 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACON: Training Text-to-Image Model from Uncurated Data
Mar 27, 2026The success of modern text-to-image generation is largely attributed to massive, high-quality datasets. Currently, these datasets are curated through a filter-first paradigm that aggressively discards low-quality raw data based on the assumption that it is detrimental to model performance. Is the discarded bad data truly useless, or does it hold untapped potential? In this work, we critically re-examine this question. We propose LACON (Labeling-and-Conditioning), a novel training framework that exploits the underlying uncurated data distribution. Instead of filtering, LACON re-purposes quality signals, such as aesthetic scores and watermark probabilities as explicit, quantitative condition labels. The generative model is then trained to learn the full spectrum of data quality, from bad to good. By learning the explicit boundary between high- and low-quality content, LACON achieves superior generation quality compared to baselines trained only on filtered data using the same compute budget, proving the significant value of uncurated data.
Make Tracking Easy: Neural Motion Retargeting for Humanoid Whole-body Control
Mar 23, 2026Humanoid robots require diverse motor skills to integrate into complex environments, but bridging the kinematic and dynamic embodiment gap from human data remains a major bottleneck. We demonstrate through Hessian analysis that traditional optimization-based retargeting is inherently non-convex and prone to local optima, leading to physical artifacts like joint jumps and self-penetration. To address this, we reformulate the targeting problem as learning data distribution rather than optimizing optimal solutions, where we propose NMR, a Neural Motion Retargeting framework that transforms static geometric mapping into a dynamics-aware learned process. We first propose Clustered-Expert Physics Refinement (CEPR), a hierarchical data pipeline that leverages VAE-based motion clustering to group heterogeneous movements into latent motifs. This strategy significantly reduces the computational overhead of massively parallel reinforcement learning experts, which project and repair noisy human demonstrations onto the robot's feasible motion manifold. The resulting high-fidelity data supervises a non-autoregressive CNN-Transformer architecture that reasons over global temporal context to suppress reconstruction noise and bypass geometric traps. Experiments on the Unitree G1 humanoid across diverse dynamic tasks (e.g., martial arts, dancing) show that NMR eliminates joint jumps and significantly reduces self-collisions compared to state-of-the-art baselines. Furthermore, NMR-generated references accelerate the convergence of downstream whole-body control policies, establishing a scalable path for bridging the human-robot embodiment gap.
PEAfowl: Perception-Enhanced Multi-View Vision-Language-Action for Bimanual Manipulation
Jan 25, 2026Bimanual manipulation in cluttered scenes requires policies that remain stable under occlusions, viewpoint and scene variations. Existing vision-language-action models often fail to generalize because (i) multi-view features are fused via view-agnostic token concatenation, yielding weak 3D-consistent spatial understanding, and (ii) language is injected as global conditioning, resulting in coarse instruction grounding. In this paper, we introduce PEAfowl, a perception-enhanced multi-view VLA policy for bimanual manipulation. For spatial reasoning, PEAfowl predicts per-token depth distributions, performs differentiable 3D lifting, and aggregates local cross-view neighbors to form geometrically grounded, cross-view consistent representations. For instruction grounding, we propose to replace global conditioning with a Perceiver-style text-aware readout over frozen CLIP visual features, enabling iterative evidence accumulation. To overcome noisy and incomplete commodity depth without adding inference overhead, we apply training-only depth distillation from a pretrained depth teacher to supervise the depth-distribution head, providing perception front-end with geometry-aware priors. On RoboTwin 2.0 under domain-randomized setting, PEAfowl improves the strongest baseline by 23.0 pp in success rate, and real-robot experiments further demonstrate reliable sim-to-real transfer and consistent improvements from depth distillation. Project website: https://peafowlvla.github.io/.
Split-Layer: Enhancing Implicit Neural Representation by Maximizing the Dimensionality of Feature Space
Nov 13, 2025Implicit neural representation (INR) models signals as continuous functions using neural networks, offering efficient and differentiable optimization for inverse problems across diverse disciplines. However, the representational capacity of INR defined by the range of functions the neural network can characterize, is inherently limited by the low-dimensional feature space in conventional multilayer perceptron (MLP) architectures. While widening the MLP can linearly increase feature space dimensionality, it also leads to a quadratic growth in computational and memory costs. To address this limitation, we propose the split-layer, a novel reformulation of MLP construction. The split-layer divides each layer into multiple parallel branches and integrates their outputs via Hadamard product, effectively constructing a high-degree polynomial space. This approach significantly enhances INR's representational capacity by expanding the feature space dimensionality without incurring prohibitive computational overhead. Extensive experiments demonstrate that the split-layer substantially improves INR performance, surpassing existing methods across multiple tasks, including 2D image fitting, 2D CT reconstruction, 3D shape representation, and 5D novel view synthesis.
