fault diagnosis in rolling bearings. Vibration signals are transformed from the time to frequency domain using the Fast Fourier Transform (FFT) before being processed by RA-SHViT-Net. The model employs the Single-Head Vision Transformer (SHViT) to capture local and global features, balancing computational efficiency and predictive accuracy. To enhance feature extraction, the Adaptive Hybrid Attention Block (AHAB) integrates channel and spatial attention mechanisms. The network architecture includes Depthwise Convolution, Single-Head Self-Attention, Residual Feed-Forward Networks (Res-FFN), and AHAB modules, ensuring robust feature representation and mitigating gradient vanishing issues. Evaluation on the Case Western Reserve University and Paderborn University datasets demonstrates the RA-SHViT-Net's superior accuracy and robustness in complex, noisy environments. Ablation studies further validate the contributions of individual components, establishing RA-SHViT-Net as an effective tool for early fault detection and classification, promoting efficient maintenance strategies in industrial settings. Keywords: rolling bearings, fault diagnosis, Vision Transformer, attention mechanism, noisy environments, Fast Fourier Transform (FFT)