Pressure2Motion: Hierarchical Motion Synthesis from Ground Pressure with Text Guidance
Nov 07, 2025We present Pressure2Motion, a novel motion capture algorithm that synthesizes human motion from a ground pressure sequence and text prompt. It eliminates the need for specialized lighting setups, cameras, or wearable devices, making it suitable for privacy-preserving, low-light, and low-cost motion capture scenarios. Such a task is severely ill-posed due to the indeterminate nature of the pressure signals to full-body motion. To address this issue, we introduce Pressure2Motion, a generative model that leverages pressure features as input and utilizes a text prompt as a high-level guiding constraint. Specifically, our model utilizes a dual-level feature extractor that accurately interprets pressure data, followed by a hierarchical diffusion model that discerns broad-scale movement trajectories and subtle posture adjustments. Both the physical cues gained from the pressure sequence and the semantic guidance derived from descriptive texts are leveraged to guide the motion generation with precision. To the best of our knowledge, Pressure2Motion is a pioneering work in leveraging both pressure data and linguistic priors for motion generation, and the established MPL benchmark is the first benchmark for this task. Experiments show our method generates high-fidelity, physically plausible motions, establishing a new state-of-the-art for this task. The codes and benchmarks will be publicly released upon publication.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025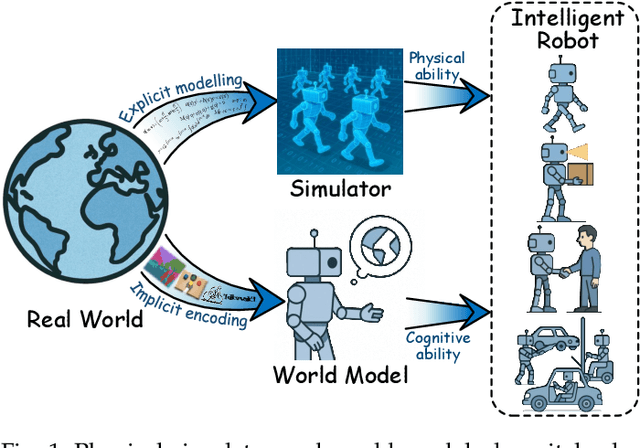
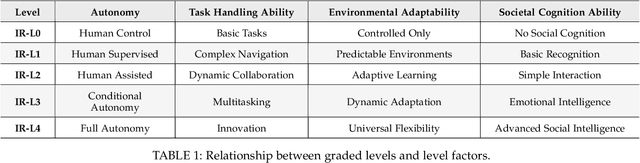
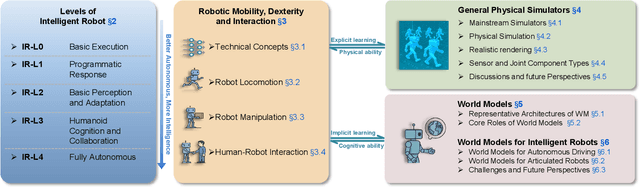

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
MotionPRO: Exploring the Role of Pressure in Human MoCap and Beyond
Apr 07, 2025Existing human Motion Capture (MoCap) methods mostly focus on the visual similarity while neglecting the physical plausibility. As a result, downstream tasks such as driving virtual human in 3D scene or humanoid robots in real world suffer from issues such as timing drift and jitter, spatial problems like sliding and penetration, and poor global trajectory accuracy. In this paper, we revisit human MoCap from the perspective of interaction between human body and physical world by exploring the role of pressure. Firstly, we construct a large-scale human Motion capture dataset with Pressure, RGB and Optical sensors (named MotionPRO), which comprises 70 volunteers performing 400 types of motion, encompassing a total of 12.4M pose frames. Secondly, we examine both the necessity and effectiveness of the pressure signal through two challenging tasks: (1) pose and trajectory estimation based solely on pressure: We propose a network that incorporates a small kernel decoder and a long-short-term attention module, and proof that pressure could provide accurate global trajectory and plausible lower body pose. (2) pose and trajectory estimation by fusing pressure and RGB: We impose constraints on orthographic similarity along the camera axis and whole-body contact along the vertical axis to enhance the cross-attention strategy to fuse pressure and RGB feature maps. Experiments demonstrate that fusing pressure with RGB features not only significantly improves performance in terms of objective metrics, but also plausibly drives virtual humans (SMPL) in 3D scene. Furthermore, we demonstrate that incorporating physical perception enables humanoid robots to perform more precise and stable actions, which is highly beneficial for the development of embodied artificial intelligence. Project page is available at: https://nju-cite-mocaphumanoid.github.io/MotionPRO/
Gaseous Object Detection
Feb 18, 2025



Object detection, a fundamental and challenging problem in computer vision, has experienced rapid development due to the effectiveness of deep learning. The current objects to be detected are mostly rigid solid substances with apparent and distinct visual characteristics. In this paper, we endeavor on a scarcely explored task named Gaseous Object Detection (GOD), which is undertaken to explore whether the object detection techniques can be extended from solid substances to gaseous substances. Nevertheless, the gas exhibits significantly different visual characteristics: 1) saliency deficiency, 2) arbitrary and ever-changing shapes, 3) lack of distinct boundaries. To facilitate the study on this challenging task, we construct a GOD-Video dataset comprising 600 videos (141,017 frames) that cover various attributes with multiple types of gases. A comprehensive benchmark is established based on this dataset, allowing for a rigorous evaluation of frame-level and video-level detectors. Deduced from the Gaussian dispersion model, the physics-inspired Voxel Shift Field (VSF) is designed to model geometric irregularities and ever-changing shapes in potential 3D space. By integrating VSF into Faster RCNN, the VSF RCNN serves as a simple but strong baseline for gaseous object detection. Our work aims to attract further research into this valuable albeit challenging area.
Towards the Spectral bias Alleviation by Normalizations in Coordinate Networks
Jul 25, 2024



Representing signals using coordinate networks dominates the area of inverse problems recently, and is widely applied in various scientific computing tasks. Still, there exists an issue of spectral bias in coordinate networks, limiting the capacity to learn high-frequency components. This problem is caused by the pathological distribution of the neural tangent kernel's (NTK's) eigenvalues of coordinate networks. We find that, this pathological distribution could be improved using classical normalization techniques (batch normalization and layer normalization), which are commonly used in convolutional neural networks but rarely used in coordinate networks. We prove that normalization techniques greatly reduces the maximum and variance of NTK's eigenvalues while slightly modifies the mean value, considering the max eigenvalue is much larger than the most, this variance change results in a shift of eigenvalues' distribution from a lower one to a higher one, therefore the spectral bias could be alleviated. Furthermore, we propose two new normalization techniques by combining these two techniques in different ways. The efficacy of these normalization techniques is substantiated by the significant improvements and new state-of-the-arts achieved by applying normalization-based coordinate networks to various tasks, including the image compression, computed tomography reconstruction, shape representation, magnetic resonance imaging, novel view synthesis and multi-view stereo reconstruction.
Joint RGB-Spectral Decomposition Model Guided Image Enhancement in Mobile Photography
Jul 25, 2024



The integration of miniaturized spectrometers into mobile devices offers new avenues for image quality enhancement and facilitates novel downstream tasks. However, the broader application of spectral sensors in mobile photography is hindered by the inherent complexity of spectral images and the constraints of spectral imaging capabilities. To overcome these challenges, we propose a joint RGB-Spectral decomposition model guided enhancement framework, which consists of two steps: joint decomposition and prior-guided enhancement. Firstly, we leverage the complementarity between RGB and Low-resolution Multi-Spectral Images (Lr-MSI) to predict shading, reflectance, and material semantic priors. Subsequently, these priors are seamlessly integrated into the established HDRNet to promote dynamic range enhancement, color mapping, and grid expert learning, respectively. Additionally, we construct a high-quality Mobile-Spec dataset to support our research, and our experiments validate the effectiveness of Lr-MSI in the tone enhancement task. This work aims to establish a solid foundation for advancing spectral vision in mobile photography. The code is available at \url{https://github.com/CalayZhou/JDM-HDRNet}.